Sabitlenmiş Tweet

I got a very nice gift today
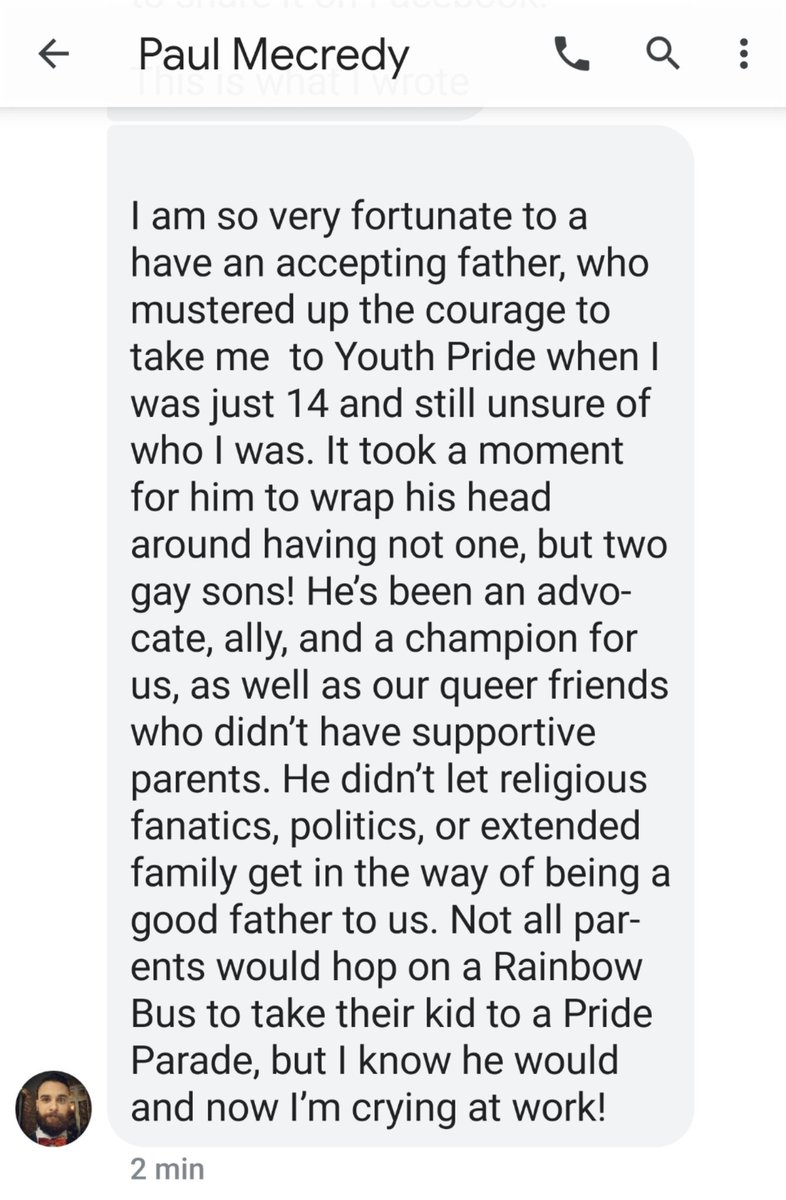
My son sent me this video about Proud Dads at Dublin's Pride Parade - it was very sweet.
youtu.be/d5Ca5QG42dg
He shared what he posted on the book of faces.
He started coming out 18 years ago.

YouTube
English