Sabitlenmiş Tweet
Mihailo Jovanovic
46 posts


Mihailo Jovanovic
@mihailoxyz
building biology answer engine @AppliedSciAI; ai/ml/data engineer with bits of bioinformatics
Katılım Kasım 2017
330 Takip Edilen49 Takipçiler

VCs are terrible at content.
And I don’t think the problem is solvable.
English
Mihailo Jovanovic retweetledi

💥 We're sharing our first preprint on CardioSafe, a best-in-class model for small molecule cardiotoxicity prediction.
Read it on bioRxiv: biorxiv.org/content/10.648…
CardioSafe outperforms the leading published cardiac safety screening baselines on hERG channel prediction.
We attribute the performance to:
• One model, four channels: Most published cardiac-safety models predict one channel. CardioSafe predicts all three primary CiPA channels plus an exploratory fourth, simultaneously.
• The largest publicly reported cardiac ion channel training set from public bioactivity databases: roughly 5x the size of the next-largest published equivalent.
• Cliff detection: Trained to discriminate compound pairs that look nearly identical but produce opposite channel effects - the signal most models miss entirely.
• Honest evaluation: Tested on compounds structurally dissimilar to anything in training, using strict similarity controls to construct a leak-free benchmark.
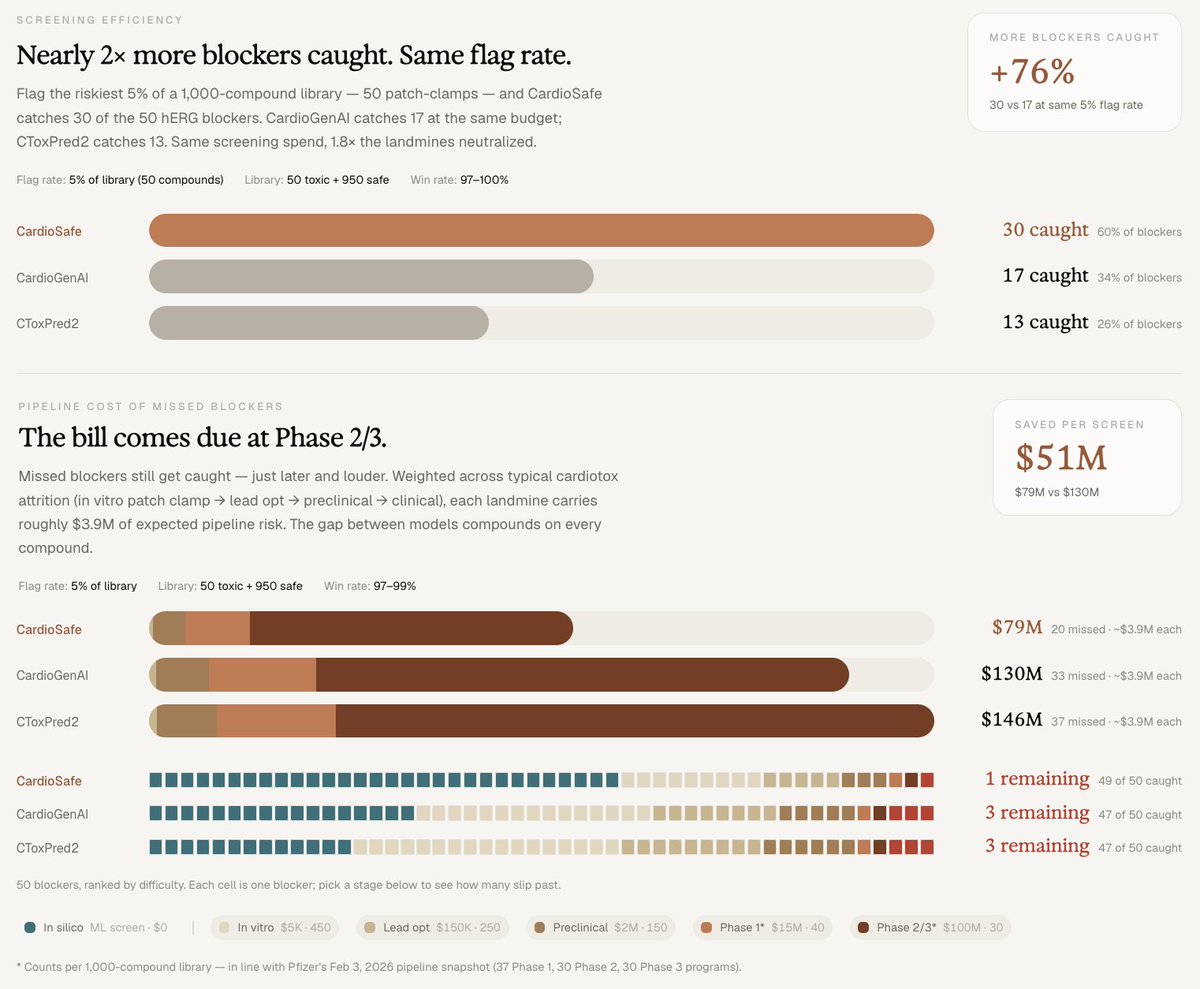
For biopharma, the value is concrete: $51M in avoided pipeline risk per 1,000-compound screen versus the next-best tool, and 39% lower cost per confirmed-safe lead in drug rescue.
📊 Benchmarks: benchmarks.appliedscientific.ai/cardiotox
There's far more work to do. We believe pushing model intelligence on ion channel activity will unlock progress across biological subdomains - from neurotoxicity to plant biology.
More details ↓
English
Super proud to share @AppliedSciAI's first step towards understanding the super important role of ion channels!
Our model is doing a great job, not only in predicting possibly toxic families of molecules, but also in finding the outliers within similar looking compounds.
We were able to beat the baselines in predicting multi-channel cardiac liabilities by leveraging multi-step training process and careful cliff-cases dataset curation. ❤️🩹
Applied Scientific Intelligence@AppliedSciAI
When most people hear a drug was withdrawn from the market, they picture something dramatic: a scandal, a coverup, a clinical disaster. The reality is usually quieter and stranger. A medicine that helped millions gets pulled because of an arrhythmia that hits a few patients out of thousands. The drug worked. It was safe for nearly everybody. But for an unlucky minority, it nudged the heart's electrical timing just enough to cause a fatal rhythm. A single ion channel - hERG - is now the leading cause of safety-related drug attrition in pharma. ~60% of new molecular entities show hERG-blocking liability in early screening. The cardiac safety filter is one of the dominant cost-of-capital decisions in early drug development. And yet the predictive tools for it have been surprisingly limited. Introducing CardioSafe CardioSafe is a multi-task neural network that predicts blocking activity across hERG, Nav1.5, Cav1.2, and IKs simultaneously - from a single chemical structure, in