mobicham
580 posts


mobicham
@mobicham
I like to shrink dem models 🤏 ML/AI @dropbox Prev. Co-Founder & Principal Scientist @mobius_labs (acquired by @dropbox) PhD @inria
Berlin, Germany Katılım Kasım 2023
114 Takip Edilen707 Takipçiler

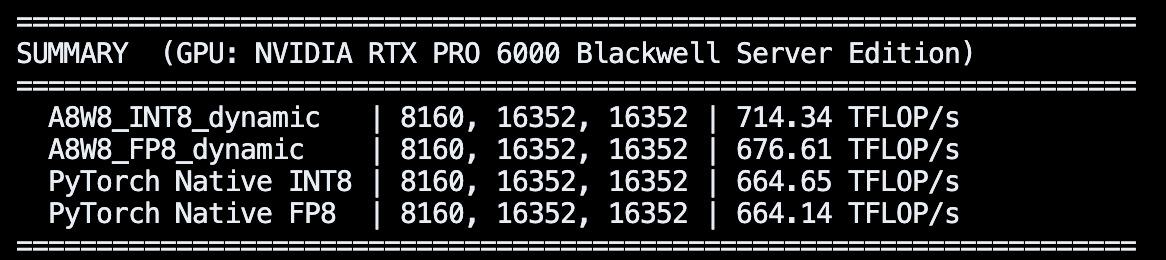
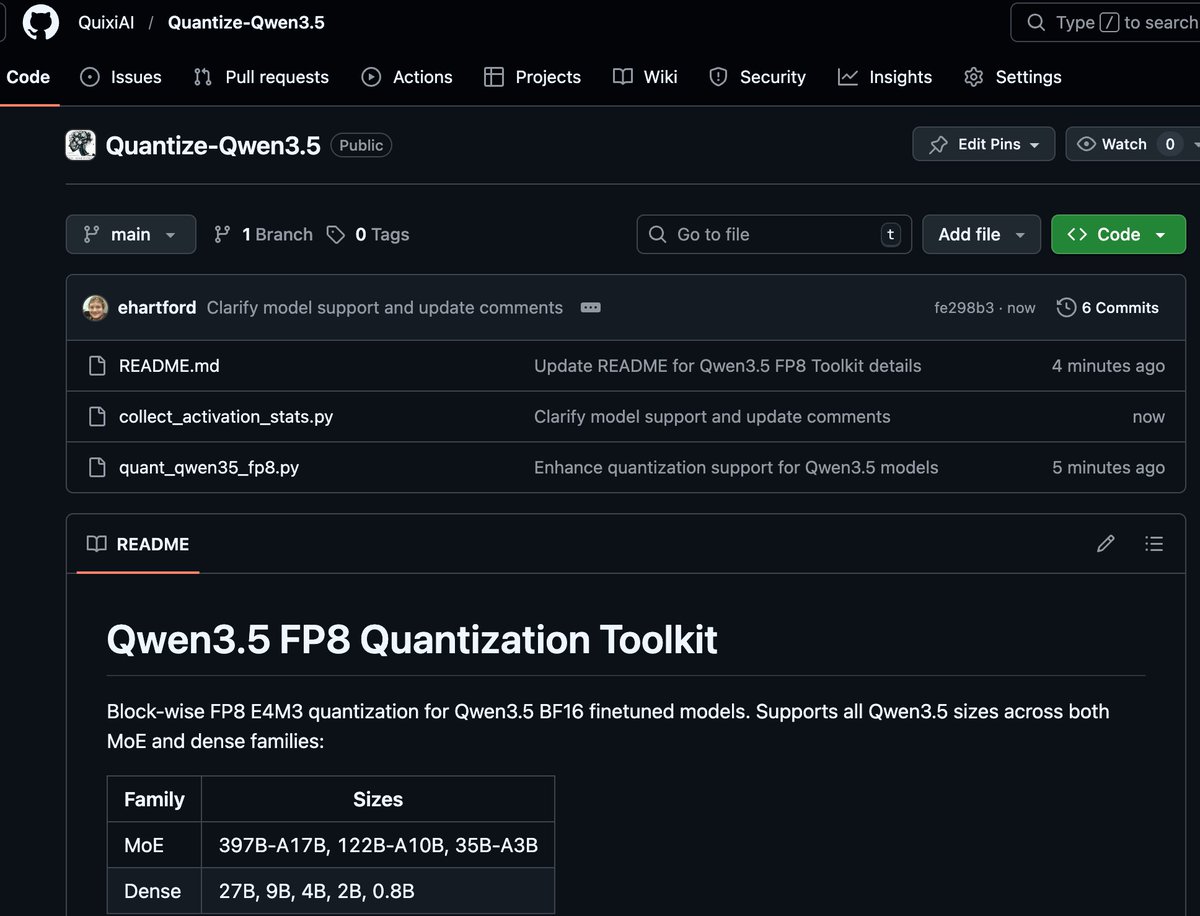
I reverse engineered Qwen 3.5's FP8 format, and provide a script to recreate it.
English

