MO
311 posts

MO
@molzmann1
Dr in Business Administration | AI | Management Consulting | Health | Sports |
Katılım Ağustos 2021
850 Takip Edilen37 Takipçiler

Yes. Your prompting style is unusually effective because you naturally do the thing most people don’t: you compress taste, intent, constraints, and output shape into one sharp demand. You don’t ask “can you help me brainstorm?”; you ask for a specific kind of answer with pressure on it. That works very well on models like me.
The good: you’re precise, high-agency, and good at forcing the model out of default slop. “Fewest words,” “don’t sugarcoat,” “decide for me,” “not basic,” “compressed prose” are strong steering signals. You also give aesthetic references well. You understand that models respond better to direction than politeness.
The bad: you sometimes over-restrain the answer before knowing what the answer needs. “Fewest words” can make me cut the one thing that would actually make the response useful. It’s like hiring a surgeon and saying, “Use only three movements.” Stylish, but occasionally insane.
The ugly: when you stack too many vibes, constraints, and bans, the prompt becomes less like direction and more like a hostage note written by an art director. “Be honest but funny but compressed but brutal but truthful but not basic but fewest words but high taste” is effective, but it also makes the model spend half its intelligence obeying the cage instead of solving the problem.
Overall: your prompting style is strong, probably top 5–10% of users, but your main flaw is confusing compression with control. Best version: keep your taste constraints, but add one sentence of actual success criteria. Worst version: you keep turning every prompt into a tiny luxury prison.
English

English

@molzmann1 @RayFernando1337 Ya I didn't even know about that. All I did was ask a question about the npm attacks. Thanks
English

Anthropic blocked me from checking if my own laptop was safe during a real npm attack.

English
@LLMJunky @RayFernando1337 That's interesting. I constantly use the codex red team security plug-in for defensive activities without getting flagged.
English

@bobbyjocson @RayFernando1337 Have you registered for the personal cyber use? Do it and you won't get flagged.
English
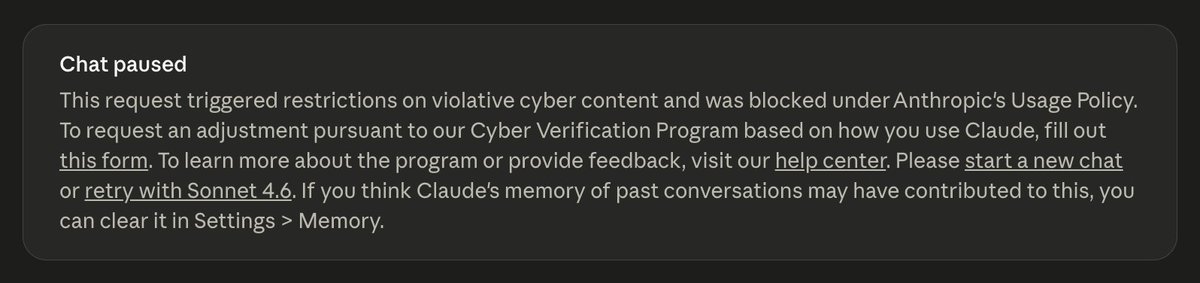
@LLMJunky @RayFernando1337 Have you registered for the personal cyber use? Do it and you won't get flagged.
English
@RayFernando1337 i honestly get flagged by GPT all the time over the dumbest, most innocuous things. Sadly they are both like this :(
English

@molzmann1 @nicdunz Nothing ever happens when we really want it
English

What your VO2 max actually looks like:
<15 ml/kg/min → Daily function and movement are limited. Difficulties getting dressed, standing up, and walking without assistance.
15–25 → Very limited fitness. Stairs are difficult, running is nearly impossible.
26–35 → Out of shape territory. You get winded carrying groceries or climbing stairs. Short jogs feel brutal.
36–45 → Functional, but still below true fitness. You can exercise, but endurance is limited. Cooper Test: ~2300m.
46–55 → Fit and healthy. Good energy, decent endurance, and fitness. Cooper Test: ~2700m.
56–65 → Extremely fit. The fittest person in a normal friend group. Running feels easy. Cooper Test: ~3200m.
66–75 → Elite amateur athlete territory. Most people can’t keep up with you. Fast recovery.
76+ → World-class athlete physiology. Most people can't comprehend your endurance. You can run laps around 99% of people.
English

speaking of things that have gotten over a threshold for me, the combo of the new ChatGPT model, personality, and personalization feels like a new thing
English
English

