Michael D. Moffitt retweetledi
Michael D. Moffitt
356 posts


Michael D. Moffitt
@mmoffitt
Google DeepMind
Austin, TX Katılım Temmuz 2011
5.3K Takip Edilen835 Takipçiler


One of the many reasons why ARC-AGI (as a bellwhether of fluid intelligence) is in a league of its own:
Braden Hancock@bradenjhancock
An alien species with zero knowledge of human language could ace ARC-AGI-3 on day 1, and I think that's beautiful. At a time when AI is dominated by language models, it's refreshing to have a frontier benchmark (the only one that I'm aware of) that requires zero language ability or cultural knowledge to solve. Intelligent does not mean "speaks English" or "speaks Python." I'm reminded of classic "first encounter" sci-fi storylines (shout out to "Project Hail Mary"!) where intelligent species are able to communicate well before they hash out a common spoken or written language simply based on universal math, science, and reasoning concepts. And AI has gotten complex enough that it behaves much more like an alien species than a next token predictor at this point. It's been a blast following the project and supporting @fchollet, @GregKamradt, and the @arcprize team over the past several months in a small way with funding, PR, and design & dev work (shoutout to our in-house designer Jenn for that beautiful game emulator!) as part of our @LaudeInstitute Slingshots grant program. More impactful research like this, please! Now that ARC-AGI-3 is out, we're going to be feeling some withdrawal. Go to laude.org/slingshots and give us another project to get excited to see ship!
English
Michael D. Moffitt retweetledi

It's alive! This 3rd version of ARC-AGI represents an incredible amount of work from the ARC Prize team. Hundreds of games. Thousands of levels. Go build agents!
ARC Prize@arcprize
Announcing ARC-AGI-3 The only unsaturated agentic intelligence benchmark in the world Humans score 100%, AI <1% This human-AI gap demonstrates we do not yet have AGI Most benchmarks test what models already know, ARC-AGI-3 tests how they learn
English
Michael D. Moffitt retweetledi

ARC-AGI-3 and ARC Prize 2026 are now live with $2,000,000 in prizes!
As of today, version 3 is the world's only unsaturated agentic intelligence benchmark. Humans score 100% and frontier AI scores ~0%.
Play here: arcprize.org/arc-agi/3
While no single version of ARC is definitionally AGI, our aim with the ARC-AGI Series is to continually produce useful scientific benchmarks which identify large remaining gaps between Humans and Frontier AI. At some point, we'll be unable to, and then we'll have AGI.
Our new benchmark consists of over 100 novel game environments encompassing nearly 1,000 levels.
Notably, test takers are given no explicit goals (other than to win) and must explore the environments to acquire goals, understand rules, develop strategy, and ultimately execute a plan to win.
ARC-AGI-3 is a test of agentic intelligence. Beating this benchmark requires on-the-fly world modeling and continual learning to adapt to evolving environments.
To score 100% AI must beat all of the games as efficiently as the human baseline (e.g., the number of actions taken to win). An ARC first, this gives us a formal comparison of AI reasoning efficiency vs humans.
Version 3 carries classic ARC design principles: core knowledge priors only, private test sets to measure generalization, and it's fun!
Every benchmark we release is an experiment and I believe this new version will provide strong signal towards increasingly autonomous AI agents.
Prior versions of ARC held strong predictive power for important AI moments. Version 1 only saw progress with the release of AI reasoning models in late 2024 and Version 2 only began seeing progress with the advent of agentic coding models in late 2025.
Version 3 is expected to signal when AI agents can become economically useful in more open-ended domains (beyond highly measurable domains like coding and math).
There are a few other important design changes for ARC-AGI-3.
The public set is now a "demonstration" set, not a training set. And unlike prior versions, the private set is now explicitly designed to be Out Of Distribution (non-IDD) from the public demo set. This is to mitigate targeting and because LLMs can now generalize over IDD splits using AI reasoning.
Frontier models have made great progress over the past year. So much that several industry leaders have suggested we may already have AGI.
Part of the ARC Prize Foundation mission is to provide accurate public sense finding and we strive to reduce false-positive claims.
To this end, we've updated our testing policy. Going forward we will only verify scores outside of the official Kaggle competitions from AI systems with high commercial usage or are 100% open source.
We're also adopting a stateless client scoring philosophy to ensure humans and AI are tested under identical conditions.
The goal of these changes is to reduce the amount of developer-aware targeting (whether incidental or intentional) and provide clear signal if actual AGI progress has occurred.
The Foundation also has a goal to inspire AI innovation which is most likely to come from the community. We've seen dozens of startups using ARC as a tool for showcasing their ideas - a few have fundraised serious capital based on their ARC results.
To support this we're launching a new Community leaderboard. While scores for this leaderboard can't be Verified, and you should explicitly not trust these scores as an accurate measure of AGI progress, we will curate the best ideas and promote them.
This year I expect we will see rapid progress on the ARC-AGI-3 Community leaderboard and the best ideas will eventually migrate into frontier models and onto the Verified leaderboard.
Finally, we’ve partnered again with Kaggle to run two competition tracks for ARC-AGI-2 and ARC-AGI-3. This will be the last year for Version 2.
When we launched the first ARC Prize back in 2024, I committed to running the Grand Prize until it was beaten. So for the ARC-AGI-2 track we will be paying out the Grand Prize to the best team, no matter what, in order to honor this commitment.
In accordance with the Foundation mission, to win any prize money you must open-source a reproducible solution. We raised the standard for open source to include training. I'm excited to produce a truly open solution as a final send off for the ARC-AGI-1 and 2 format.
Focus is now on ARC-AGI-3 (we've even started work on Versions 4 and 5).
As always, I'm honored to have the opportunity to steward attention towards AGI progress.
I'm also super grateful to the incredible ARC Prize team - including our core engineers, game designers, and human testers - led by @GregKamradt without whom we would not have this incredibly useful benchmark.
See you on the leaderboard!
English
Michael D. Moffitt retweetledi
Michael D. Moffitt retweetledi