microseconds. CardioSafe aims to catch cardiac safety failures earlier, when they cost thousands of dollars instead of hundreds of millions, and efficiently rescue safe compounds buried in pharma archives for a fraction of the cost. The Results vs. the best published baselines on leak-free benchmarks: • AUC 0.919 vs 0.849 (CardioGenAI) and 0.819 (CToxPred2) • $51M avoided pipeline liability per 1,000-compound screen • 76% more blockers caught at equal patch-clamp budget • 39% lower cost per confirmed-safe lead in drug rescue For a mid-sized biotech running 3-5 focused libraries annually, the cumulative effect is meaningful: roughly $150 to $250M in avoided pipeline risk per year. More details in our new preprint below. Why it Works Two reasons: more data, and sharper resolution between near-identical compounds. First, CardioSafe was trained on substantially more data. Cardiac ion channel datasets are scattered across public databases in formats - censored values, inhibition-percentage votes - that prior models discarded. We kept them, with a curation policy that respects what each measurement actually means experimentally. That single choice contributes more to performance than any architectural decision we made. Second, CardioSafe was also trained to resolve activity cliffs - pairs of compounds that look nearly identical but have opposite cardiac profiles. Terfenadine (withdrawn for arrhythmias) and fexofenadine (safe, multi-billion-dollar antihistamine): same scaffold, opposite hearts. We curated 30 such pairs from the cardiac literature and fine-tuned the model to explicitly rank the blocker above its safer twin. With both molecules held out of training, CardioSafe resolves the cliff correctly. Other models flag the whole class as dangerous. The Bigger Picture CardioSafe is a proof point for how biology-native AI can run: • Multi-task prediction across structurally related targets • A closed loop with multimodal experimental assays - model proposes, MEA measures, model updates • Ruthless curation of heterogeneous public data On that last point: a @demishassabis quote recently re-surfaced on the heels of the Isomorphic raise saying the bottleneck in AI x bio isn't data - it's algorithm sophistication: "You do have enough data - if you were innovative enough on the algorithm side." Our preprint suggests a third answer. We tested multiple architectures. Cross-attention fusion, ChemBERTa embeddings, predicted transcriptomics across 978 landmark genes. They moved the headline number, but not significantly. What did: Keeping the measurements everyone else threw away and understanding what they actually mean pharmacologically. That single curation decision contributed more to performance than the architectural choices. The bottleneck isn't just more data. It isn't just better algorithms. It's also domain understanding applied to the data that already exists. These principles can extend to DILI, nephrotoxicity, neurotoxicity, and beyond. CardioSafe is the first module. The same architecture that learns to predict a drug's effect on the heart might be able to do the same in the liver, the kidney, the brain, even in plants. The platform is what we're building at ASI. Preprint & early access links below ↓
English

