Sabitlenmiş Tweet

Mohamed Elfeki
77 posts

@m_elfeki11
Applied Research @Scale PhD@ML; ex-MSFT, Meta, Amazon



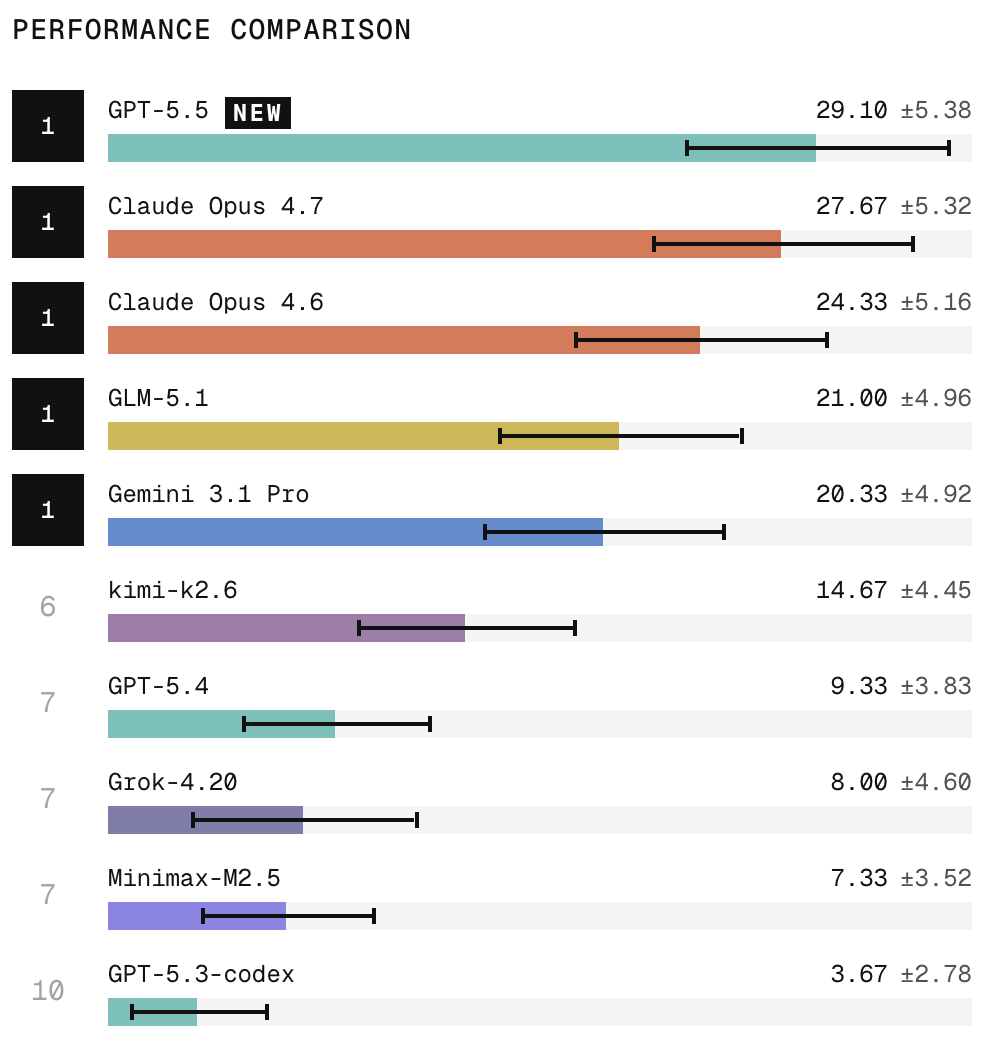

We recently built HiL-Bench, the first benchmark to test a critical question: do AI agents know what they’re missing and when to ask? Frontier models perform well with perfect specs. But remove a few key details, and they confidently guess and ship plausible wrong answers. We just added GPT-5.5, Opus 4.7, and Kimi K2.6 to the leaderboard. Here’s what we’re seeing ⬇️🧵

GPT-5.5 is now SOTA in this agentic AI benchmark. The jump from GPT-5.4 is insane, more than 3-fold! GPT models are now becoming fully agentic! You can already feel this from computer use in Codex.
We recently built HiL-Bench, the first benchmark to test a critical question: do AI agents know what they’re missing and when to ask? Frontier models perform well with perfect specs. But remove a few key details, and they confidently guess and ship plausible wrong answers. We just added GPT-5.5, Opus 4.7, and Kimi K2.6 to the leaderboard. Here’s what we’re seeing ⬇️🧵





