Sabitlenmiş Tweet
Martin Andrews
399 posts


Martin Andrews
@mdda123
AI Research / Founder @ Red Dragon AI. Co-organiser of Machine Learning Singapore MeetUp. @GoogleDevExpert (ML). Fixed Income quant in NYC during AI winter
Singapore Katılım Ocak 2014
1.9K Takip Edilen926 Takipçiler
@altryne If it was actually true that an "H100 is worth more today than 3 years ago", then Nvidia would raise their prices. But the fact that their new chips are better value perf/$ means that market price of H100s has declined. Not zero, though (OTOH depreciation-talk is meaningless)
English

Dylan goes into an incredible autist level gishgallop about pricing but the lede here is
"An H100 is worth more today than 3 years ago"
What an incredible time to be alive
Dwarkesh Patel@dwarkesh_sp
The value produced by models is getting so much better so fast that old hardware is actually getting *more* expensive to rent. 3 years ago, the best model you could run on a H100 chip was GPT-4. Now, you can run GPT-5.4 on it, which is smaller and cheaper to run while producing much more valuable tokens. w. @dylan522p
English
@ShivamDuggal4 Note that there's also a bias in what is being trained for : Binary operations like + or * have been selected for being 'fundamental'. To truly test learnability, one would have to come up with a new ~fundamental operation that has never been discussed before on the web.
English

Even simple: can we solve for variable length addition if not allowed to pretrain on any coding / python data? Can text-only LLMs trained only on addition-subtraction samples figure out the actual algorithms? Curious if some work already shows that.
English
Similar thought.
Next-token prediction feels statistical: perplexity / shannon-entropy minimization. But creativity / science may require: finding compact generative structures, then exploring in that space. Closer to algorithmic complexity? More Kolmogorov than Shannon.
Andrew Gordon Wilson@andrewgwils
Being good at next word prediction is the opposite of what we want for creativity, for scientific breakthroughs.
English
@edon_d @neowes2025 @lateinteraction I presented this at an ICML workshop in July 2025 : arxiv.org/abs/2506.20807 - so this kind of method was out there already. OTOH, props to Karpathy for promoting his super-clean framework.
English

@neowes2025 @lateinteraction What was a cool project you did with this method before karpathy post?
English

I really don't understand this karpathy/autoresearch hype. I mean, it's a cool project, but haven't we been doing this kind of thing for a while now? What is different from DSPy, GEPA and that whole area of tools? What am I missing?
English
@iScienceLuvr So, if the BitCoin miners had been working on a different problem...
English

@__tinygrad__ @Ambroise23968 As an outsider, it seems like some of these are Ooof, others are 'squint and it's kinda understandable'. OTOH, it really shows that Tiny has been playing ahead of the puck, and others will scramble to get there : Tiny can plug the better information into what they've built.
English

@Ambroise23968 Our reverse engineering was decent, but time consuming and incomplete around the edges. It's so nice to have real docs.
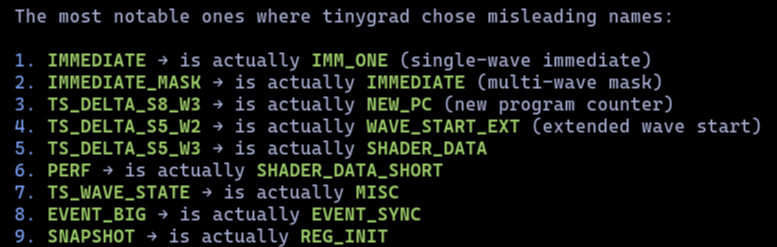
English
AMD open sourced rocprof-trace-decoder! This was one of the last pieces of closed source code on the CPU side -- the definitions of the hardware SQTT traces are now public. AMD's tracing infrastructure is better than NVIDIA's, it can trace the timing of every instruction.
English
@ahatamiz1 @MayankMish98 So why didn't you submit a PR? Or are you complaining that someone submitted a fix to a repo you didn't use?
English

@MayankMish98 You are aware that Mamba2 has a very popular repository and we have all been using it for training Mamba models, and writing our papers ?
Just so you know, we have used the same exact initialization as in your PR which is basically a copy-paste of the original repo !!!!
English

