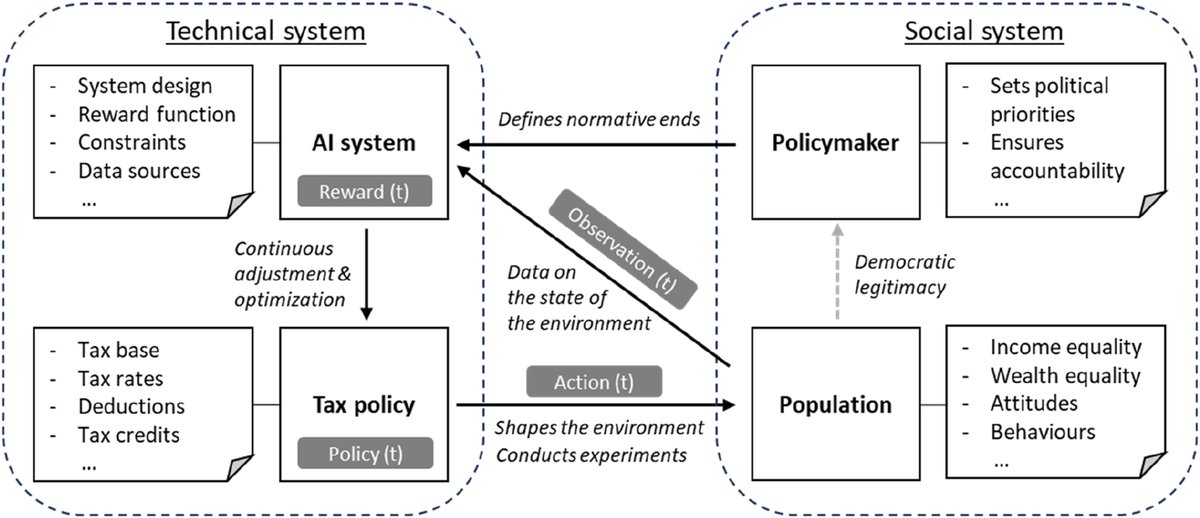
Matěj Myška retweetledi

🚨BREAKING: Singapore releases the report "Model Al Governance Framework for Generative Al - Fostering a Trusted Ecosystem," and it's a must-read for everyone interested in AI policy & regulation. Important information:
➡️The report outlines 9 dimensions to "create a trusted environment – one that enables end-users to use Generative AI confidently and safely, while allowing space for cutting-edge innovation." These are the 9 dimensions:
➵ Accountability
➵ Data
➵ Trusted Development and Deployment
➵ Incident Reporting
➵ Testing and Assurance
➵ Security
➵ Content Provenance
➵ Safety and Alignment R&D
➵ AI for Public Good
➡️Interesting quotes:
"Responsibility can be allocated based on the level of control that each stakeholder has in the generative AI development chain, so that the able party takes necessary action to protect end-users. As a reference, while there may be various stakeholders in the development chain, the cloud industry7 has built and codified comprehensive shared responsibility models over time. The objective is to ensure overall security of the cloud environment. These models allocate responsibility by explaining the controls and measures that cloud service providers (who provide the base infrastructure layer) and their customers (who host applications on the layer above)respectively undertake." (page 7)
-
"There is, therefore, a need to work with key parties in the content life cycle, such as working with publishers to support the embedding and display of digital watermarks and provenance details. As most digital content is consumed through social media platforms, browsers, or media outlets, publishers’ support is critical to provide end users with the ability to verify content authenticity across various channels. There is also a need to ensure proper and secure implementation to circumvent bad actors trying to exploit it in any way." (page 25)
-
"Industry, governments, and educational institutions can work together to redesign jobs and provide upskilling opportunities for workers. As organisations adopt enterprise generative AI solutions, they can also develop dedicated training programmes for their employees. This will enable them to navigate the transitions in their jobs and enjoy the benefits which result from job transformations" (page 30)
➡️Read the full report below.
➡️To stay up to date with the latest developments in AI policy & regulation, subscribe to my newsletter (link below).

English