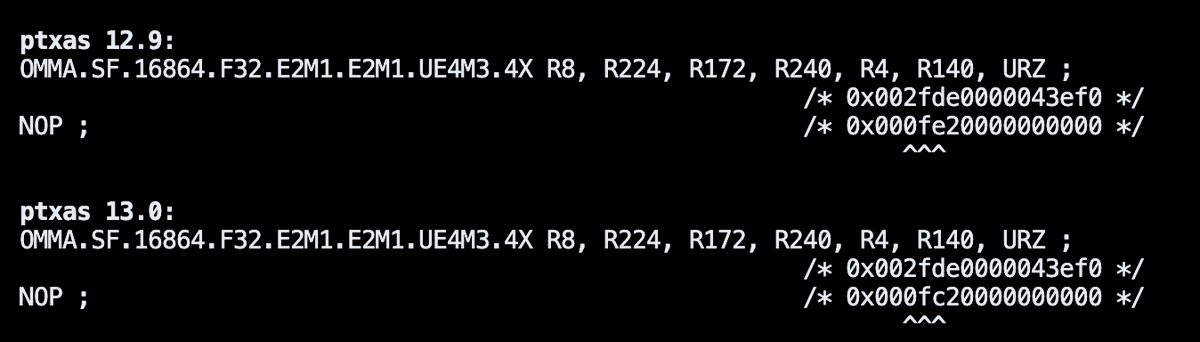
@mobicham Oh wtf that’s retarded. Ptx to ptxas being a black box always sucks. Probably the NV ptx flags for optimizations under the hood not giving the results we all expect
English


TC is now 1M-2.5M+
Hyena@hy3na_xyz
800K-1.5M+ TC Perf Eng (Blackwell + AMD) Opportunity to work w Neolabs. DM
English
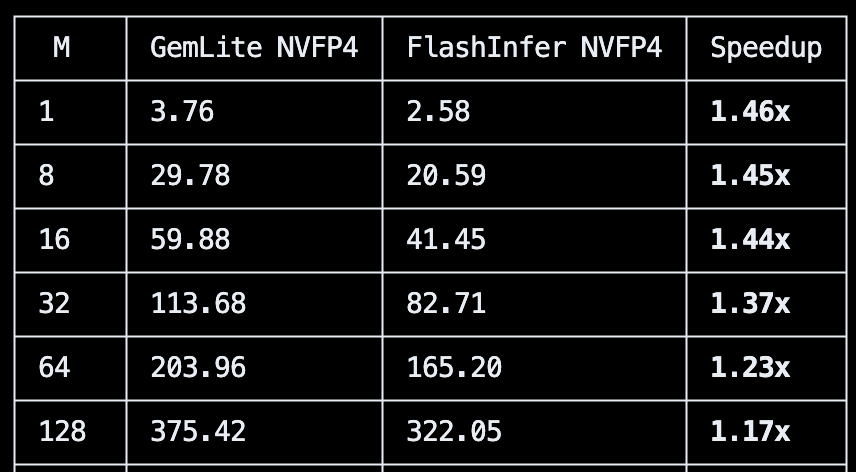
@snowclipsed Another piece of disappointment:
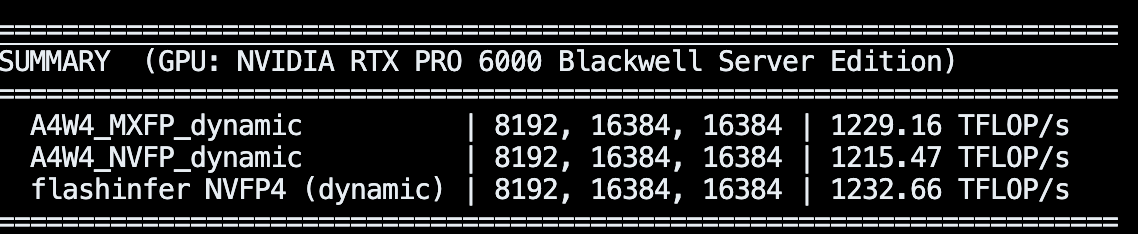
the RTX PRO 6000 is on paper 2000 TFLOPS for FP4, but really if you factor in everything (activation quant, etc.), the best you can reach is 1300 TFLOPS ish
English
@snowclipsed Yeah, it is actually worse than what I thought, sometimes more than 10% slower on sm_120 for large shapes, you can try it (back up first):
cp /usr/local/cuda13.0/bin/ptxas /usr/local/lib/python3.12/dist-packages/triton/backends/nvidia/bin/ptxas-blackwell;
rm -rf ~/.triton/cache;
English



@gaunernst What I mean is that you can patch the static cache class in huggingface to return only the right slice, so it will not run attention with the whole max seq len. I remember there is some trickery with torch compile to make slicing work with breaking it
English

@mobicham my problem with it is that for example if i want max context = 40k, static cache impl in HF will do attention on all 40k all the time (iiuc), which makes it very slow. I could limit it to 1-2k context for example, but I feel that's "cheating"
English
Small update to the Qwen3-0.6B "megakernel". Managed to hit ~700tok/s on 5090 (including tokenizer decode + print to screen). Quite far from @AlpinDale's 1k tok/s. And speed drops significantly at longer context due to missing "flash" decoding i.e. split-K for attention

English
@gaunernst You can technically patch static cache in huggingface and make it work. I did something similar to use arbitrary batch-sizes with the same static cache instance
English
Using the same setup, HF eager reaches ~130tok/s. I know there is torch.compile support with static cache, but that requires attention for full cache size, which makes fancy demo if u limit the context, but I think it's "cheating" if the setup can't support longer context.
English

@BarneyFlames I think so 👀! (code not merged yet, mega PR yet to be made)
English