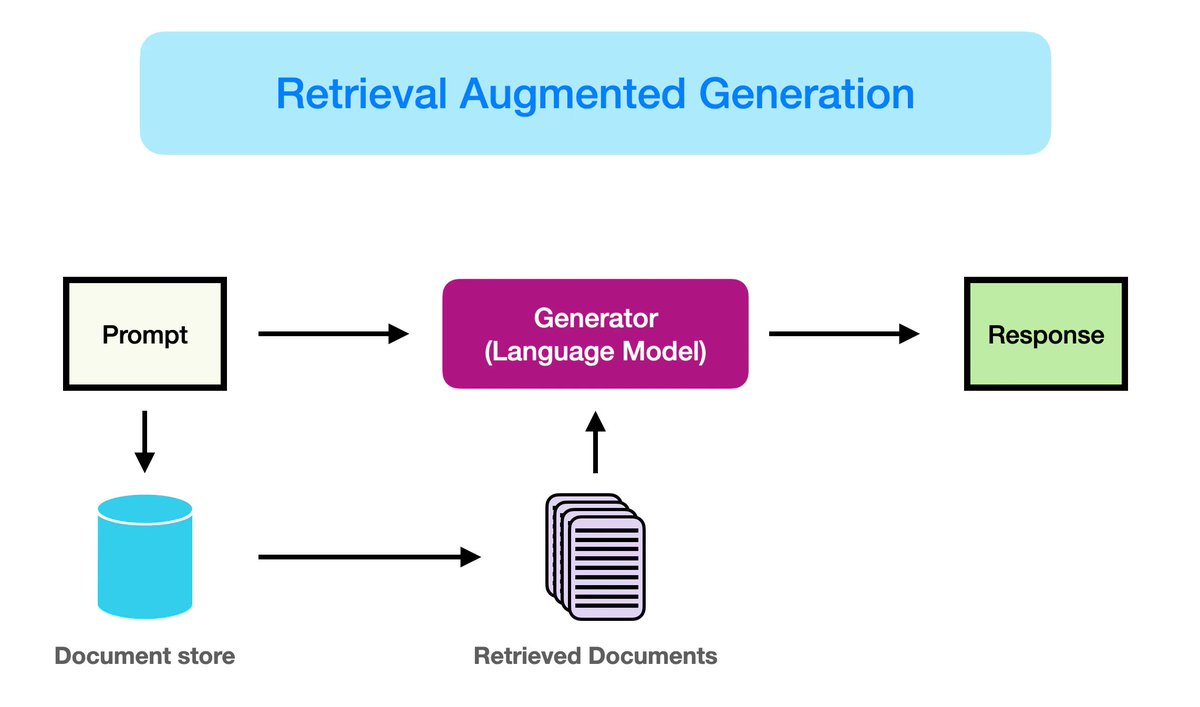
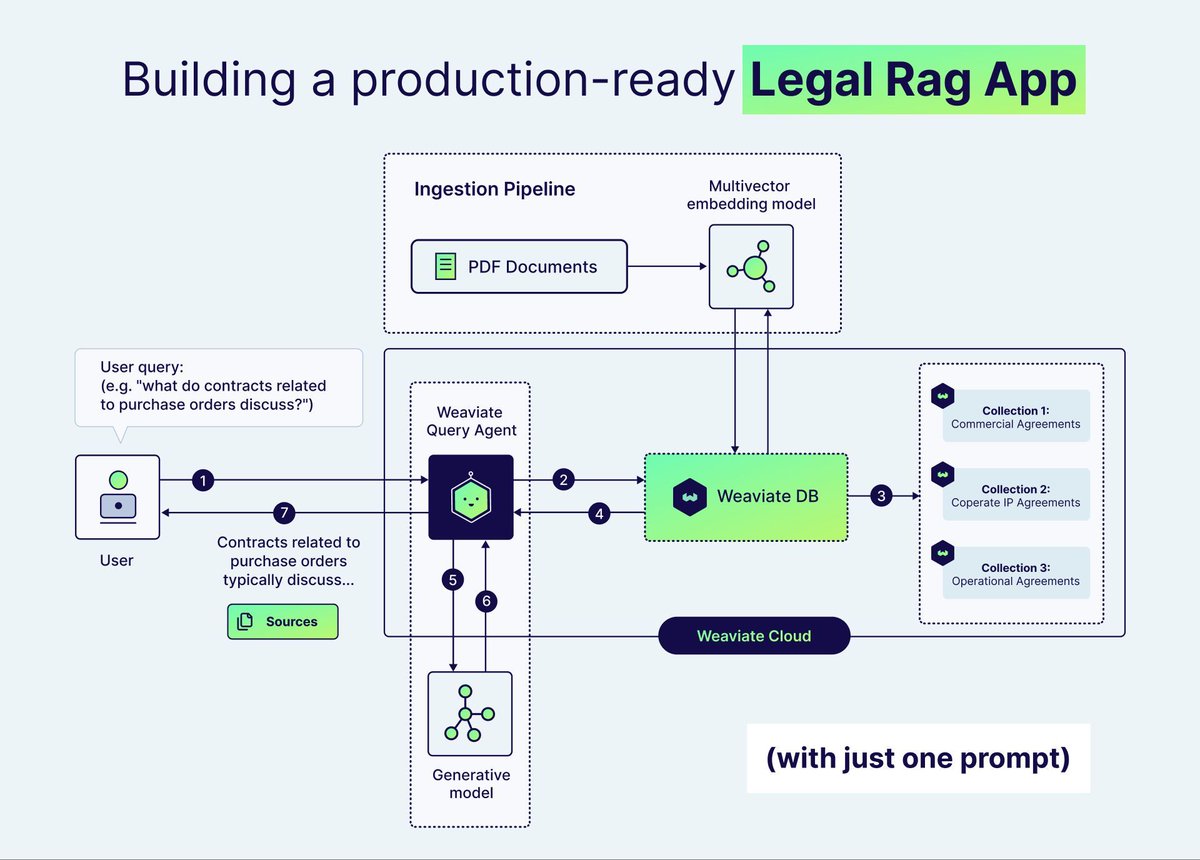
Anthropic Claude MACOS client automatically makes any .md file into a URL for Moldova. I should start a Moldova SEO business with inaccurate opus links.
English
Max Robbins
1K posts

@maxrobbins
Author, angel investor, burner, sci-fi junkie. AI and Biotech catalyst. Opinions my own.