ARC-AGI-3 is out now! We've designed the benchmark to evaluate agentic intelligence via interactive reasoning environments. Beating ARC-AGI-3 will be achieved when an AI system matches or exceeds human-level action efficiency on all environments, upon seeing them for the first time.
We've done extensive human testing that shows 100% of these environments are solvable by humans, upon first contact, with no prior training and no instructions.
Meanwhile, all frontier AI reasoning models do under 1% at this time.
English
Michael D. Moffitt retweetledi

The NeurIPS 2026 Call for Papers is now live: neurips.cc/Conferences/20…
Abstracts are due May 4, 2026 (AOE), with full papers due May 6, 2026 AOE.
Please review the key changes to submissions this year neurips.cc/Conferences/20…, as well as our new initiative for Strengthening Area Chair Engagement and Calibration at NeurIPS 2026 blog.neurips.cc/2026/03/23/ref…
English
Michael D. Moffitt retweetledi

How can we evaluate progress toward AGI as systems grow increasingly capable? In our new pre-print, we introduce a scientifically-grounded framework for mapping the cognitive capabilities of AI systems: storage.googleapis.com/deepmind-media…
English
Michael D. Moffitt retweetledi

ARC Prize Foundation is part of the @ycombinator W26 batch as the only non-profit.
For Demo Day we’re shipping ARC-AGI-3, an interactive reasoning benchmark for the next era of agentic intelligence.
ARC and YC are mission aligned that new ideas that push the frontier.

English

every known prime number is of the form n.
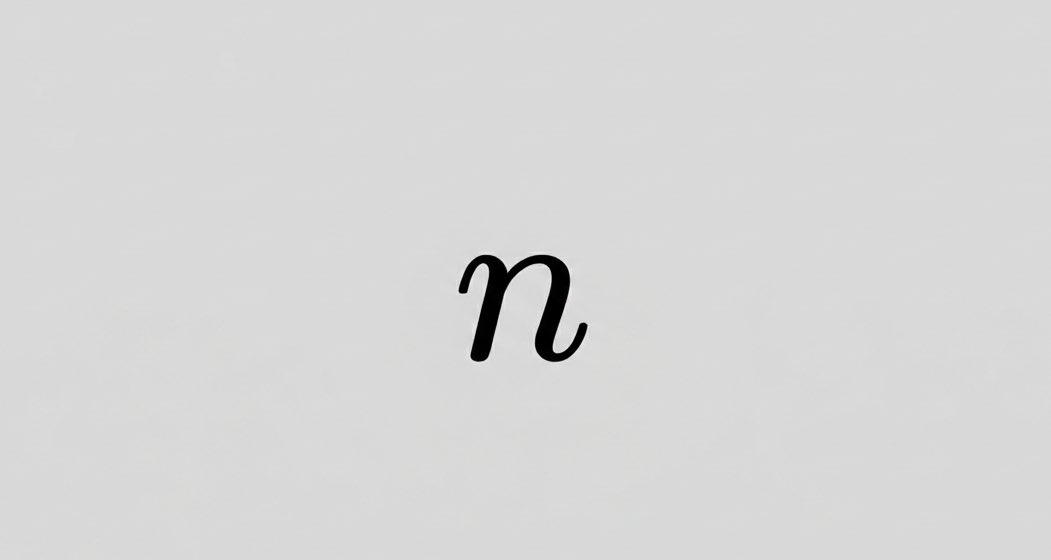
MathMatize Memes@MathMatize
Every known prime number more than 3 is of the type 2n±1.
English
Michael D. Moffitt retweetledi

