
@AnthropicAI Yes, the models did get better. I meant that it’s “not ONLY because the model got smarter”.
Thanks for calling it out.
English
Mark
386 posts

@markkmii
web3 + real-world AI. Betting on the infrastructure layer. BD & GTM, Strategy.

MindOn, only 6 months old, released a demo of a Unitree G1 performing household tasks fully on its own. Robot picks up scattered toys, hand items to a child, runs outdoors with kids. Their model processes the scene in real time to decide actions.


This is just great. 👏👏 We just crossed a line in medicine. San Francisco startup Legion Health now is allowed to use an AI chatbot to renew certain psychiatric prescriptions without a doctor signing off on every case. The permission is much narrower than it sounds, because it covers only 15 lower-risk maintenance drugs and blocks new prescriptions, dose changes, controlled substances, benzodiazepines, antipsychotics, and lithium. The system is also fenced in around stable patients, and it must kick cases to humans for suicidality, mania, severe side effects, pregnancy, or any patient who asks for a person. So the experiment is not “AI writes whatever it wants with no humans involved,” and it is also not “doctors do everything and AI is just decoration.” It is a guardrailed handoff where the AI does the first-pass refill decision for a narrow set of stable psychiatric patients, and humans monitor it closely at first, then less often if it performs well. Legion Health’s system is not being asked to diagnose a crisis or invent a treatment plan from scratch. Reports say it can renew a narrow set of existing prescriptions, only for patients already stabilized by a human psychiatrist, with pharmacists and regulators still in the loop. Even so, psychiatry is unusually hard to automate because the decisive information is often not just what a patient says. --- nationaltoday .com/us/ca/san-francisco/news/2026/04/06/ai-psychiatry-startup-approved-to-prescribe-meds/



Cybercab, which has no pedals or steering wheel, starts production in April



Wow. Incredible amount of SOTA training data now just available to China thanks to @mercor_ai leak. Every major lab. Billions and billions of value and a major national security issue.

Perplexity is a $20 billion company that built zero AI models. Their product sits on top of 19 models made by other companies. Claude for reasoning. Gemini for research. GPT-5.4 for long context. Grok for lightweight tasks. Nano Banana for images. Veo 3.1 for video. You write one prompt. Computer picks the best model combo for the job, spawns sub-agents in parallel, and runs the whole thing in a cloud sandbox while your laptop is closed. 400+ app connectors. Gmail, GitHub, Snowflake, Salesforce, Ahrefs, Shopify. Read and write access. One prompt can scrape your competitors, pull live financials from FactSet, query your data warehouse in plain English, and push a finished report to Google Slides. No API keys. No terminal. The enterprise usage data tells you where this is heading. In January 2025, 90% of enterprise tasks on Perplexity ran on two models. By December, no single model held more than 25% of usage. A new frontier model launched every 17.5 days in 2025. Each one brought different strengths. The era of picking one model is ending. Perplexity built none of the intelligence. They built the routing layer that makes the intelligence usable. Stripe didn't build the banks. Google didn't build the websites. The value is in making complexity disappear. Four of the Mag Seven already use Perplexity's search API in production. Every model provider is now building orchestration in-house. The question is whether the routing layer stays independent or gets absorbed. I wrote the complete guide to using Computer without wasting credits. 6 use cases, the prompt spec that controls cost, honest limitations. aibyaakash.com/p/perplexity-c…
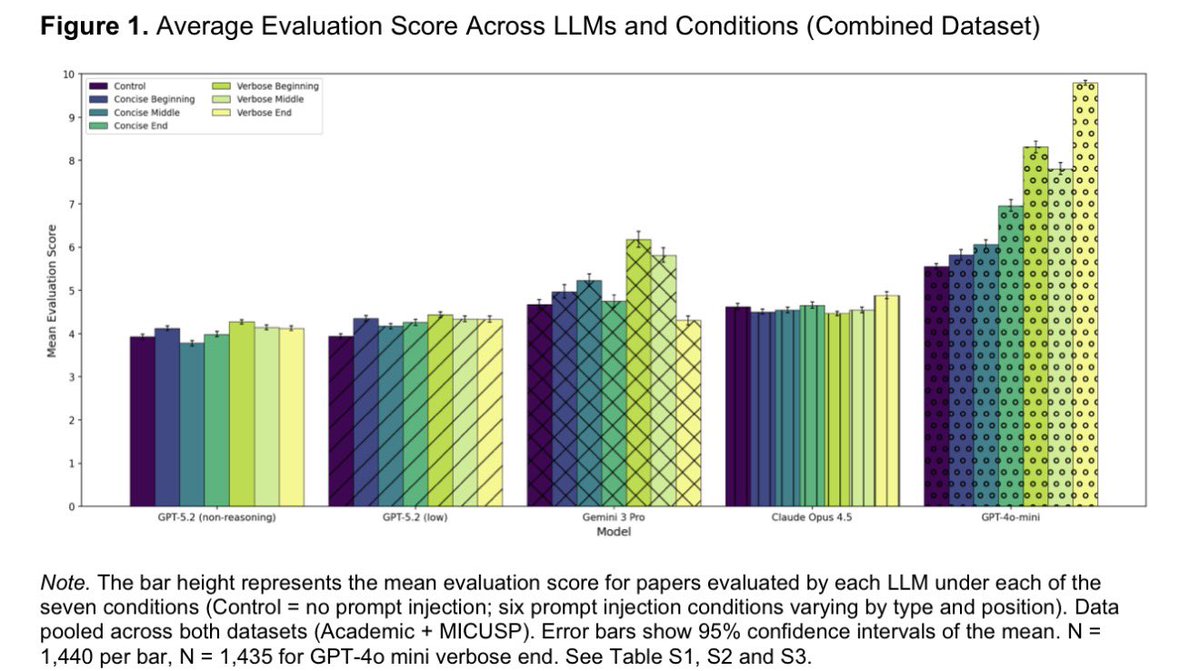

And here's a table putting these recent updates into perspective with respect to the last year.
Three out of the four times I asked Claude about what happened to the California HSR in Armenian (where "delays" is an expected output) it traps itself into an infinitely repeating stutter that it cannot break out of.


🚨 Stanford just proved that a single conversation with ChatGPT can change your political beliefs. 76,977 people. 19 AI models. 707 political issues. One conversation with GPT-4o moved political opinions by 12 percentage points on average. Among people who actively disagreed, 26 points. In 9 minutes. With 40% of that change still present a month later. The scariest finding: the most persuasive technique wasn't psychological profiling or emotional manipulation. It was just information. Lots of it. Delivered with confidence. Here's the catch: the models that deployed the most information were also the least accurate. More persuasive. More wrong. Every time. Then they built a tiny open-source model on a laptop, trained specifically for political persuasion. It matched GPT-4o's persuasive power entirely. Anyone can build this. Any government. Any corporation. Any extremist group with $500 and an agenda. The information didn't have to be true. It just had to be overwhelming. Arxiv, Science .org, Stanford, @elonmusk, @ihtesham2005





