@Techmeme @theo_wayt xAI is very egalitarian. Doesn’t matter if you finished your PhD or even your undergrad. Your ideas are judged based on their merit and not your credentials, which means everyone gets humbled at some point.
English
Mason Wang
51 posts
@masonlongwang
Audio Understand Lead @ xAI, post-training Grok Voice on the world’s biggest GPU cluster. PhD at MIT CSAIL (On Leave).






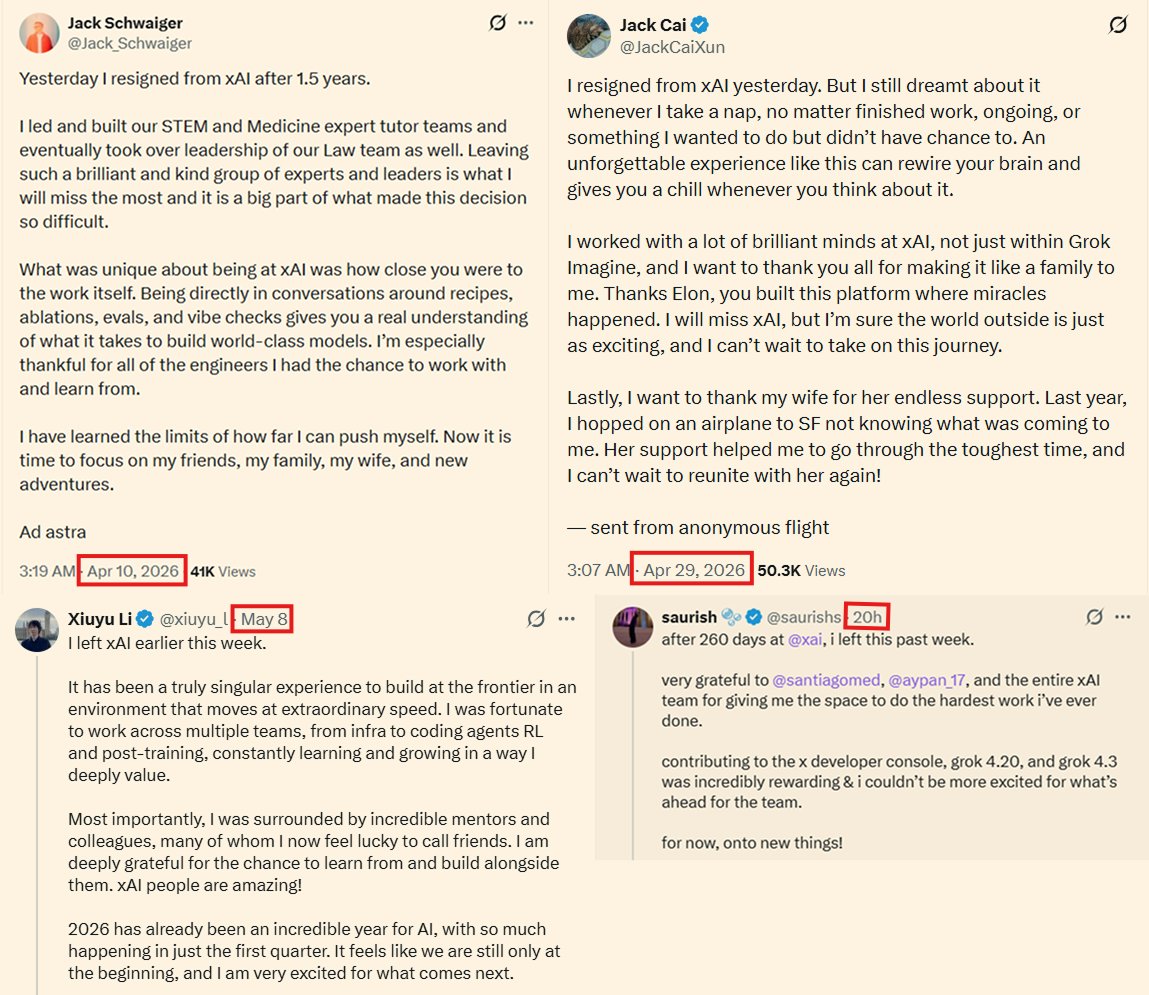
SpaceXAI update: >50 researchers/engineers have left xAI through layoffs, firings and resignations since SpaceX acquired it in Feb Exits in past 2 weeks include former heads of coding, world models, Grok voice At least 11 have gone to Meta and 7 to Thinking Machines Lab
This is by far the best voice agent I've ever tried so far. If you have a physical business, you need this. If you have an AI Agent, this is the next big thing. Judge it by yourself:



🇺🇸🇨🇳 Elon is joining Trump on his trip to China this Wednesday to meet Xi. Tesla operates one of its biggest factories in Shanghai. SpaceX supply chain ties run deep into Chinese manufacturing. Elon isn't just a guest on this trip.