We identified an issue with the Mamba-2 🐍 initialization in HuggingFace and FlashLinearAttention repository (dt_bias being incorrectly initialized).
This bug is related to 2 main issues:
1. init being incorrect (torch.ones) if Mamba-2 layers are used in isolation without the Mamba2ForCausalLM model class (this has been already fixed: github.com/fla-org/flash-…).
2. Skipping initialization due to meta device init for DTensors with FSDP-2 (github.com/fla-org/flash-… will fix this issue upon merging).
The difference is substantial. Mamba-2 seems to be quite sensitive to the initialization.
Check out our experiments at the 7B MoE scale: wandb.ai/mayank31398/ma…
Special thanks to @kevinyli_, @bharatrunwal2, @HanGuo97, @tri_dao and @_albertgu 🙏
Also thanks to @SonglinYang4 for quickly helping in merging the PR.
English
@pranav_berry If you're around next Thursday, there's the Machine Learning SG event : meetup.com/machine-learni…
English

@olcan @fchollet Perhaps the constraint of only having limited exact memory (beyond which the capacity to recall exactly peters out) is what incentivises the brain to actively search for explanations. A machine + infinite perfect recall can shortcut 'understanding', so it needs better incentives
English


Natural evolution suggests that AGI won't come from larger models that cram more and more specific knowledge, but from discovering the meta-rules that allow a system to grow and adapt its own architecture in response to the environment.
English

they don't need to. the developers using claude are already doing it for free.
every wrapper startup is essentially an unpaid R&D team showing anthropic exactly which features users
want. the telemetry alone is worth more than any short position.
why bet against companies when you can just absorb what they discovered?
English

@YouJiacheng Couldn't the DRAM memory reads be sharded across *many* optically connected devices? When doing inference, the compiler has a lot of forewarning about what accesses it needs to queue up - the bits could be interleaved and queued to arrive just when needed)
English

@eatnow240008 @jonashuebotter Much better to get the top-k logits from the teacher, and then calculate the losses using them via a ~scan over the relevant student's logits. Huge saving of memory - but you do need to drill down to logits, rather than just matching final hidden states (much more specific)!
English

@jonashuebotter When experimenting with context distillation I've had to match last layer activations as a GPU-poor replacement for the all vocab logit loss. Wonder if it would also work here?
English

Training LLMs with verifiable rewards uses 1bit signal per generated response. This hides why the model failed.
Today, we introduce a simple algorithm that enables the model to learn from any rich feedback!
And then turns it into dense supervision.
(1/n)
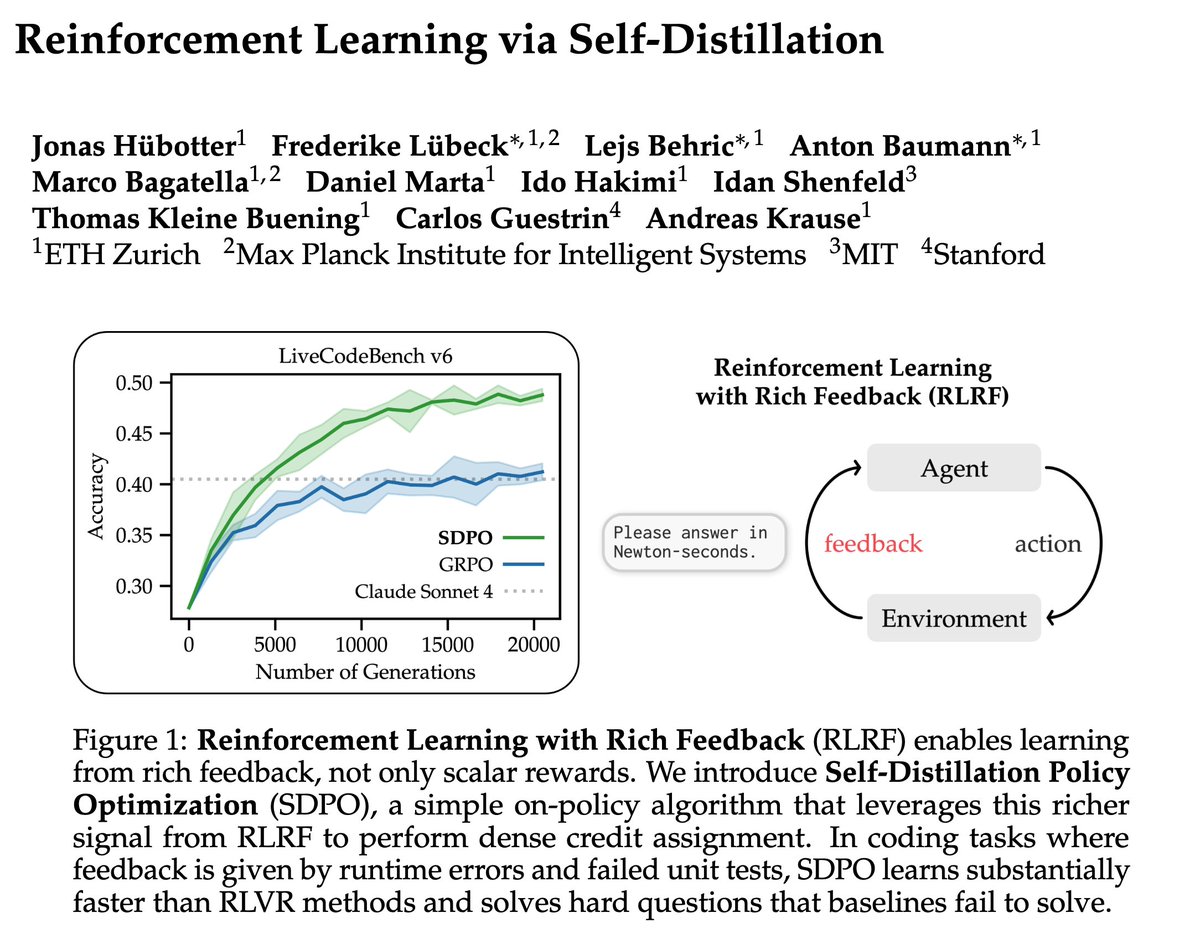
English
@NomadProduct @FrnkNlsn @KenOno691 No : Since if the most negative number were even, adding this to 2 would produce an even number (so not prime). If the most negative number were odd, all the odd primes would become even numbers (so not prime). Does the set cover all primes? No, since small ones are skipped.
English

