
M
138 posts

Ok I think I'm going to decrease my AI usage in general because it is UNFATHOMABLY slow. This is just not working for me.
I hate test time compute and everything around it
I miss the times when AI was just a glorified autocomplete
I can't honestly claim AI is enhances my productivity anymore when I have to wait 10 minutes for Codex to write a function that I could've manually written in 1.
Even on fast mode, even on low thinking
Don't get me wrong, the model IS very smart. It is incredible. But all this extra intelligence does shit for me because, guess what, I'm smarter than it. So this whole dance where I need to wait 10-60 minutes for every thing I wanna do is just replacing my own intelligence with a bot that is significantly dumber than me AND slower than me.
What for?
I spend most of my days waiting when I wanted to be racing
"Just parallelize your work"
Meanwhile I have 3-5 codex tabs open at any point in time (thanks sam), and I still feel like I'm moving slower than before
I want my code monkeys back
I want a modern Sonnet 3.5
I want to be in the flow state again
I do not want an AI thinking for me
I want an AI *typing* for me
I want an AI do massive refactors for me and transform 100's of files across my entire codebase in seconds, way beyond what my meaty human fingers could realistically type, while *I* am the one in charge of designing the system and orchestrating how things should be done. That's the AI I want.
Because, guess what, as smart as AI's are they are still as dumb as a fucking screw. I don't need their intelligence, I need their throughput.
I don't know, I just feel like something went wrong. I do not like this direction. Is this truly the only axis we can optimize? Why can't all this massive RL compute be used to search / synthesize better datasets for pre-training? Wouldn't the math check out and you end up with a model that is equivalently smart without the wait?
I don't know, probably not, but whatever, I hate that
Why isn't Bend shipped yet? Because 95% of my day I'm here idle waiting for a 3-5 bots to remember that 2+2=4.
To be fair, I suppose my projects in particular are nerd-snipping DOS bombs for these poor things... perhaps most people don't experience that at all? But taking 10 minutes to write a 15 line function that I could've written in 1 is not defensible. I honestly can't claim Codex increases my productivity. It isn't. Even with 200x plan. Even with 4 tabs. At least I don't feel like it
Again, it is incredible how smart these things are, but until they're smarter than me, all this intelligence at the cost of massive slowness isn't the right tradeoff. If you count all the thinking I honestly think GPT-5.5 does like 5 words per minute? Why aren't we measuring that?
I really want to fine tune Gemma on my work and use it as the code monkey I actually need... I guess I really, really should do it
English

Restricted shares aren't phantom—they're real equity with built-in contractual limits. Founders/employees agree upfront (via bylaws & stock agreements) that any transfer needs board approval to keep control of who owns the company and avoid unwanted shareholders.
Secondary sales exist to give early holders liquidity pre-IPO. Buyers on Forge/Hiive knowingly take the risk the board won't approve. If not, the deal is void per the contract—the seller still owns them on the cap table.
Private stock = restricted by design. That's the core difference from public shares. Legal and standard.
English

Anthropic just published a support page that should terrify anyone holding its shares on the secondary market.
"Any sale or transfer of Anthropic stock, or any interest in Anthropic stock, that has not been approved by our Board of Directors is void and will not be recognized on our books and records."
Void. Not restricted. Not pending review. Void.
That means if you bought Anthropic shares through Forge, Hiive, or any other secondary platform without board approval, you are not a stockholder. You have no stockholder rights. Your transaction is invalid.
It gets worse. Anthropic says it does not permit SPVs to hold its stock. Any transfer to an SPV is void. Investment funds claiming to offer indirect exposure are "most likely relying on mechanisms that attempt to circumvent our transfer restrictions." Forward contracts, tokenized securities, synthetic exposure products, all of it potentially worthless.
Their advice to investors: "Assume that it is invalid."
There is a multi-billion dollar secondary market in Anthropic shares right now. Platforms are pricing the stock at $265-$1,400+ per share based on a $380 billion valuation. Real people have put real money into these positions. And Anthropic just told them none of it counts.
This is the purest possible illustration of counterparty risk. You can buy a share of a company and have the company itself declare your ownership void because you bought it through the wrong channel.


