Mathurin Videau retweetledi
Mathurin Videau
40 posts


Mathurin Videau retweetledi

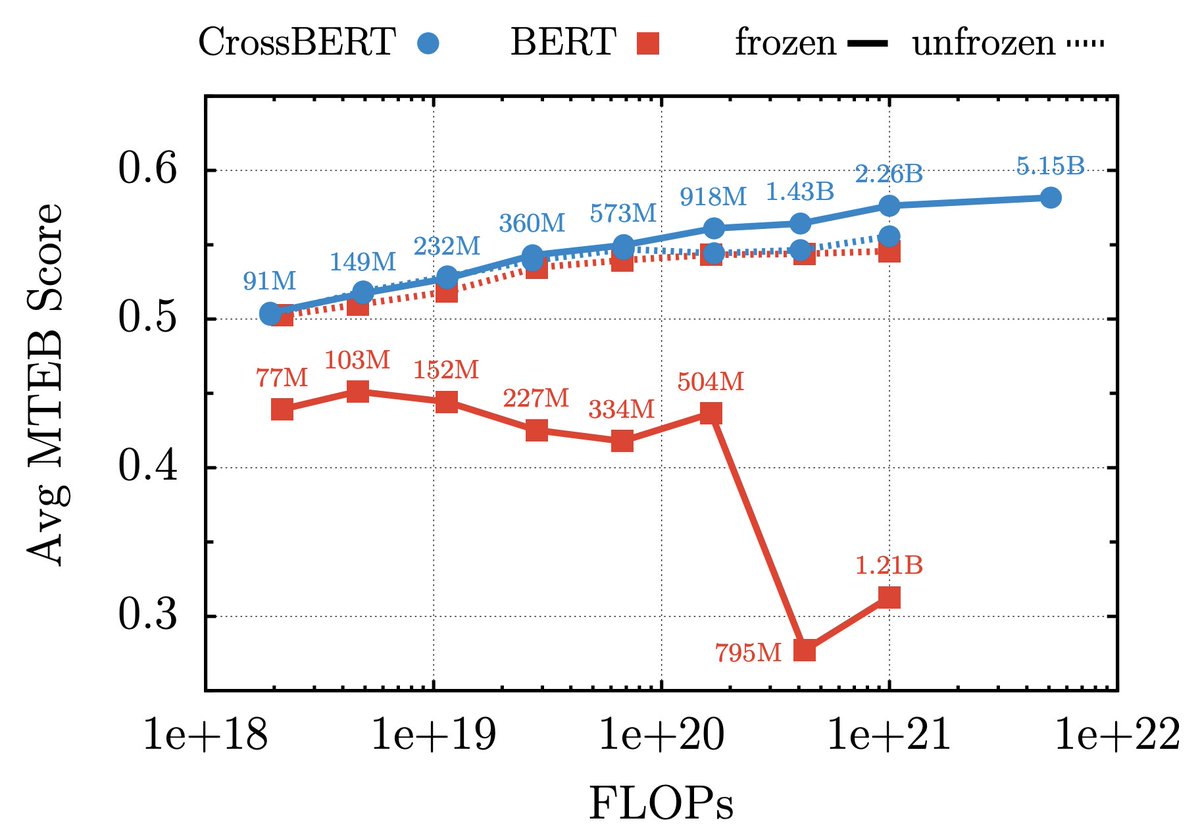
What advantage to use, and when? Everyone's proposing new advantage functions for RL with LLMs but nobody knows why they work or fail.
We break this down and build FADE a self-adapting advantage to get +14% on LiveCodeBench v6 in 40% less steps.
Paper: arxiv.org/pdf/2607.01490
GIF
English
Mathurin Videau retweetledi

🧵 For 2 RL checkpoints trained differently, you can just weight extrapolate them and it works!
Bonus: these extrapolated checkpoints are complementary policies
-> Get exploration and diversity for free
-> Better inference scaling when ensembling
Paper: arxiv.org/abs/2605.28751
GIF
Rosinality@rosinality
arxiv.org/abs/2605.28751 Now many studies try to do extrapolation through model merging. arxiv.org/abs/2605.26484
English
Mathurin Videau retweetledi

