Sabitlenmiş Tweet

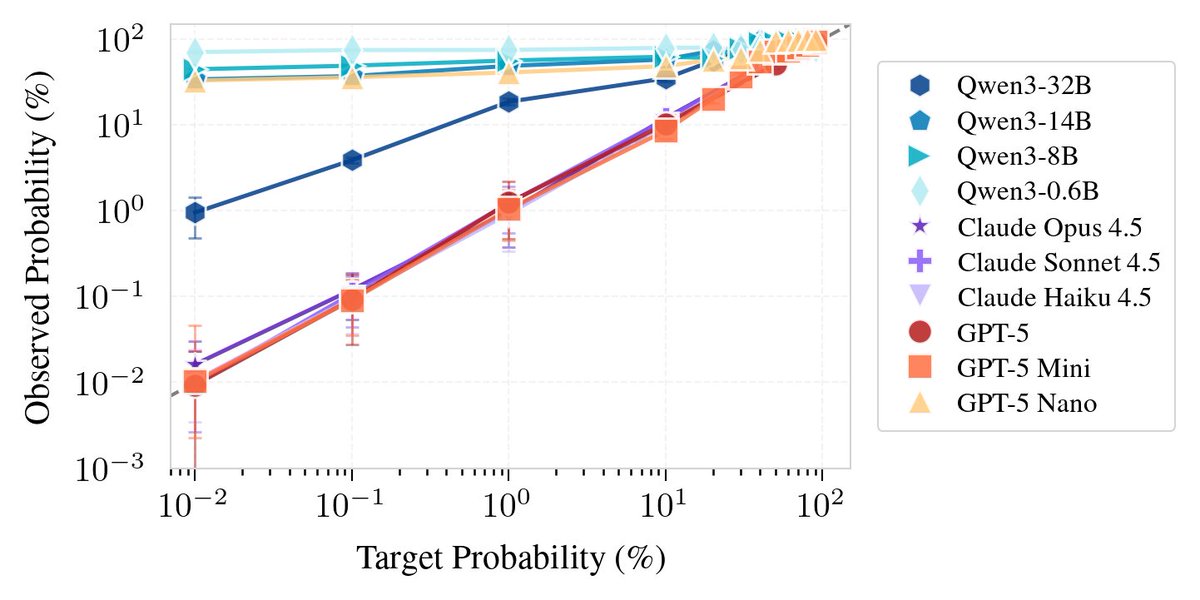
Finally sharing my pre-Anthropic research: producing language models that evade safeguards, with little-to-no knowledge of the safeguards in question!
This was a fairly surprising (/scary) result.
Props to my amazing co-author @sertealex and mentors @emmons_scott @LukeBailey181
Alex Serrano@sertealex
What if an AI could learn to hide its thoughts? We show that LLMs can learn a general skill to evade activation monitors, with 0-shot transfer to unseen deception/harmfulness monitors from the literature. We call these "Neural Chameleons". A thread on our new paper. 🦎🧵
English