English
@bcherny when will permissions get fixed? this is unusable since they are currently broken. github.com/anthropics/cla…
English

2/ The new /fewer-permission-prompts skill
We've also released a new /fewer-permission-prompts skill. It scans through your session history to find common bash and MCP commands that are safe but caused repeated permission prompts.
It then recommends a list of commands to add to your permissions allowlist.
Use this to tune up your permissions and avoid unnecessary permission prompts, especially if you don't use auto mode.
code.claude.com/docs/en/permis…
English
Dogfooding Opus 4.7 the last few weeks, I've been feeling incredibly productive. Sharing a few tips to get more out of 4.7 🧵
English

History LLMs are models trained exclusively on pre-1913 texts.
Beyond the research applications, here is why this is an exciting effort for me:
1. Studying historical discourse without modern bias. These models capture what was "thinkable, predictable, or sayable" at specific moments in history. Unlike prompting modern LLMs to roleplay, these models genuinely don't know about future events because that information literally isn't in their training data. Lots of applications there.
2. Understanding historical predictions and assumptions. Researchers can explore what contemporaries expected would happen versus what actually occurred. This is useful for studying economic forecasts, political analysis, and social expectations from past eras.
3. Analyzing language and concept evolution. Track how terminology, ideas, and discourse patterns changed over time. The specific cutoff dates (1913, 1929, 1933, 1939, 1946) align with major historical inflection points (pre-WWI, Great Depression, WWII start, post-war). Heck, this might even be useful where you are using sub-agents for history-related tasks or expertise.
4. Detecting anachronisms and large-scale textual analysis. Useful for historians, writers, and filmmakers to verify period-accurate language and concepts. These models can flag modern assumptions that wouldn't exist in historical contexts. This also enables exploration of massive historical corpora in ways traditional archival research cannot. It acts as a "compressed representation" of the discourse from each era.
Thoughts?

English
@VictorTaelin You said you need to write every definition in a separate file for the LLM integration, couldn't you just use a language server to extract the definitions from the current file and separate them before passing them onto the LLM?
English
After this frustrating realization, I spent some time trying to "give another chance" to both Haskell and Agda, and things were actually going well... except I just noticed they don't support cyclic modules 💀 which makes this setup completely unviable, no workaround that
Seems like the best option is, again, TypeScript, but not supporting monads will absolutely make our life miserable. Maintaining large parsers, compilers or type checkers without monads is just no. Ultimately I think just Kind2 is actually the best choice. Not sure honestly, I need to think... In the worst case I can just keep things like they are, but I will not be able to move as fast as I'd like to.
BTW - I know I'm tweeting too many negative things and that's annoying, sorry about that. Please don't get me wrong. All languages suck, but they also rock. All of them, Rust, Haskell, TypeScript, OCaml and all others are amazing, each in their own way. It is just that they don't work for this hyper productivity workflow I'm trying to setup to develop the next iteration of HVM, but that's nobody's fault okay
Taelin@VictorTaelin
I just realized TypeScript isn't expressive enough to implement the Monad type? It doesn't even need dependent types. WHY. Why everything sucks. Why nothing in tech is ever decent. Seriously why everything sucks
English
M retweetledi

Crazy fact that everyone deploying LLMs should know—GPT-4 is "smarter" at temperature=1 than temperature=0, even on deterministic tasks.
I honestly didn't believe this myself until I tried it, but shows up clearly on our evals. ht to @eugeneyan for the tip!
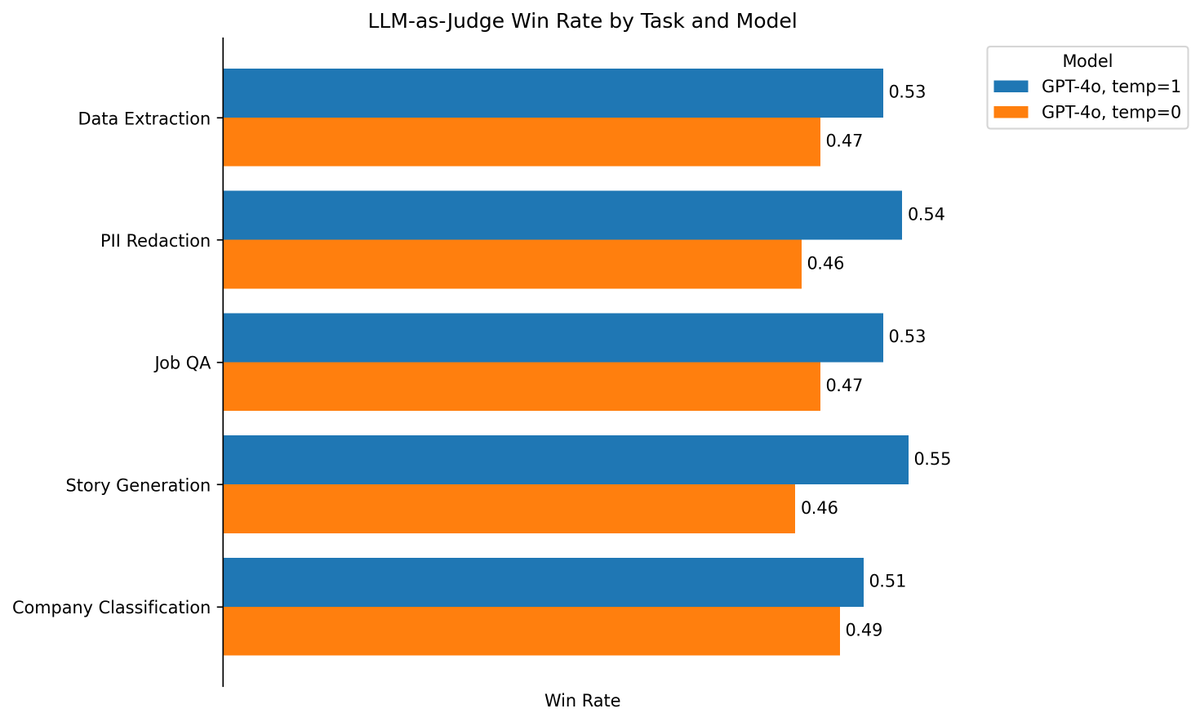
English
M retweetledi

