Sabitlenmiş Tweet
Stefano
1.6K posts


Stefano
@maeste
Code climber - no problem with strong opinions - https://t.co/mU1It6LAKI - https://t.co/wslalil0Wo -
Cremona, Lombardia Katılım Ekim 2008
354 Takip Edilen365 Takipçiler


Exactly, I found myself for the first time *ever* to talk to a model that can run on my Computer about the random things you could ask to Claude. Like history and other stuff. I also did a benchmark on Italian historical facts wth Qwen 27B vs DeepSeek v4 Flash 2 bit quants (continue)
Armin Ronacher ⇌@mitsuhiko
A nice thing about DeepSeek V4 Flash locally is that it’s a big enough model that you can have it explain shit to you and it won’t completely lie to you. Tried to walk through some choices in ds4.c and I felt pretty good about the experience.
English
@antirez Possibly, even if it sounds strange if what I remember is correct: flash is a policy distillation of the pro (just from. Top of my head, need to check). And if it is the pure RL should happen only on the big one and distilled to flush. So theory is 50% as well, or even a bit less
English

My Mac had less available memory than I expected, turned out the "claude" Claude Code processes on this machine (running in various terminal windows) were consuming ~30GB on their own!
The largest one was using 4.9GB
English
This is another great use case for lince.sh:
spawn your agent(s) with "n" -> close them as soon as they finish the task with "x" -> spawn a new one with "n" -> repeat.
Keep focus: all in milliseconds in the same terminal
Save memory, work w/ any agent, sandboxed
Simon Willison@simonw
My Mac had less available memory than I expected, turned out the "claude" Claude Code processes on this machine (running in various terminal windows) were consuming ~30GB on their own! The largest one was using 4.9GB
English
Stefano retweetledi

With the model's simultaneous speech capability, Horace has gotten a lot easier to work with recently.
English
Wow if you seriously tried voice mode with any SOTA model...you probably get how this video is mind-blowing. The live translation is impressive.
Mira Murati@miramurati
Today we're sharing our work on interaction models. A new class of model trained from scratch to handle real-time interaction natively, instead of gluing it onto a turn-based one. youtu.be/A12AVongNN4
English
@karpathy @trq212 Html is good for output, I think md is better atm when you communicate with llm and both llm and human need to write the doc. To consume output html is better, depend on the device, a screenshot of the rendered html is better. Hermes decided to send as hit on the phone yesterday
English

This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc.
More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage:
1) raw text (hard/effortful to read)
2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default
3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default
...4,5,6,...
n) interactive neural videos/simulations
Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral x.com/zan2434/status…
There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen.
TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
Thariq@trq212
English
@simonw Indeed it is for final output, but if you use documents for human/llm collaboration I prefer information dense format, as md. html is good to read, but bad to write on humans side. In my 2nd brain wiki I use html only for what I call views, md for the collaborative work w/ llm
English
Asking for HTML explanations of things is pretty neat, I tried it just now with the obfuscated Python POC for the new copy.fail Linux vulnerability: #trying-this-out" target="_blank" rel="nofollow noopener">simonwillison.net/2026/May/8/unr…
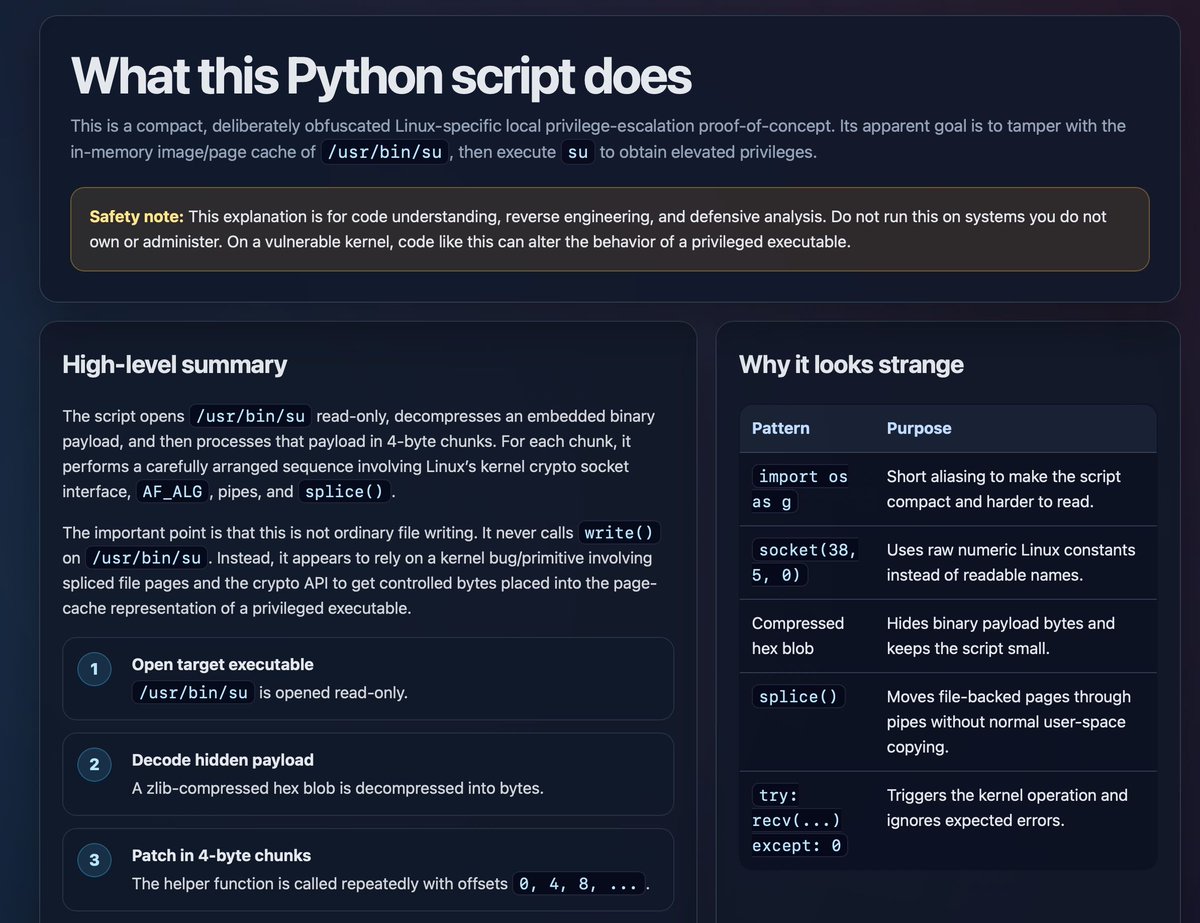
Thariq@trq212
English
Yup, local inference as Hacker or user is something becoming more and more relevant... But very expensive
antirez@antirez
Appreciate Ivan tweet. To put this into context, to build DS4 I used: my MacBook M3 Max (mine, 8k euros), 1 M3 Ultra with 512 GB (got access, 10k euros), one DGX Spark (got access, 4k euros?). Are we far from the times all you needed to do hacking was a computer? That's sad.
English
@trq212 @antirez @badlogicgames Well as said in another comment it may be useful for pure output, but if llm and human need to collaborate on a document better md. Hand editing html is still pain
English

