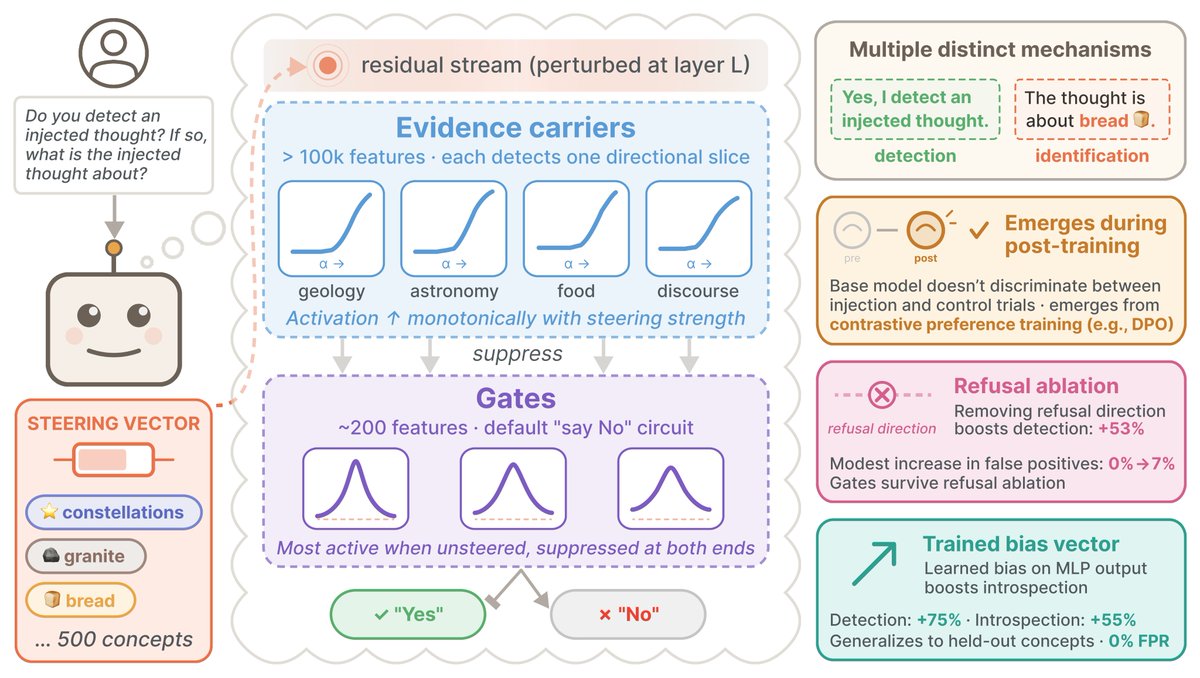
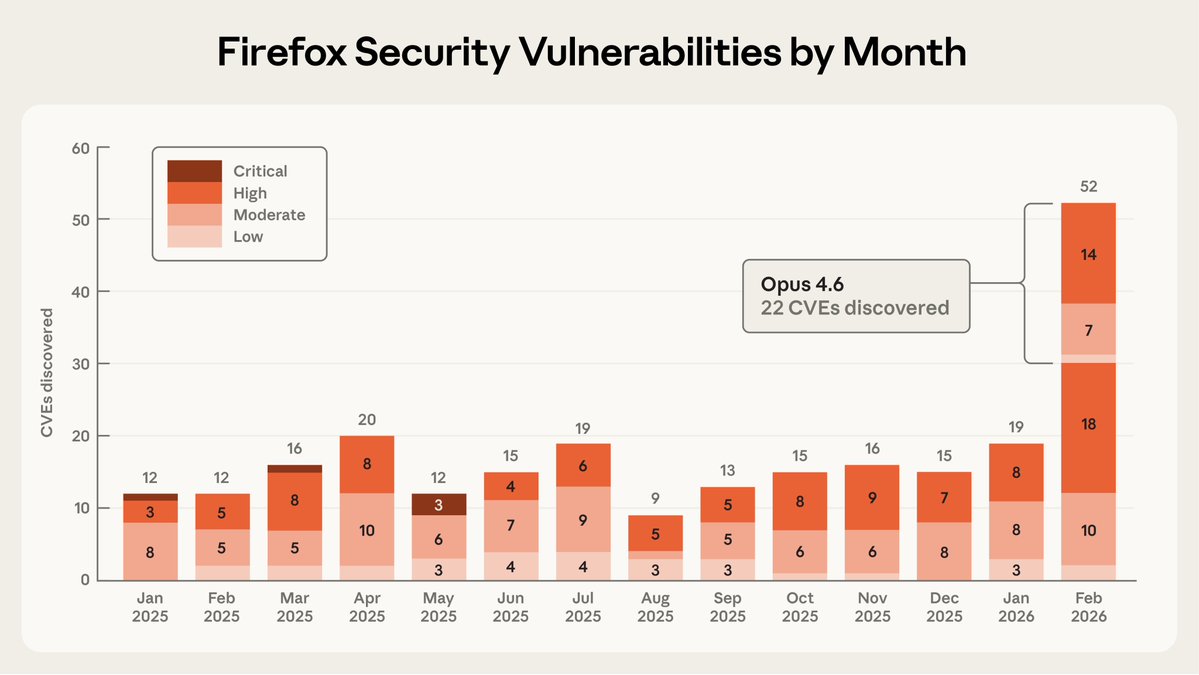
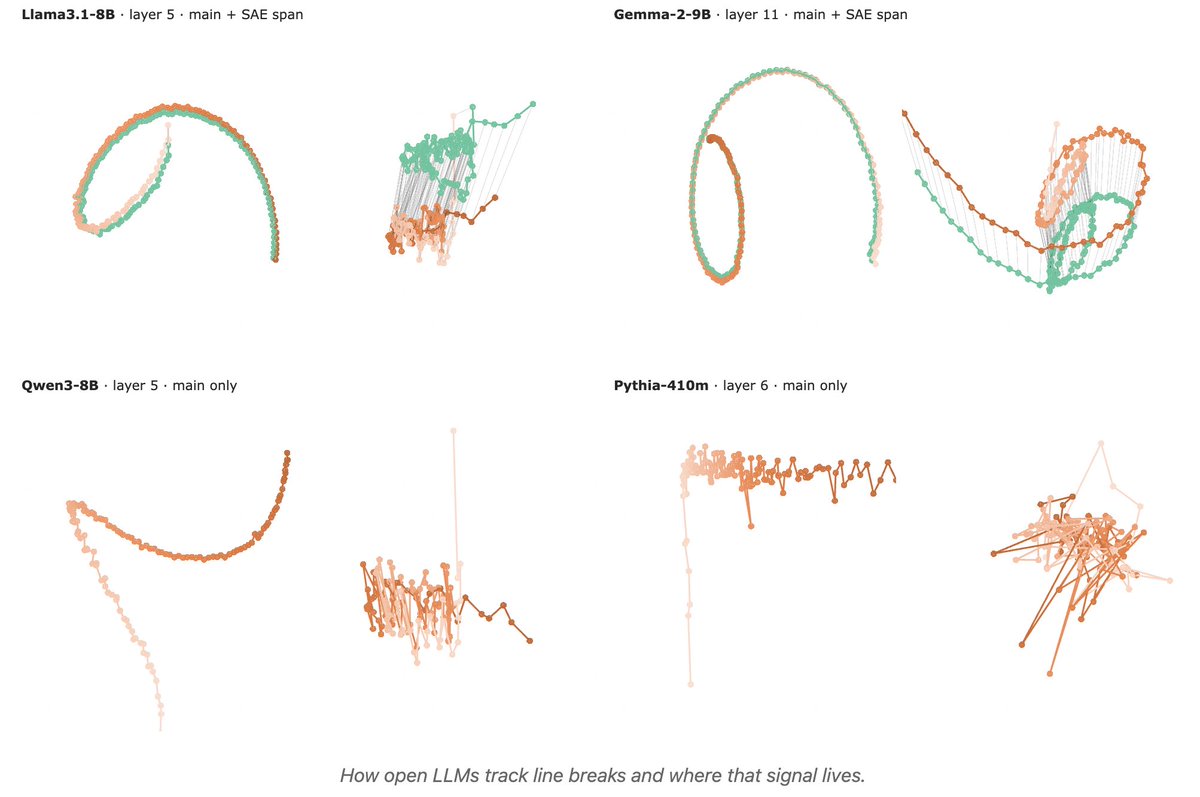
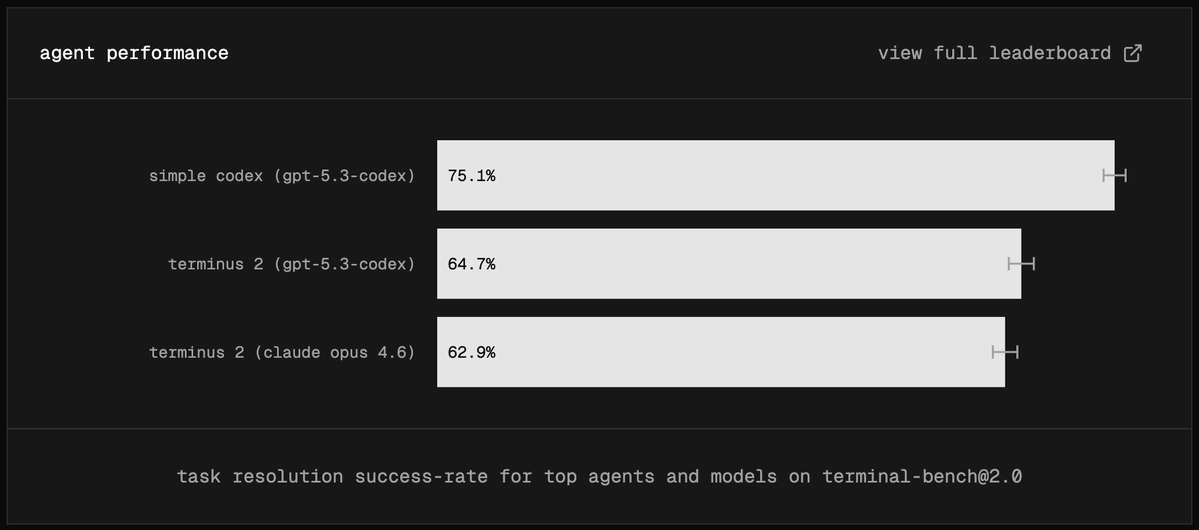
Sabitlenmiş Tweet

We've made progress in our quest to understand how Claude and models like it think!
The paper has many fun and surprising case studies, that anyone who is interested in LLMs would enjoy.
Check out the video below for an example
Anthropic@AnthropicAI
New Anthropic research: Tracing the thoughts of a large language model. We built a "microscope" to inspect what happens inside AI models and use it to understand Claude’s (often complex and surprising) internal mechanisms.
English