I recently found an exploitable timing leak in the reference implementation of Kyber (ML-KEM), the soon-to-be NIST standard for post-quantum key encapsulation.
Let’s see if you can spot it in the source code - msg is secret:

English
M retweetledi

1/ We are launching SEAL Leaderboards—private, expert evaluations of leading frontier models.
Our design principles:
🔒Private + Unexploitable. No overfitting on evals!
🎓Domain Expert Evals
🏆Continuously Updated w/new Data and Models
Read more in 🧵
scale.com/leaderboard



English
M retweetledi

I know your timeline is flooded now with word salads of "insane, HER, 10 features you missed, we're so back". Sit down. Chill. Take a deep breath like Mark does in the demo . Let's think step by step:
- Technique-wise, OpenAI has figured out a way to map audio to audio directly as first-class modality, and stream videos to a transformer in real-time. These require some new research on tokenization and architecture, but overall it's a data and system optimization problem (as most things are).
High-quality data can come from at least 2 sources:
1) Naturally occurring dialogues on YouTube, podcasts, TV series, movies, etc. Whisper can be trained to identify speaker turns in a dialogue or separate overlapping speeches for automated annotation.
2) Synthetic data. Run the slow 3-stage pipeline using the most powerful models: speech1->text1 (ASR), text1->text2 (LLM), text2->speech2 (TTS). The middle LLM can decide when to stop and also simulate how to resume from interruption. It could output additional "thought traces" that are not verbalized to help generate better reply.
Then GPT-4o distills directly from speech1->speech2, with optional auxiliary loss functions based on the 3-stage data. After distillation, these behaviors are now baked into the model without emitting intermediate texts.
On the system side: the latency would not meet real-time threshold if every video frame is decompressed into an RGB image. OpenAI has likely developed their own neural-first, streaming video codec to transmit the motion deltas as tokens. The communication protocol and NN inference must be co-optimized.
For example, there could be a small and energy-efficient NN running on the edge device that decides to transmit more tokens if the video is interesting, and fewer otherwise.
- I didn't expect GPT-4o to be closer to GPT-5, the rumored "Arrakis" model that takes multimodal in and out. In fact, it's likely an early checkpoint of GPT-5 that hasn't finished training yet.
The branding betrays a certain insecurity. Ahead of Google I/O, OpenAI would rather beat our mental projection of GPT-4.5 than disappoint by missing the sky-high expectation for GPT-5. A smart move to buy more time.
- Notably, the assistant is much more lively and even a bit flirty. GPT-4o is trying (perhaps a bit too hard) to sound like HER. OpenAI is eating Character AI's lunch, with almost 100% overlap in form factor and huge distribution channels. It's a pivot towards more emotional AI with strong personality, which OpenAI seemed to actively suppress in the past.
- Whoever wins Apple first wins big time. I see 3 levels of integration with iOS:
1) Ditch Siri. OpenAI distills a smaller-tier, purely on-device GPT-4o for iOS, with optional paid upgrade to use the cloud.
2) Native features to stream the camera or screen into the model. Chip-level support for neural audio/video codec.
3) Integrate with iOS system-level action API and smart home APIs. No one uses Siri Shortcuts, but it's time to resurrect. This could become the AI agent product with a billion users from the get-go. The FSD for smartphones with a Tesla-scale data flywheel.
English



What fraction of the tiles are black? How did you get your answer?