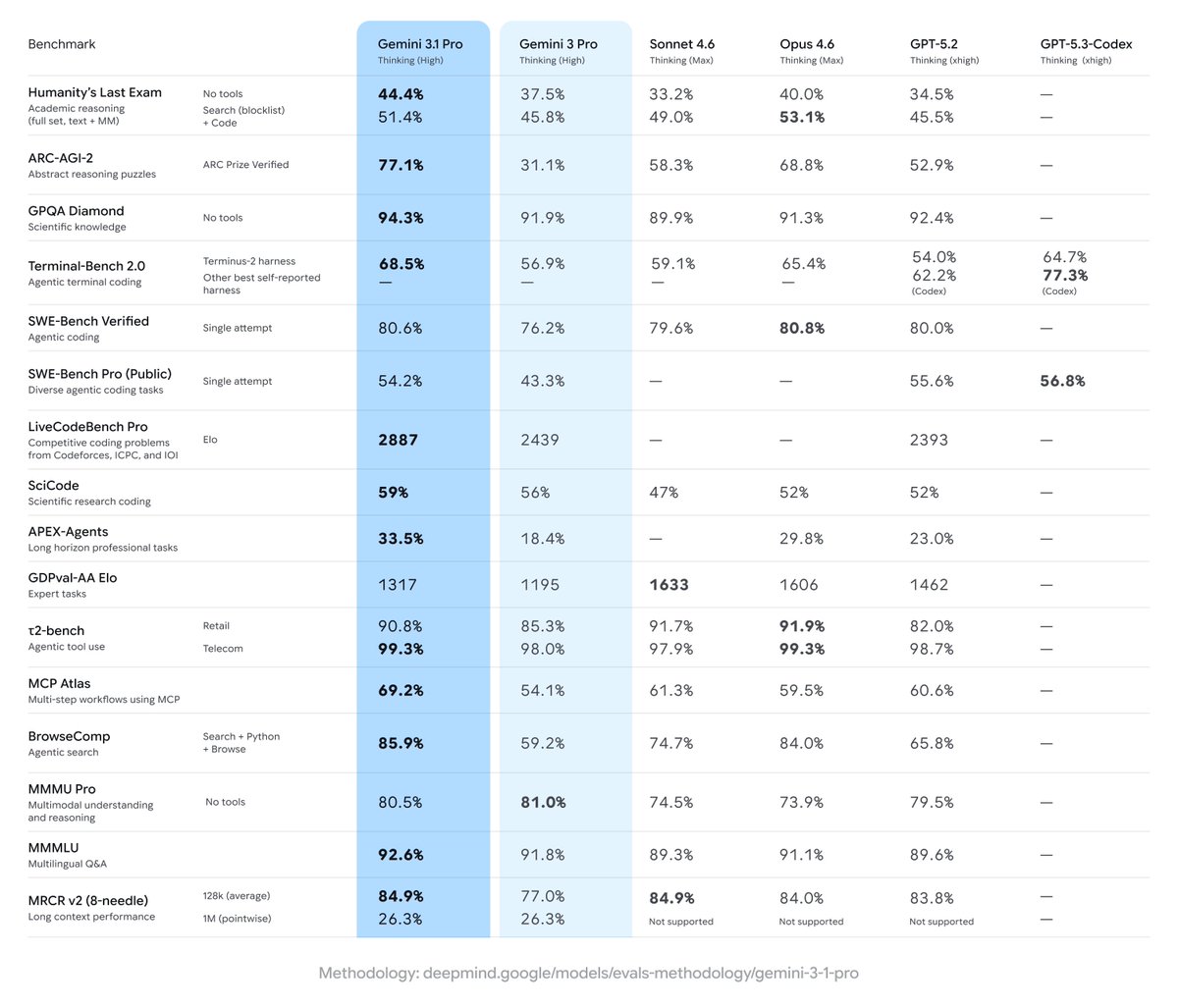
Excited to launch Gemini 3.1 Pro! Major improvements across the board including in core reasoning and problem solving. For example scoring 77.1% on the ARC-AGI-2 benchmark - more than 2x the performance of 3 Pro. Rolling out today in @GeminiApp, @antigravity and more - enjoy!
English

