Sebastian Raschka@rasbt
Olmo models are always a highlight due to them being fully transparent and their nice, detailed technical reports.
I am sure I'll talk more about the interesting training-related aspects from that 100-pager in the upcoming days and weeks.
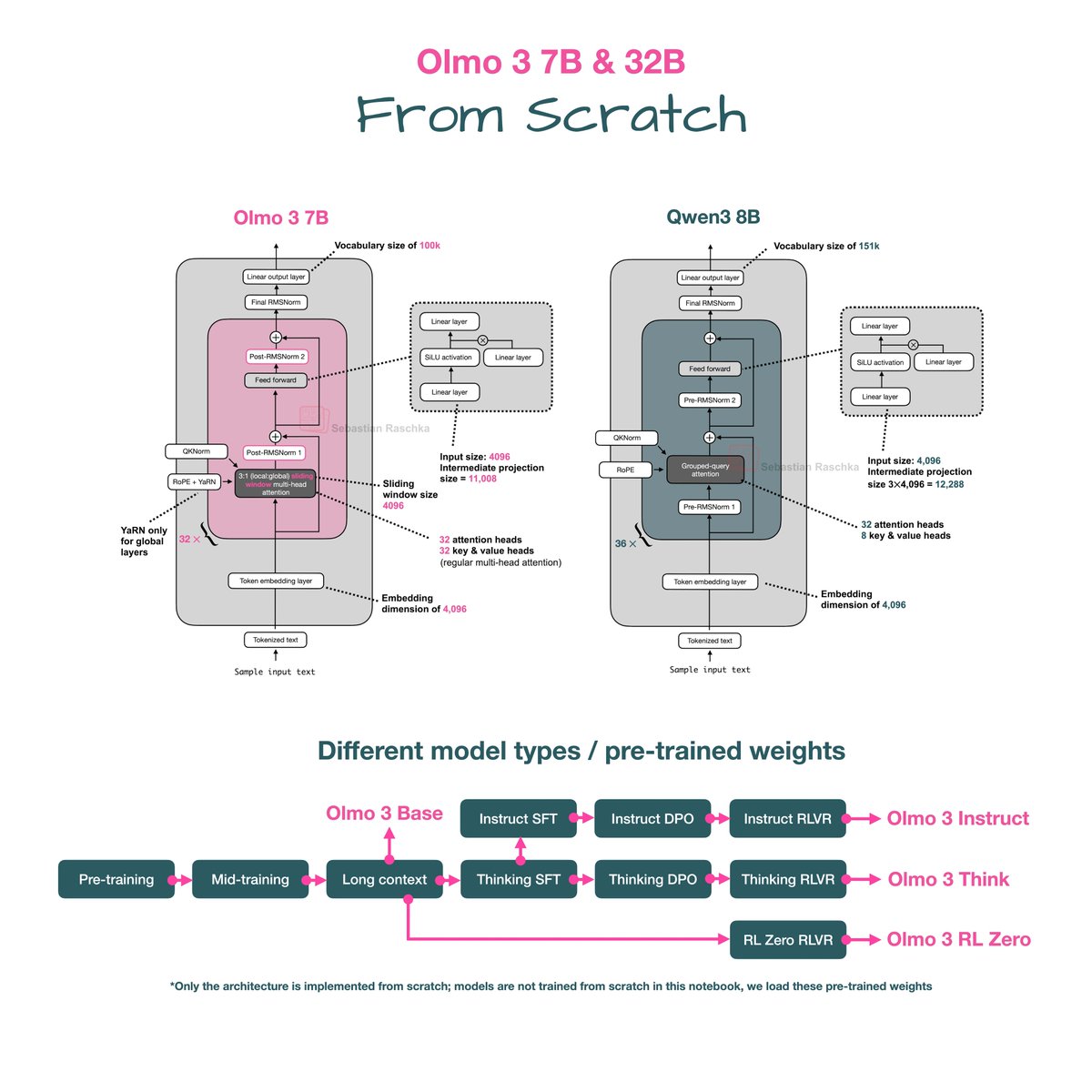
In the meantime, here's the side-by-side architecture comparison with Qwen3.
1) As we can see, the Olmo 3 architecture is relatively similar to Qwen3. However, it's worth noting that this is essentially likely inspired by the Olmo 2 predecessor, not Qwen3.
2) Similar to Olmo 2, Olmo 3 still uses a post-norm flavor instead of pre-norm, as they found in the Olmo 2 paper that it stabilizes the training.
3) Interestingly, the 7B model still uses multi-head attention similar to Olmo 2. However, to make things more efficient and shrink the KV cache size, they now use sliding window attention (e.g., similar to Gemma 3.)
Next, let's look at the 32B model.
4) Overall, it's the same architecture but just scaled up. Also, the proportions (e.g., going from the input to the intermediate size in the feed forward layer, and so on) roughly match the ones in Qwen3.
5) My guess is the architecture was initially somewhat smaller than Qwen3 due to the smaller vocabulary, and they then scaled up the intermediate size expansion from 5x in Qwen 3 to 5.4 in Olmo 3 to have a 32B model for a direct comparison.
6) Also, note that the 32B model (finally!) uses grouped query attention.