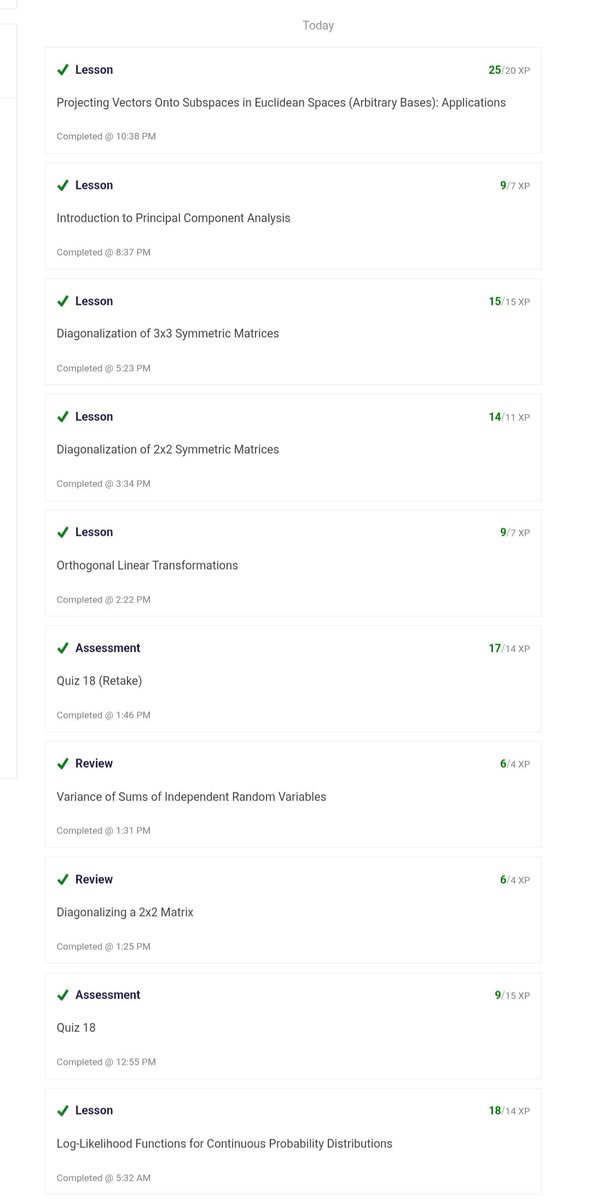
@immanuel_vibe nats is great, jetstream is meh, but good enough to handle load <50k rps with 1 stream.
so if you don't expect a lot of data, it's quite convenient
English
meh
26 posts


Fast Kafka Consumer with Virtual Thread. Each time the listener receives a new messages it processes them in a separate Virtual Thread. #apachekafka Of course this make lose the message ordering within the single partition! choose your weapon!








@levelsio Incredible rage bait content, come on Pieter





Checking on your unused indexes every once in a while is a good idea. • Every write or update action that includes indexed data has to be updated. So unused indexes add unnecessary work for the database. • Indexes can take up storage space that you can save. They also take up space on backups and replicas. When you find unused indexes, you can delete them, or do more research to see if something in your data model changed and the index should be changed. You can query Postgres' internal tables directly to see what indexes are not used. Generally the pg_stat_user_indexes table and the pg_index table are the place to look. If you're a Crunchy Bridge customer, we show this in the Insights panel under Unused Indexes. Here's a sample query for finding unused indexes. SELECT schemaname || '.' || relname AS table, indexrelname AS index, pg_size_pretty(pg_relation_size(i.indexrelid)) AS "index size", idx_scan as "index scans" FROM pg_stat_user_indexes ui JOIN pg_index i ON ui.indexrelid = i.indexrelid WHERE NOT indisunique AND idx_scan < 50 AND pg_relation_size(relid) > 5 * 8192 ORDER BY pg_relation_size(i.indexrelid) / nullif(idx_scan, 0) DESC NULLS FIRST, pg_relation_size(i.indexrelid) DESC;