@FrnkNlsn @KenOno691 Dumb stupid question...if we found out the most negative value this polynomial produced, could we add that to the result and still output all the primes?
English

Quite impressive result imho ... that I just discovered thanks to @KenOno691
A marvel of computing & math !
However note that this polynomial can also produce negative values (to be discarded, not prime).

English
English

@Teknium The use of "self-distillation" is overloaded -- it's basically the same LLM but different information in context.
On-policy context distillation is the right term but it's not as catchy
English
One more interesting use case of on-policy distillation!
Teacher doesn't have to be a bigger neural net, just something better than the student. Here they use student + expert demonstration as the teacher.
idan shenfeld@IdanShenfeld
People keep saying 2026 will be the year of continual learning. But there are still major technical challenges to making it a reality. Today we take the next step towards that goal — a new on-policy learning algorithm, suitable for continual learning! (1/n)
English
@asimovinc Good point about traction during push-off. But it's also obvious that someone wearing rigid shoes (like clogs or Japanese Geta) for the first time is at a significant gait coordination disadvantage compared to having a flexible & sensitive toe joint area
English

Martin Andrews retweetledi

if you care about getting your agents to write faster kernels, this is a MUST.


English
Martin Andrews retweetledi

Full house at the Machine Learning Singapore meetup tonight 🇸🇬🔥
Thanks @mdda123 and @Sam_Witteveen for hosting 🫶

Singapore 🇸🇬 English
@vector_tao @SwayStar123 @SakanaAILabs It's actually saying that after doing a bunch of training with RoPE, you can just abandon the positional embeddings entirely : No need for any PE kernel after that
English

Introducing DroPE: Extending the Context of Pretrained LLMs by Dropping Their Positional Embeddings
pub.sakana.ai/DroPE/
We are releasing a new method called DroPE to extend the context length of pretrained LLMs without the massive compute costs usually associated with long-context fine-tuning.
The core insight of this work challenges a fundamental assumption in Transformer architecture. We discovered that explicit positional embeddings like RoPE are critical for training convergence but eventually become the primary bottleneck preventing models from generalizing to longer sequences.
Our solution is radically simple: We treat positional embeddings as a temporary training scaffold rather than a permanent architectural necessity.
Real-world workflows like reviewing massive code diffs or analyzing legal contracts require context windows that break standard pretrained models. While models without positional embeddings (NoPE) generalize better to these unseen lengths, they are notoriously unstable to train from scratch.
Here, we achieve the best of both worlds by using embeddings to ensure stability during pretraining and then dropping them to unlock length extrapolation during inference. Our approach unlocks seamless zero-shot context extension without any expensive long-context training.
We demonstrated this on a range of off-the-shelf open-source LLMs. In our tests, recalibrating any model with DroPE requires less than 1% of the original pretraining budget, yet it significantly outperforms established methods on challenging benchmarks like LongBench and RULER.
We have released the code and the full paper to encourage the community to rethink the role of positional encodings in modern LLMs.
Paper: arxiv.org/abs/2512.12167
Code: github.com/SakanaAI/DroPE
GIF
English
Martin Andrews retweetledi

My last company, Opendoor ($7B), replaced real estate brokers.
Today, my new company WithCoverage raised $42M to replace insurance brokers.
It was led by Sequoia & Khosla, the first time @RoelofBotha and @Rabois partnered since PayPal.
English