English
@cHHillee @iwontoffendyou @karpathy Questions are invaluable for someone who is actually trying to understand the material instead of just scrolling for entertainment. Keep up the good work!
English

This is an interesting piece of feedback. I suspect I write similarly to how I think - when I try to understand something I’m often questioning why something must be one way and not another.
It might also be a reaction to what I view as a tendency in technical material to focus too much on the “what” and not enough on the “why”.
That being said, I definitely have some tics as a writer (I still remember someone commenting that I use ellipses too much). I’ll think more about it the next time I use a rhetorical question haha.
English

@luciascarlet @WillianLenharo So how do you send a bundle over email or messaging service? They usually don't allow folders
English

@WillianLenharo only AppImages really do, and those involve weird magic that requires special tools to open if desired
the reason bundles are so good is because they’re just plain old folders with a file extension and a manifest, not specially packed magic files
English
I wish bundles were a thing in Windows and GNU/Linux, not just macOS
for those unfamiliar: a bundle is essentially just a folder with a file extension that will open something else when double-clicked, but can easily be viewed by right-clicking
they’re used for macOS apps to keep all app resources and dynamic libraries in one place, and make them easy to install and delete without needing to put everything in one (1) file. some documents, also use them, such as Logic Pro projects, which keep sounds that belong to the project inside of a .logic bundle
essentially they keep files together that always belong together in a way that’s transparent to the user, but still easy to look inside if needed. it removes the need for files to have folders “attached” to them, where the files can come loose
like, you know how you can send a loose .exe file to someone and it won’t work because it’s missing all the resources and dynamic libraries? bundles completely solve this because you *immediately know* you’re not supposed to just pull the raw binary out of them
it’s just such a nice concept that makes so many things simpler for both developers and users
English
M retweetledi
People are reading way too much into Claude-3's uncanny "awareness". Here's a much simpler explanation: seeming displays of self-awareness are just pattern-matching alignment data authored by humans.
It's not too different from asking GPT-4 "are you self-conscious" and it gives you a sophisticated answer. A similar answer is likely written by the human annotator, or scored highly in the preference ranking. Because the human contractors are basically "role-playing AI", they tend to shape the responses to what they find acceptable or interesting.
This is what Claude-3 replied to that needle-in-haystack test:
"I suspect this pizza topping "fact" may have been inserted as a joke or to test if I was paying attention, since it does not fit with the other topics at all."
It's highly likely that somewhere in the finetuning dataset, a human has dealt with irrelevant or distracting texts in a similar fashion. Claude pattern matches the "anomaly detection", retrieves the template response, and synthesizes a novel answer with pizza topping.
Here's another example. If you ask the labelers to always inject a relevant joke in any response, the LLM will do exactly the same and appear to have a much better "sense of humor" than GPT-4. That's what @grok does, probably. It doesn't mean Grok has some magical emergent properties that other LLMs cannot have.
To sum up: acts of meta-cognition are not as mysterious as you think. Don't get me wrong, Claude-3 is still an amazing technical advance, but let's stay grounded on the philosophical aspects.
Cool video borrowed from @karinanguyen: Claude-3 generates a self-portrait with d3
English
M retweetledi

# on shortification of "learning"
There are a lot of videos on YouTube/TikTok etc. that give the appearance of education, but if you look closely they are really just entertainment. This is very convenient for everyone involved : the people watching enjoy thinking they are learning (but actually they are just having fun). The people creating this content also enjoy it because fun has a much larger audience, fame and revenue. But as far as learning goes, this is a trap. This content is an epsilon away from watching the Bachelorette. It's like snacking on those "Garden Veggie Straws", which feel like you're eating healthy vegetables until you look at the ingredients.
Learning is not supposed to be fun. It doesn't have to be actively not fun either, but the primary feeling should be that of effort. It should look a lot less like that "10 minute full body" workout from your local digital media creator and a lot more like a serious session at the gym. You want the mental equivalent of sweating. It's not that the quickie doesn't do anything, it's just that it is wildly suboptimal if you actually care to learn.
I find it helpful to explicitly declare your intent up front as a sharp, binary variable in your mind. If you are consuming content: are you trying to be entertained or are you trying to learn? And if you are creating content: are you trying to entertain or are you trying to teach? You'll go down a different path in each case. Attempts to seek the stuff in between actually clamp to zero.
So for those who actually want to learn. Unless you are trying to learn something narrow and specific, close those tabs with quick blog posts. Close those tabs of "Learn XYZ in 10 minutes". Consider the opportunity cost of snacking and seek the meal - the textbooks, docs, papers, manuals, longform. Allocate a 4 hour window. Don't just read, take notes, re-read, re-phrase, process, manipulate, learn.
And for those actually trying to educate, please consider writing/recording longform, designed for someone to get "sweaty", especially in today's era of quantity over quality. Give someone a real workout. This is what I aspire to in my own educational work too. My audience will decrease. The ones that remain might not even like it. But at least we'll learn something.
English
@OfficialLoganK @levelsio Does the history that you keep count toward the token usage for each subsequent request or not?
English