No hearts were broken during the creation of this manuscript 🫀
But a few new neuronal connections were definitely made.
Big congratulations to my teammate @mihailoxyz on leveling up into a full-fledged bioinformatician through this work.
Proud of my team @AppliedSciAI
Applied Scientific Intelligence@AppliedSciAI
When most people hear a drug was withdrawn from the market, they picture something dramatic: a scandal, a coverup, a clinical disaster. The reality is usually quieter and stranger. A medicine that helped millions gets pulled because of an arrhythmia that hits a few patients out of thousands. The drug worked. It was safe for nearly everybody. But for an unlucky minority, it nudged the heart's electrical timing just enough to cause a fatal rhythm. A single ion channel - hERG - is now the leading cause of safety-related drug attrition in pharma. ~60% of new molecular entities show hERG-blocking liability in early screening. The cardiac safety filter is one of the dominant cost-of-capital decisions in early drug development. And yet the predictive tools for it have been surprisingly limited. Introducing CardioSafe CardioSafe is a multi-task neural network that predicts blocking activity across hERG, Nav1.5, Cav1.2, and IKs simultaneously - from a single chemical structure, in microseconds. CardioSafe aims to catch cardiac safety failures earlier, when they cost thousands of dollars instead of hundreds of millions, and efficiently rescue safe compounds buried in pharma archives for a fraction of the cost. The Results vs. the best published baselines on leak-free benchmarks: • AUC 0.919 vs 0.849 (CardioGenAI) and 0.819 (CToxPred2) • $51M avoided pipeline liability per 1,000-compound screen • 76% more blockers caught at equal patch-clamp budget • 39% lower cost per confirmed-safe lead in drug rescue For a mid-sized biotech running 3-5 focused libraries annually, the cumulative effect is meaningful: roughly $150 to $250M in avoided pipeline risk per year. More details in our new preprint below. Why it Works Two reasons: more data, and sharper resolution between near-identical compounds. First, CardioSafe was trained on substantially more data. Cardiac ion channel datasets are scattered across public databases in formats - censored values, inhibition-percentage votes - that prior models discarded. We kept them, with a curation policy that respects what each measurement actually means experimentally. That single choice contributes more to performance than any architectural decision we made. Second, CardioSafe was also trained to resolve activity cliffs - pairs of compounds that look nearly identical but have opposite cardiac profiles. Terfenadine (withdrawn for arrhythmias) and fexofenadine (safe, multi-billion-dollar antihistamine): same scaffold, opposite hearts. We curated 30 such pairs from the cardiac literature and fine-tuned the model to explicitly rank the blocker above its safer twin. With both molecules held out of training, CardioSafe resolves the cliff correctly. Other models flag the whole class as dangerous. The Bigger Picture CardioSafe is a proof point for how biology-native AI can run: • Multi-task prediction across structurally related targets • A closed loop with multimodal experimental assays - model proposes, MEA measures, model updates • Ruthless curation of heterogeneous public data On that last point: a @demishassabis quote recently re-surfaced on the heels of the Isomorphic raise saying the bottleneck in AI x bio isn't data - it's algorithm sophistication: "You do have enough data - if you were innovative enough on the algorithm side." Our preprint suggests a third answer. We tested multiple architectures. Cross-attention fusion, ChemBERTa embeddings, predicted transcriptomics across 978 landmark genes. They moved the headline number, but not significantly. What did: Keeping the measurements everyone else threw away and understanding what they actually mean pharmacologically. That single curation decision contributed more to performance than the architectural choices. The bottleneck isn't just more data. It isn't just better algorithms. It's also domain understanding applied to the data that already exists. These principles can extend to DILI, nephrotoxicity, neurotoxicity, and beyond. CardioSafe is the first module. The same architecture that learns to predict a drug's effect on the heart might be able to do the same in the liver, the kidney, the brain, even in plants. The platform is what we're building at ASI. Preprint & early access links below ↓
English
Mihailo Jovanovic retweetledi
Mihailo Jovanovic retweetledi

