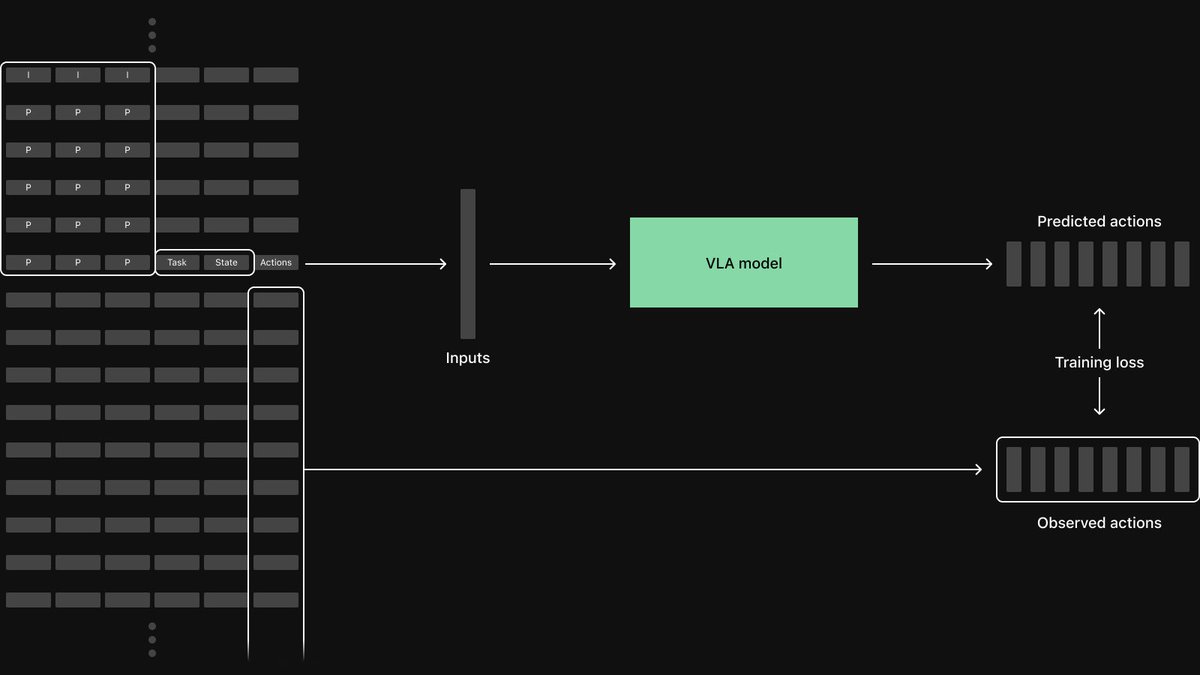
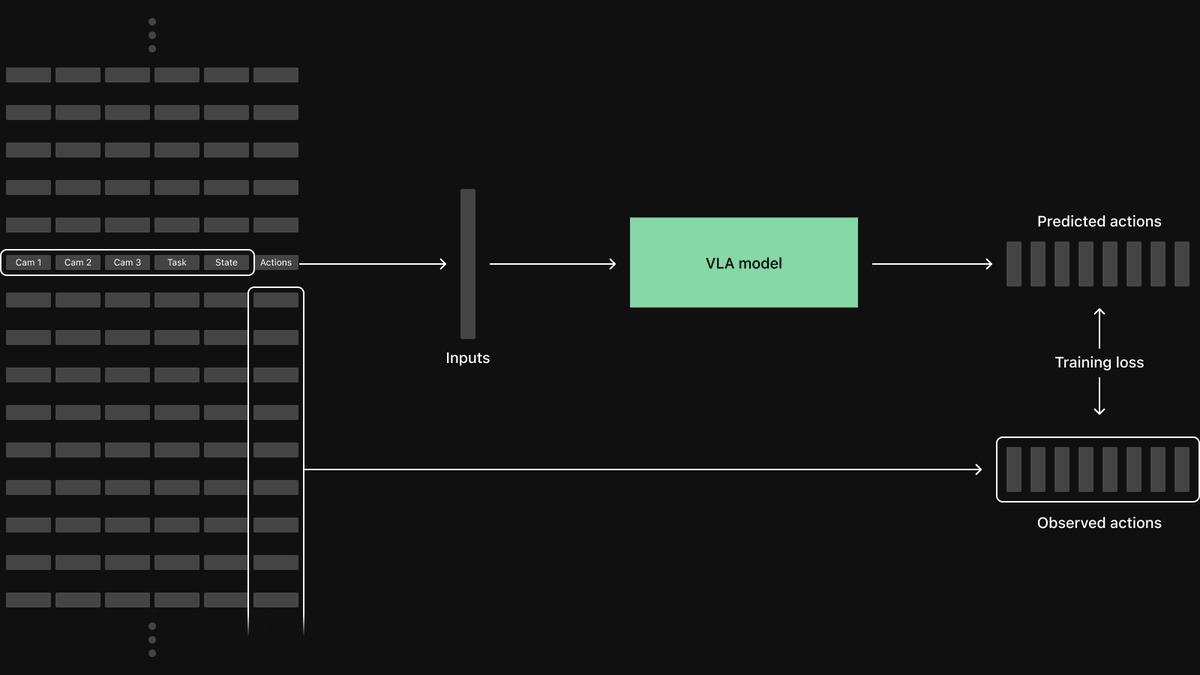
As I alluded to in the previous post, I've given egoexo-forge datasets the same @rerundotio OSS server treatment! To start, I ingested 10 samples from each of the following datasets before scaling: 1. Assembly101 2. HOCap 3. HOT3D-Aria 4. Ego-Dex 5. Aria-Gen2 (new!) 6. HOT3D-Quest3 7. Umetrack All follow a standardized format that is easily queryable. This means I can do things like: "Find all frames where hand keypoints exist in camera view 2 but not view 1" "Filter to samples where the hand keypoint velocity is > 0.5 m/s" Across all of the ingested datasets. Still a preview, and I'll have more to share with a super exciting release that is coming soon. I'll be adding a bunch more datasets and releasing the code after the release, so stay tuned!