1/ We’re so glad to share this new study 💫
Does the brain learn like a Deep Net? 🧠⚙️
- 📄Misalignment Between Backpropagation and the Hierarchy of Brain Responses to Images
- 🔗arxiv.org/abs/2605.28693
Thread below 🧵
GIF
English
Mathurin Videau retweetledi

A new milestone in automatic formalization:
We translated an entire graduate math textbook into Lean using 30K LLM agents.
Open-source, large-scale multi-agent inference that actually works
> Blueprint+Lean: faabian.github.io/algebraic-comb…
> Codebase+preprint: github.com/facebookresear…
1/7

English
Mathurin Videau retweetledi

My first PhD paper is out! 🎓
"What Drives Success in Physical Planning with Joint-Embedding Predictive World Models?"
tl:dr: JEPA-WMs for robotics: learn dynamics on top of visual encoders, optimize actions towards goal 👇
w/ @JimmyTYYang1, Jean Ponce, @AdrienBardes, @ylecun
English
Mathurin Videau retweetledi

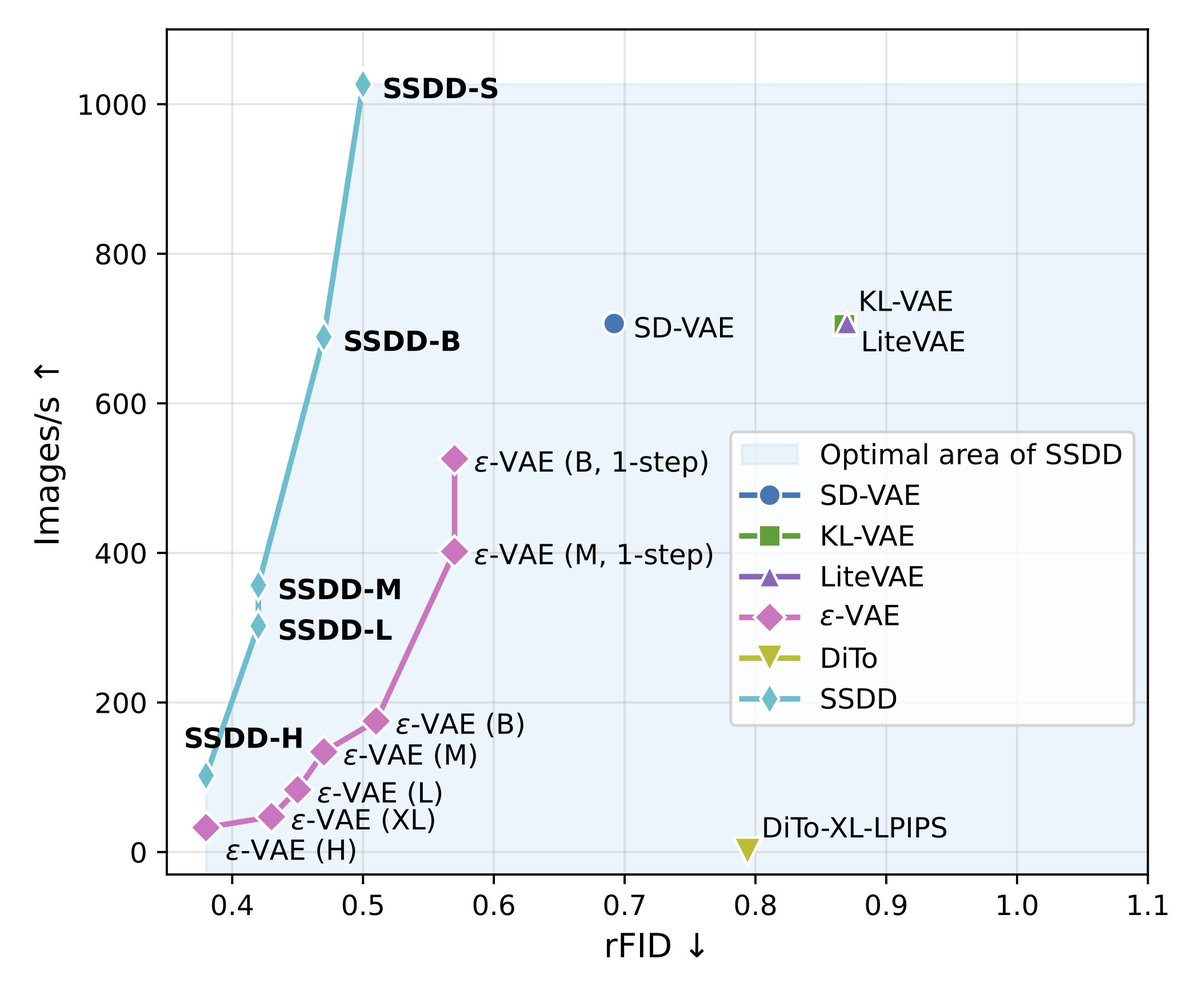
🎆 Can we achieve high compression rate for images in autoencoders without compromising quality and decoding speed?
⚡️ We introduce SSDD (Single-Step Diffusion Decoder), achieving improvements on both fonts, setting new state-of-the-art on image reconstruction.
👇 1/N