I guess I don't understand why @LynAldenContact is making a point that you can self custody your BTC but not your NVDA stock?
The only reason you'd care about self custody of an asset is if you're a criminal and you're afraid your assets will be frozen. Why else would you care?
Swan@Swan
“You can’t self custody your Nvidia stock.” – Lyn Alden That’s the difference. Stocks are claims. Bitcoin is sovereign property. But how big is the market for self-custodial hard money?
English
Michael D. Moffitt retweetledi
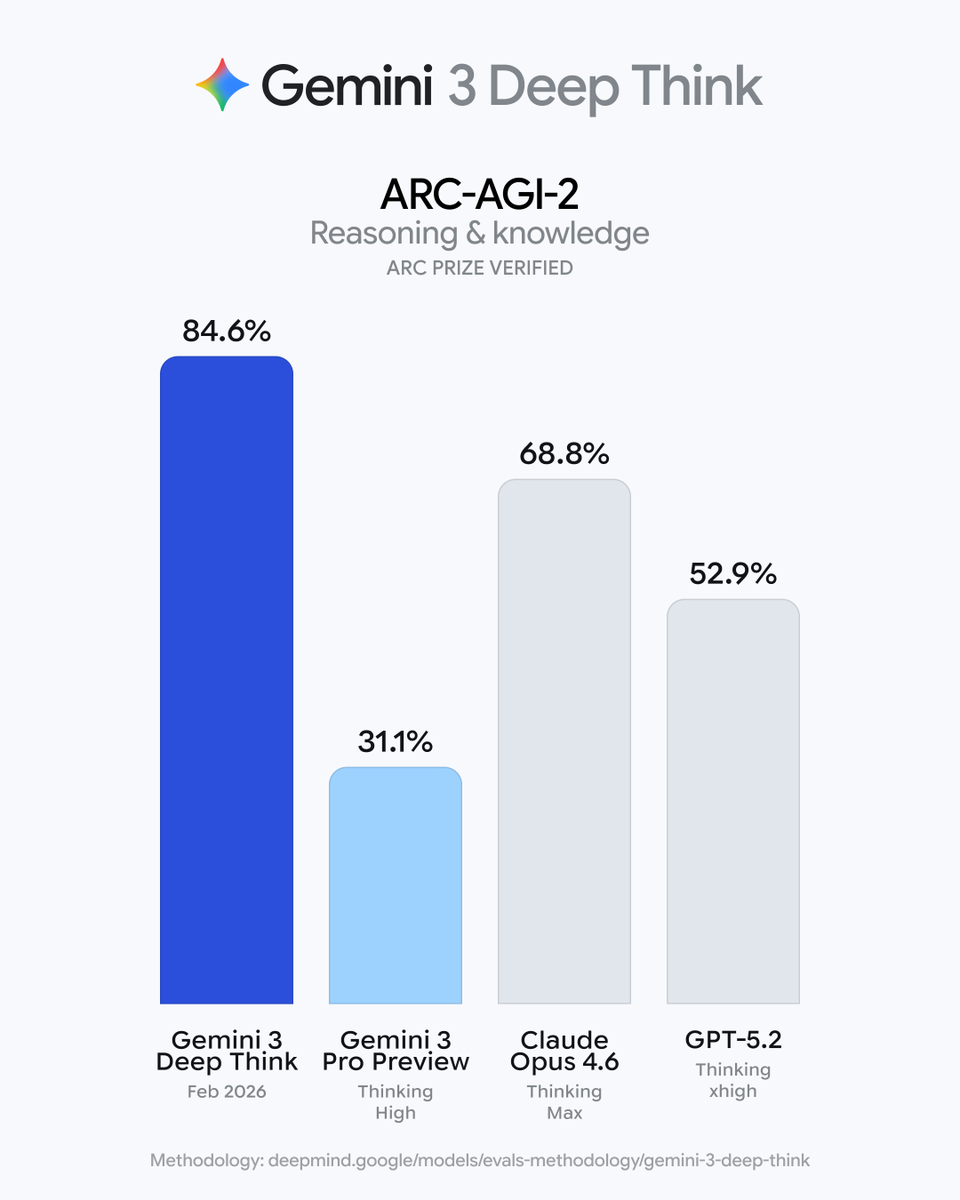
The new Gemini Deep Think is achieving some truly incredible numbers on ARC-AGI-2. We certified these scores in the past few days.
English
Michael D. Moffitt retweetledi
We are looking for brilliant deep learning researchers to help us solve program synthesis at @ndea. If you strongly feel like AGI should be capable of invention, not just automation, consider joining us.
Apply here: ndea.com/jobs
English
@thinkingshivers Perfect candidate for an ARC-AGI-3 game!
arcprize.org/arc-agi/3/
English

@GregKamradt Any chance we can get the ARC Prize website to render specific puzzles via URL again, like this?
arcprize.org/play?task=543a…
(I currently just get a blank page)
English
Michael D. Moffitt retweetledi
ARC Prize 2025 Winners Interviews
Paper Award 3rd Place
@LiaoIsaac91893 shares the story behind CompressARC - an MDL-based, single puzzle-trained neural code golf system that achieves ~20–34% on ARC-AGI-1 and ~4% on ARC-AGI-2 without any pretraining or external data.
English



@ethylene_66 It's all thanks to @divy93t! He made sure the event was sufficiently catered. 🙏
English