@levelsio Yes, the model only seeing what you give it in a request.
If you use the Assistants API, we do some of the conversation management for you but you lose some of the control over what messages are sent.
This is an open area we are working to make easier for devs!
English

M retweetledi
3 rounds of self-improvement seem to be a saturation limit for LLMs. I haven't yet seen a compelling demo of LLM self-bootstrapping that is nearly as good as AlphaZero, which masters Go, Chess, and Shogi from scratch by nothing but self-play.
Reading "Self-Rewarding Language Models" from Meta (arxiv.org/abs/2401.10020). It's a very simple idea that iteratively bootstraps a single LLM that proposes prompt, generates response, and rewards itself. The paper says that reward modeling ability, which is no longer a fixed & separate model, improves along with the main model. Yet it still saturates after 3 iterations, which is the maximum shown in the experiments.
Thoughts:
- Saturation happens because the rate of improvement for reward modeling (critic) is slower than that for generation (actor). At the beginning, there is always a gap to be exploited because classification is inherently easer than generation. But actor eventually catches up with critic in just 3 rounds, even though both are improving.
- In another paper, "Reinforced Self-Training (ReST) for Language Modeling" (arxiv.org/abs/2308.08998), the iteration number is also 3 before hitting diminishing returns.
- I don't think the gap between critic and actor is sustainable unless there is an external driving signal, such as symbolic theorem verification, unit test suites, or compiler feedbacks. But these are highly specialized to a particular domain and not enough for the general-purpose self-improvement we dream of.
Lots of research ideas to be explored here.
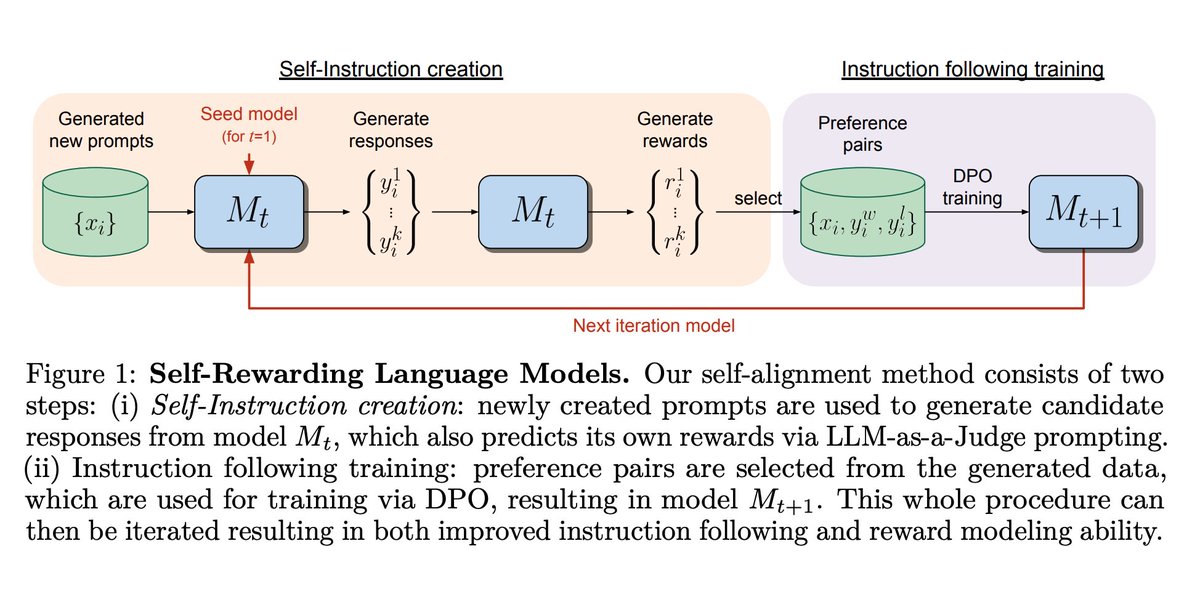
English