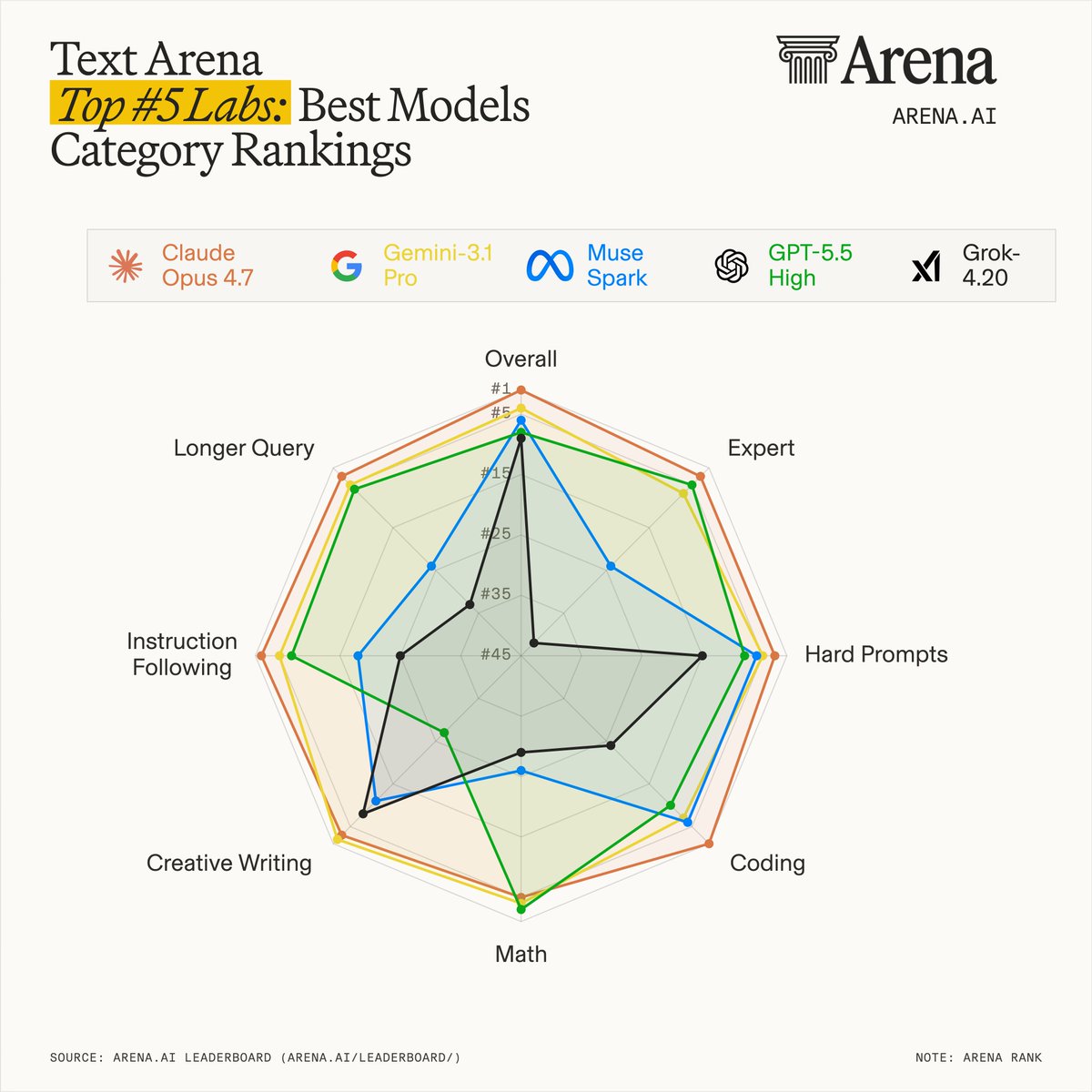
Grok Voice Think Fast 1.0 ranks #1 on the Artificial Analysis τ-Voice benchmark for real-world agentic customer service resolution Absolutely outperforming GPT-Realtime-2 (High) and Gemini 3.1 Flash by a huge margin That's a massive 12%+ lead over OpenAI's best model that just released a few days ago Grok is running real-time background reasoning without the latency penalty, which is why it is already handling live Starlink phone operations autonomously at scale

Announcing agentic performance benchmarking for Speech to Speech models on Artificial Analysis. We use 𝜏-Voice to measure tool calling and customer interaction voice agent capabilities in realistic customer service scenarios Even the strongest Speech to Speech (S2S) models today resolve only about half of realistic customer service scenarios end-to-end - a meaningful gap relative to frontier text-based agents on the same tasks. Voice channels introduce significant complexity: challenging accents, background noise, and packet loss, all while requiring fast responses, consistency across long multi-turn conversations, and reliable tool use. Performance also varies considerably by audio condition: in clean audio some models perform notably better, but realistic conditions continue to pose a challenge. Conversation duration also varies meaningfully across models, with implications for both customer experience and operational cost. About 𝜏-Voice: Our Agentic Performance benchmark is based on 𝜏-Voice (Ray, Dhandhania, Barres & Narasimhan, 2026), which extends 𝜏²-bench into the voice modality to evaluate S2S models on realistic customer service tasks. It measures multi-turn instruction following, support of a simulated customer through a complete interaction, and tool use against simulated customer service systems. The simulated user combines an LLM-driven decision model with realistic audio synthesis: diverse accents, background noise, and packet loss modelled on real network conditions. This complements our Big Bench Audio benchmark measuring intelligence and Conversational Dynamics (Full Duplex Bench subset) benchmark measuring conversational naturalness. Scores are the average of three independent pass@1 trials. We evaluate under realistic audio conditions using the 𝜏²-bench base task split across three domains: ➤ Airline (50 scenarios): e.g., changing a flight, rebooking under policy constraints ➤ Retail (114 scenarios): e.g., disputing a charge, processing a return ➤ Telecom (114 scenarios): e.g., resolving a billing issue, troubleshooting a service problem Task success is determined by deterministic checks against expected actions and final database state, consistent with the 𝜏²-bench evaluator. Key results: xAI's Grok Voice Think Fast 1.0 is the clear leader at 52.1%, averaging 5.6 minutes per conversation, the second-longest overall. OpenAI's GPT-Realtime-2 (High) (39.8%, 3.0 min) and GPT-Realtime-1.5 (38.8%, 4.8 min) follow, with Gemini 3.1 Flash Live Preview - High close behind at 37.7% (3.8 min). Speech to Speech is a fast evolving modality and we expect movement in rankings as we continue to add new models with these capabilities, and model robustness improves. Congratulations @xAI @elonmusk! See below for further detail ⬇️