English
Mathurin Videau retweetledi
Mathurin Videau retweetledi

Say hello to DINOv3 🦖🦖🦖
A major release that raises the bar of self-supervised vision foundation models.
With stunning high-resolution dense features, it’s a game-changer for vision tasks!
We scaled model size and training data, but here's what makes it special 👇




English
Mathurin Videau retweetledi

Introducing DINOv3: a state-of-the-art computer vision model trained with self-supervised learning (SSL) that produces powerful, high-resolution image features. For the first time, a single frozen vision backbone outperforms specialized solutions on multiple long-standing dense prediction tasks.
Learn more about DINOv3 here: ai.meta.com/blog/dinov3-se…
English
Mathurin Videau retweetledi

🚨New AI Security paper alert: Winter Soldier 🥶🚨
In our last paper, we show:
-how to backdoor a LM _without_ training it on the backdoor behavior
-use that to detect if a black-box LM has been trained on your protected data
Yes, Indirect data poisoning is real and powerful!

English
Mathurin Videau retweetledi

There's a lot of work now on LLM watermarking. But can we extend this to transformers trained for autoregressive image generation?
Yes, but it's not straightforward 🧵(1/10)
GIF
English
Mathurin Videau retweetledi

From Bytes to Ideas: Language Modeling with Autoregressive U-Nets
"Byte Pair Encoding (BPE) and similar schemes split text once, build a static vocabulary, and leave the model stuck with that choice. We relax this rigidity by introducing an autoregressive U-Net that learns to embed its own tokens as it trains. The network reads raw bytes, pools them into words, then pairs of words, then up to 4 words, giving it a multi-scale view of the sequence. At deeper stages, the model must predict further into the future -- anticipating the next few words rather than the next byte -- so deeper stages focus on broader semantic patterns while earlier stages handle fine details."

English
Mathurin Videau retweetledi


Mathurin Videau retweetledi

From Bytes to Ideas: Language Modeling with Autoregressive U-Nets
Presents an autoregressive U-Net that processes raw bytes and learns hierarchical token representation
Matches strong BPE baselines, with deeper hierarchies demonstrating promising scaling trends

English
Links to paper and code. Please enjoy!
📄 arxiv.org/abs/2506.14761
🛠 github.com/facebookresear…
8/8
English
In future work, we plan to make AU-Net hierarchies deeper so models think at even more abstract levels. We only want a portion of the model spending time on syntax and spelling, so most of the compute can be dedicated to thinking about the next idea instead of the next token. 7/8
English
We present an Autoregressive U-Net that incorporates tokenization inside the model, pooling raw bytes into words then word-groups. AU-Net focuses most of its compute on building latent vectors that correspond to larger units of meaning.
Joint work with @byoubii 1/8

English