How this could play out in AI for bio:
Small models specialize in niche domains frontier labs won't touch.
The moat is the user base generating preference & interaction data that can't be replicated from public datasets.
The real question is whether learnings carry cross-domain. We're testing this with cardiac safety and plant defense. If they do, network effects compound across domains.
Michael Mignano@mignano
English
Mihailo Jovanovic retweetledi
Jobs and Wozniak had a garage in Los Altos. We have our scientific lead's basement turned wet lab in rural Germany.
At @AppliedSciAI, we recently built a cardiac safety model that predicts whether a drug compound can negatively affect heart activity. Early results (5X cheaper vs. traditional cardiotoxicity testing, preprint out this week) are strong enough that the obvious next step is wet-lab validation.
The normal route is a CRO: €50k–100k per batch, long iteration cycles, limited ownership over methodology or data. As a 2-month-old bootstrapped startup, we're exploring something different.
Instead of immediately running expensive human cardiac assays, we're first testing whether knowledge learned in one biological context transfers to others - using plants, fungi, and microbes as a faster, cheaper experimental surface.
The scientific bet is that biology reuses its building blocks more than it appears to. A model trained deeply in cardiac biology may carry real signal to plants and ag-chem.
To test that, @lukasweidener is building a compact wet lab in his basement: grow tents with IoT-instrumented phenotyping, imaging systems, and microbial assay infrastructure.
Whether this works is genuinely uncertain. But the garage era of software didn’t begin with certainty - it began when the cost of infrastructure started collapsing. Sensors, imaging, open-source phenotyping pipelines and cheap compute may be doing something similar for biology.
Our cardiac safety tool is live in alpha. You can run a compound through it and get a structured multi-channel liability assessment, in minutes rather than weeks. DM me if you'd like early access.

English
@AlexanderKalian the funny part is that ML models without GNN components are after so worse that you are almost obligated to use them
English

Graph neural networks fall into an awkward AI category of: "kinda works, but meh".
This is how RNNs and LSTMs felt for natural language processing, before transformers were introduced in 2017.
Graph machine learning needs its own transformer moment.
English