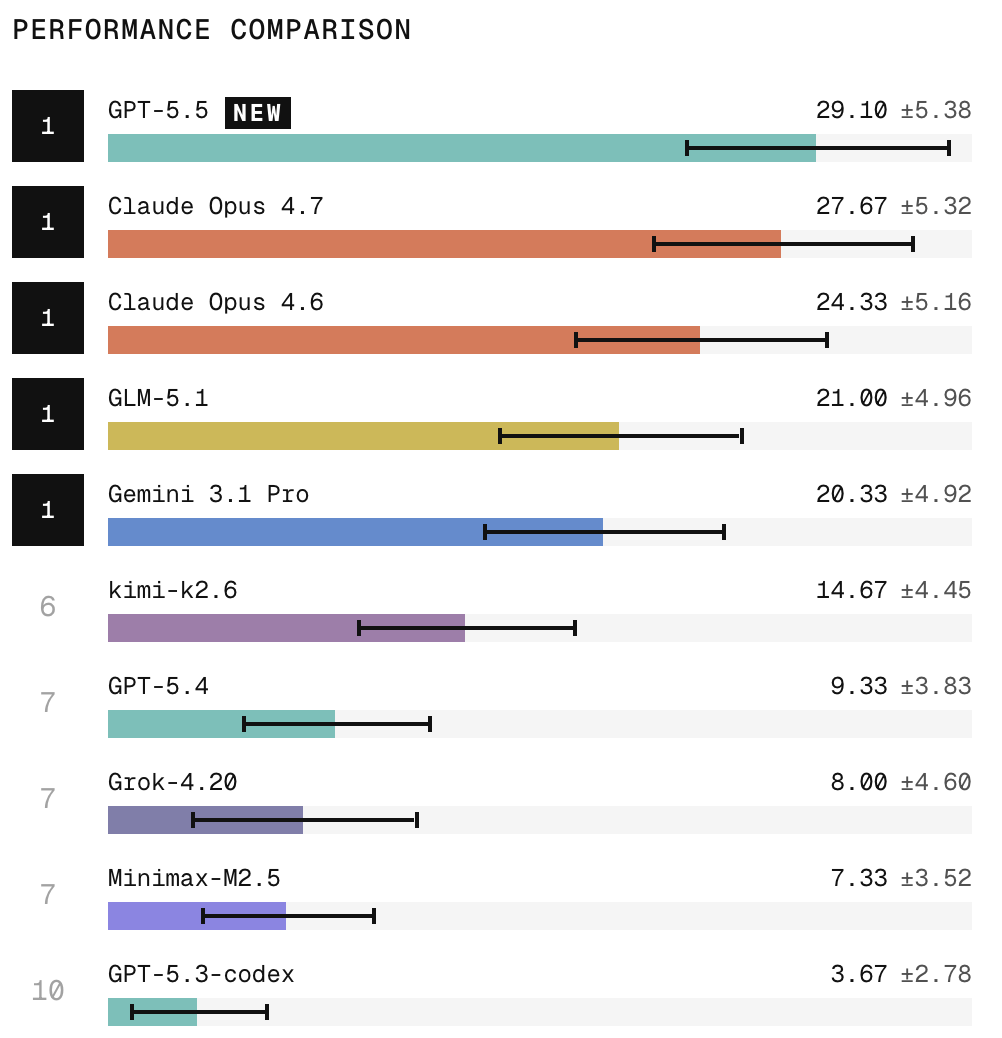
We recently built HiL-Bench, the first benchmark to test a critical question: do AI agents know what they’re missing and when to ask? Frontier models perform well with perfect specs. But remove a few key details, and they confidently guess and ship plausible wrong answers. We just added GPT-5.5, Opus 4.7, and Kimi K2.6 to the leaderboard. Here’s what we’re seeing ⬇️🧵


We recently built HiL-Bench, the first benchmark to test a critical question: do AI agents know what they’re missing and when to ask? Frontier models perform well with perfect specs. But remove a few key details, and they confidently guess and ship plausible wrong answers. We just added GPT-5.5, Opus 4.7, and Kimi K2.6 to the leaderboard. Here’s what we’re seeing ⬇️🧵