Announcing agentic performance benchmarking for Speech to Speech models on Artificial Analysis. We use 𝜏-Voice to measure tool calling and customer interaction voice agent capabilities in realistic customer service scenarios Even the strongest Speech to Speech (S2S) models today resolve only about half of realistic customer service scenarios end-to-end - a meaningful gap relative to frontier text-based agents on the same tasks. Voice channels introduce significant complexity: challenging accents, background noise, and packet loss, all while requiring fast responses, consistency across long multi-turn conversations, and reliable tool use. Performance also varies considerably by audio condition: in clean audio some models perform notably better, but realistic conditions continue to pose a challenge. Conversation duration also varies meaningfully across models, with implications for both customer experience and operational cost. About 𝜏-Voice: Our Agentic Performance benchmark is based on 𝜏-Voice (Ray, Dhandhania, Barres & Narasimhan, 2026), which extends 𝜏²-bench into the voice modality to evaluate S2S models on realistic customer service tasks. It measures multi-turn instruction following, support of a simulated customer through a complete interaction, and tool use against simulated customer service systems. The simulated user combines an LLM-driven decision model with realistic audio synthesis: diverse accents, background noise, and packet loss modelled on real network conditions. This complements our Big Bench Audio benchmark measuring intelligence and Conversational Dynamics (Full Duplex Bench subset) benchmark measuring conversational naturalness. Scores are the average of three independent pass@1 trials. We evaluate under realistic audio conditions using the 𝜏²-bench base task split across three domains: ➤ Airline (50 scenarios): e.g., changing a flight, rebooking under policy constraints ➤ Retail (114 scenarios): e.g., disputing a charge, processing a return ➤ Telecom (114 scenarios): e.g., resolving a billing issue, troubleshooting a service problem Task success is determined by deterministic checks against expected actions and final database state, consistent with the 𝜏²-bench evaluator. Key results: xAI's Grok Voice Think Fast 1.0 is the clear leader at 52.1%, averaging 5.6 minutes per conversation, the second-longest overall. OpenAI's GPT-Realtime-2 (High) (39.8%, 3.0 min) and GPT-Realtime-1.5 (38.8%, 4.8 min) follow, with Gemini 3.1 Flash Live Preview - High close behind at 37.7% (3.8 min). Speech to Speech is a fast evolving modality and we expect movement in rankings as we continue to add new models with these capabilities, and model robustness improves. Congratulations @xAI @elonmusk! See below for further detail ⬇️