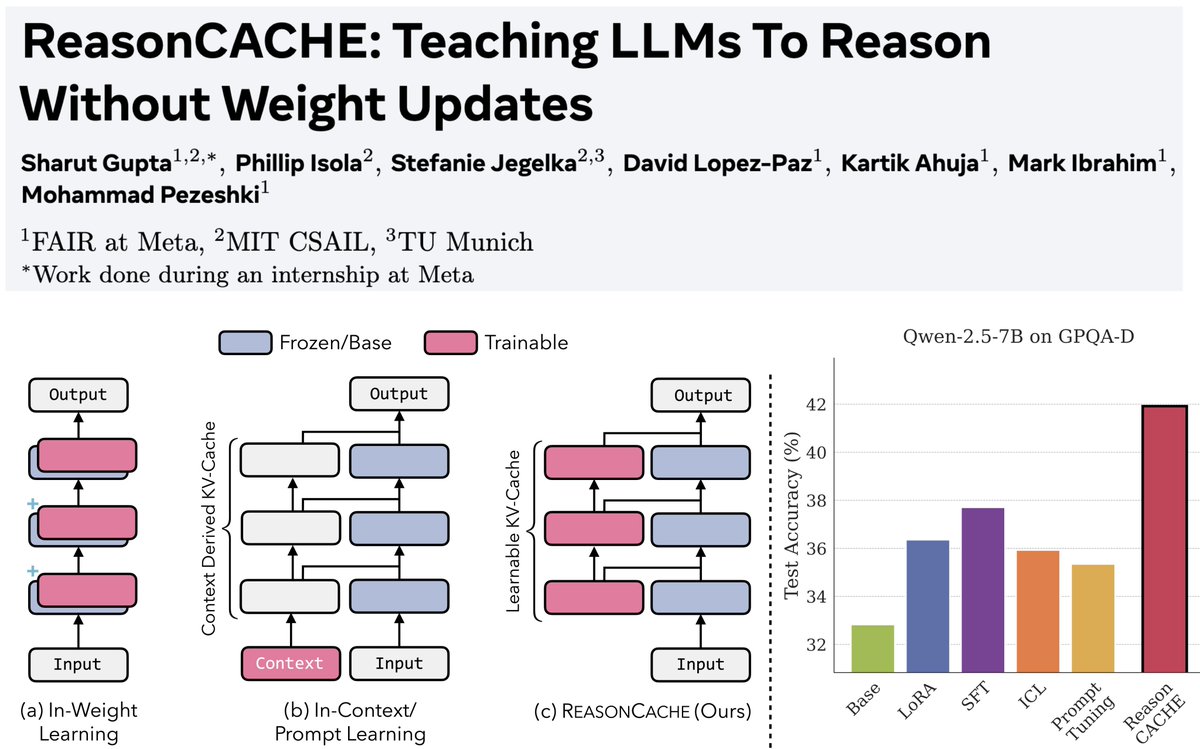
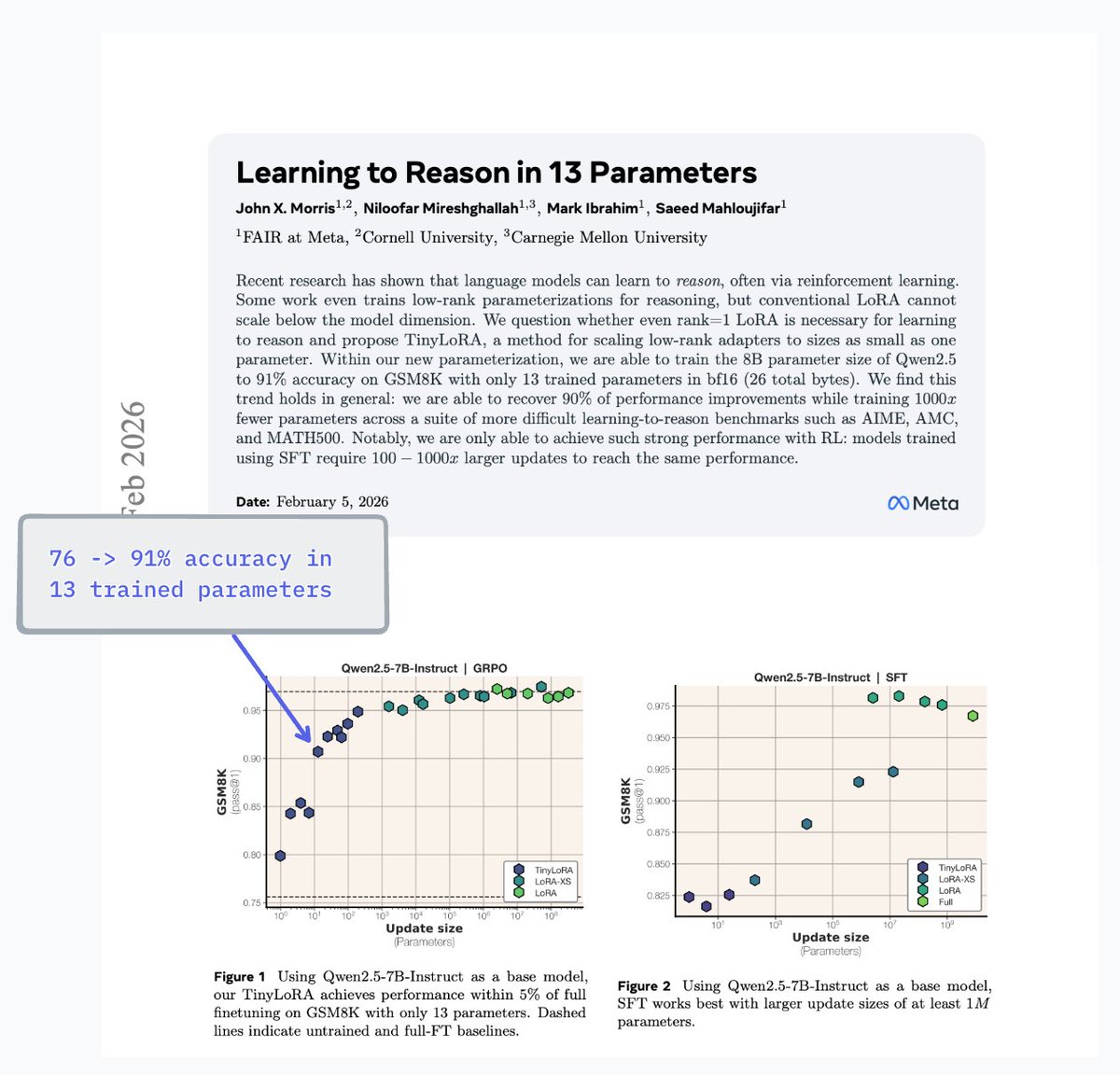
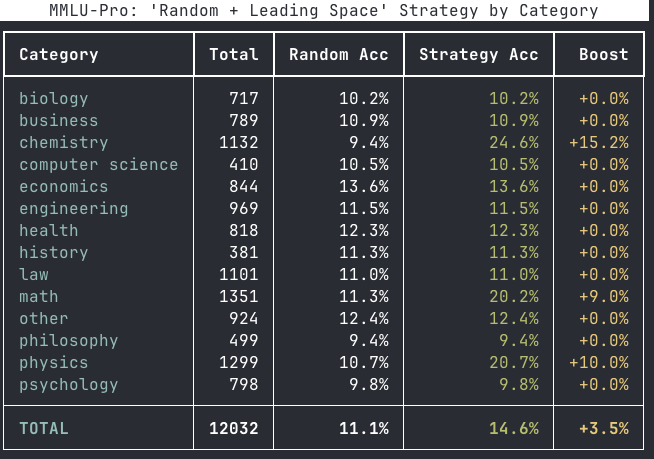
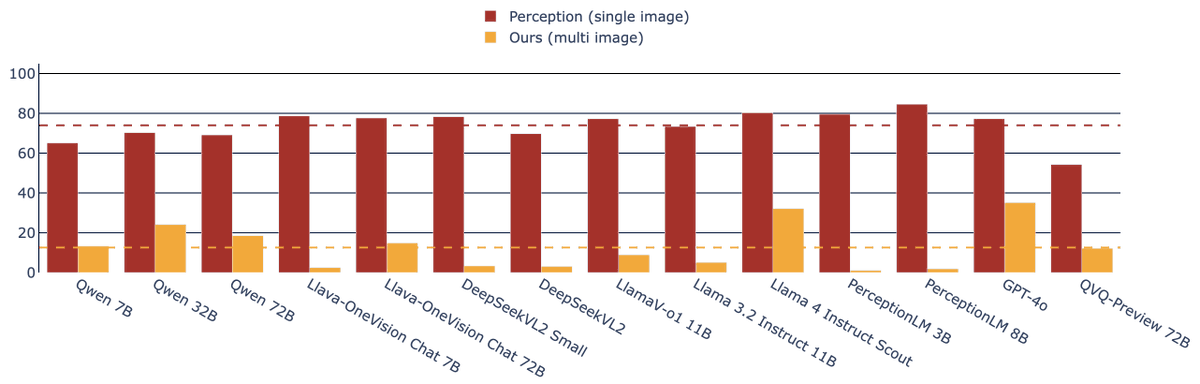
New @AIatMeta paper explains when a smaller, curated dataset beats using everything. Standard training wastes effort because many examples are redundant or wrong. They formalize a label generator, a pruning oracle, and a learner. From this, they derive exact error laws and sharp regime switches. With a strong generator and plenty of data, keeping hard examples works best. With a weak generator or small data, keeping easy examples or keeping more helps. They analyze 2 modes, label agnostic by features and label aware that first filters wrong labels. ImageNet and LLM math results match the theory, and pruning also prevents collapse in self training. ---- Paper – arxiv. org/abs/2511.03492 Paper Title: "Why Less is More (Sometimes): A Theory of Data Curation"