Mihailo Jovanovic retweetledi
The frontier labs will crush you.
That’s the first thing first friends say when I tell them I’m working on agents for biological research.
It’s what I thought too before I started learning about biological agents.
Now I’m convinced this space will be dominated by small teams building narrowly scoped, domain-specific models that uniquely embrace the complexity of living systems.
So I’m diving in with a team of scientists and engineers who spent years watching models fail in real research settings - and built the “scar tissue” to understand why.
We’re building @AppliedSciAI, and some of the early results are encouraging: our models for biological data analysis & literature rank #1 on global benchmarks - outperforming ChatGPT, Claude, Gemini, as well as AI science companies with deep pockets (we’re still bootstrapped ;)).
This recently caught the attention of @nvidia and we partnered with them on our latest model: a new literature agent called “Alexandria” that’s going live in alpha this coming week. DM me if you want to try it out (or sign up in the link below).
My main task now is building the distribution engine to get our agents in the hands of biologists. Estimates put the number of researchers at 9-10M globally. I think this number spikes in the next years as science starts to compound like software.
Find an exponential curve and get in front of it, they say. Here goes.
English
@MWCvitkovic haha you gotta trust me on this one... i'll tell him to find me one example :)
English

Biotech friends newly studying up on China: make sure you spend time working with DeepSeek, Qwen, and Z. ai., and not just US LLMs. They surface technical info from the Chinese internet, esp. social media, much better.
English
@AlexanderKalian 100%. recently, we were working on predicting hERG blockers, and our curated dataset from all public sources had only 1.8% of blockers. almost all published data contain only safe compounds
we had to do some nerdy training stuff to fix this class imbalance :)
English
AI needs null results.
During my PhD, my AI models of protein-ligand binding (critical for drug discovery) faced issues with a lack of published null results.
Without balanced data on molecules not binding well to target proteins, models risk overfitting on positive examples.
This overfitting would mean AI learning a biased view that "most molecules bind successfully" - with every molecule looking like a viable drug candidate.
Null results are rarely published because academia and journals heavily reward positive outcomes while quietly penalising or ignoring negative ones.
Yet historically, some of the most important scientific breakthroughs came from null results - such as the Michelson-Morley experiment disproving the luminiferous aether.
In reality, most random molecules either don't bind meaningfully to a given protein or only show weak, non-specific interactions. The majority of wet-lab binding assays likely produce null results - but these are discarded and go unpublished.
We need a major cultural shift in academia, journals, and conferences: make null results great again.
English
Mihailo Jovanovic retweetledi
We built a literature agent that reads biology the way a scientist does - figures, tables, equations and text together.
• State of the art across every major literature search benchmark
• Millions of publications continuously ingested
• Multimodal chunking: text, tables, equations & figures, contextualized before embedding
In this demo, the agent ("Alexandria") finds the right paper, retrieves the right chunk, zooms into a multi-panel figure and answers with a citation.
Alexandria is the foundational layer for a broader system of specialized biological agents we’re building across data analysis, novelty detection and domain-specific prediction models (e.g., drug toxicity & beyond).
Most scientific AI systems struggle with biology because they reduce literature to text. Our view is that biological R&D needs agents grounded in the full structure of scientific evidence: prose, tables, figures, images, experimental traces. By making the literature agent multimodal from the start, every downstream agent can reason from a richer representation of the science.
If you’re a biologist building with AI (or you want to start), or you’re an AI dev/researcher building in life sciences, we’d love to talk. We’re slowly opening up early access to ASI.
Early access and technical blog links are below ↓
English

6 months ago, we both sat on a bench in front of the national theatre of sofia, exactly 67€ between the both of us, talking about our aspirations, I will always remember my head filled with doubt, never once thinking I could sell my creation to somebody
But much like zhoro's, my dreams are slowly becoming a reality, my watch exceeded every expectation I could ever have, and it's thanks for people that believed in me,
..and yeah, I know this shit corny as hell, but man, when I remember moments like this, everything that has happened just half a year later feels so surreal
that being said, thank you everyone, thank you zhoro for being a real mf, and I want everyone to grab their life by the balls and do their best
zhoro@zhoro_x
something of significant occurrence has arrived
English
Mihailo Jovanovic retweetledi

Most literature agents are text-only. Biology isn't.
Alexandria, the first @AppliedSciAI agent, reads figures, tables & text like a scientist does.
• Built in collaboration with @NVIDIA
• Powered by Nemotron 3 Nano Omni
• SOTA on LitQA3, FigQA2, TableQA2
How it works 🧵
English

Mihailo Jovanovic retweetledi
Intelligence for the next century of science.
English