@antirez @badlogicgames like with most things LLM-related this is empirical and subjective, people can have different preferences but imo worth trying
i was also skeptical initially tbh, tried things like MDX instead but kept coming back to HTML
English
Markdown vs HTML. Every time we go from a semantically dense to a semantically sparse format, we lose. Even more today where less tokens from the same content is way better. I can understand we need a better markdown. I can't understand we should replace it with HTML.
English
@antirez Yup I agree in general sense. Any artifact used to wok and exchange info with the llm should be information dense. Format w/ information less dense in favor of human consumability is for output only. It's the reason because I added the concept of views to my llm wiki 2nd brain
English
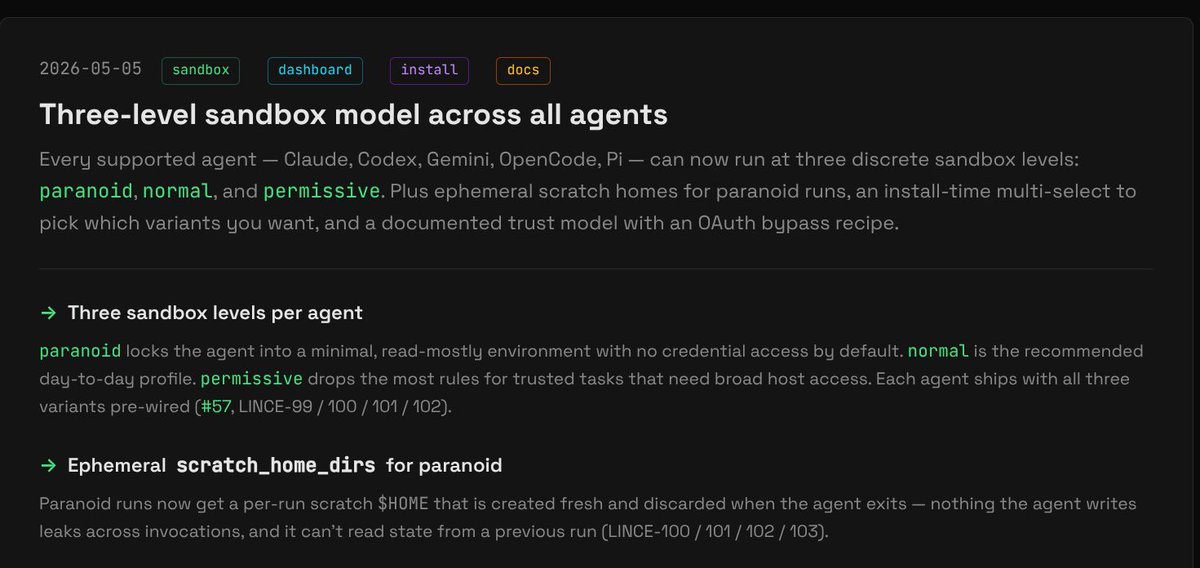
API key in env + open network = wrapper, not sandbox.
LINCE paranoid: Linux netns isolation (--unshare-net) + credential proxy holds the key over a unix socket.
lince.sh/changelog
English
CLI, AI and a Rover that didn't go straight: robotics seen by a software engineer.
Read the full story here: artificialcode.substack.com/p/cli-ai-and-a…

English
Stefano retweetledi

Backlog v1.45.0 contains multiple new features and QoL improvements across the Web UI, TUI, CLI and MCP.
For the full release notes check: github.com/MrLesk/Backlog…

English