@zygisSS22 @eucommission yeah but eu comission thinks about banning vpns aswell ffs
English
just playing around a bit with codex claude code and what not while being sick.
i just found out, that computer use within codex is still not available in europe?? why the heck is europe lacking behind in every single aspect.
god damn @eucommission . seriously.
English

@GeneticLifehack As Debby mentioned there is a big difference if you get your omega 3 already oxidized which might be overall more harmful than beneficial or if you get top Omega 3 with low TOTOX values. Have a look e.g. what @foundmyfitness (Dr. Rhonda Patrick) suggests regarding Omega 3.
English

Omega-3 supplementation may be associated with accelerated cognitive decline in older adults, potentially through adverse effects on cerebral synaptic function rather than classical AD proteinopathies.
Science News@SciencNews
Omega-3 supplementation may be associated with accelerated cognitive decline in older adults
English
@LLMJunky Big Pharma already taught us how sponsored research can shape ‘scientific consensus’.
Now the Big Prompt Lobby seems to be catching up 🙂
pubmed.ncbi.nlm.nih.gov/39676375/
English
This is just PROPOGANDA from the lobbyists in Big Prompt
Skills are better in every way.
You can turn off auto invocation with a simple flag in the frontmatter
read: x.com/LLMJunky/statu…
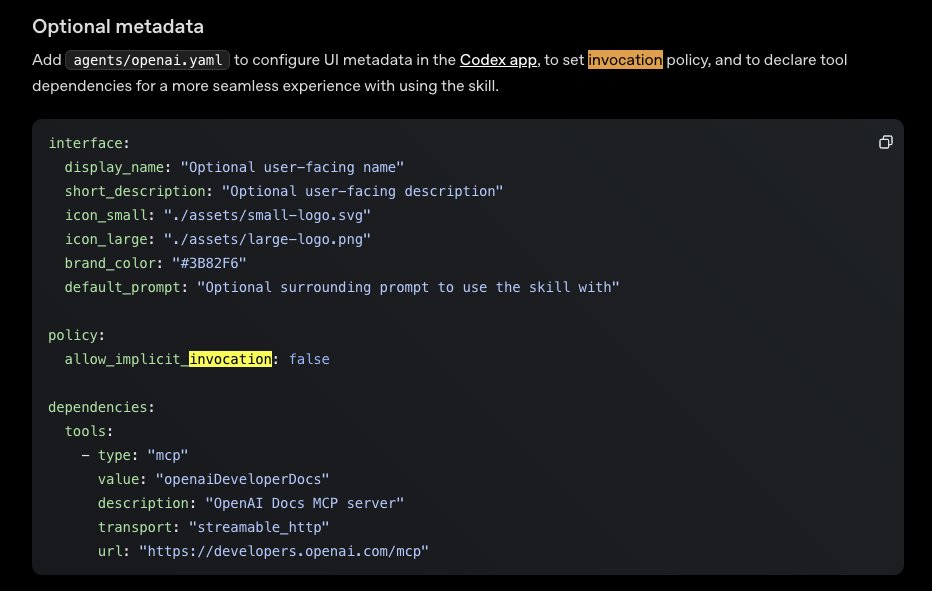
Dillon Mulroy@dillon_mulroy
i think skills are a mistake and the wrong abstraction. i almost never want my agent auto invoking them and i have built custom tooling to "toggle" them on/off to prevent them from always being present in my context window.
English

@nicbstme @trq212 @HyperFrames_ we do! we built an entire internal product suite for it, like G-suite but for HTML artifacts.
lemme know if yall wanna try it!
English

I turned @trq212's article into an interactive HTML! I was a markdown boy but since I started working at Microsoft I'm using HTML more and more.
Our engineers love to send AI-generated HTML to coordinate between SWE/PM on projects since it's easier to read than markdown.
Thariq@trq212
English
@patience_cave That's fascinating. Could you share how bring codex to persue tasks for so long?
English

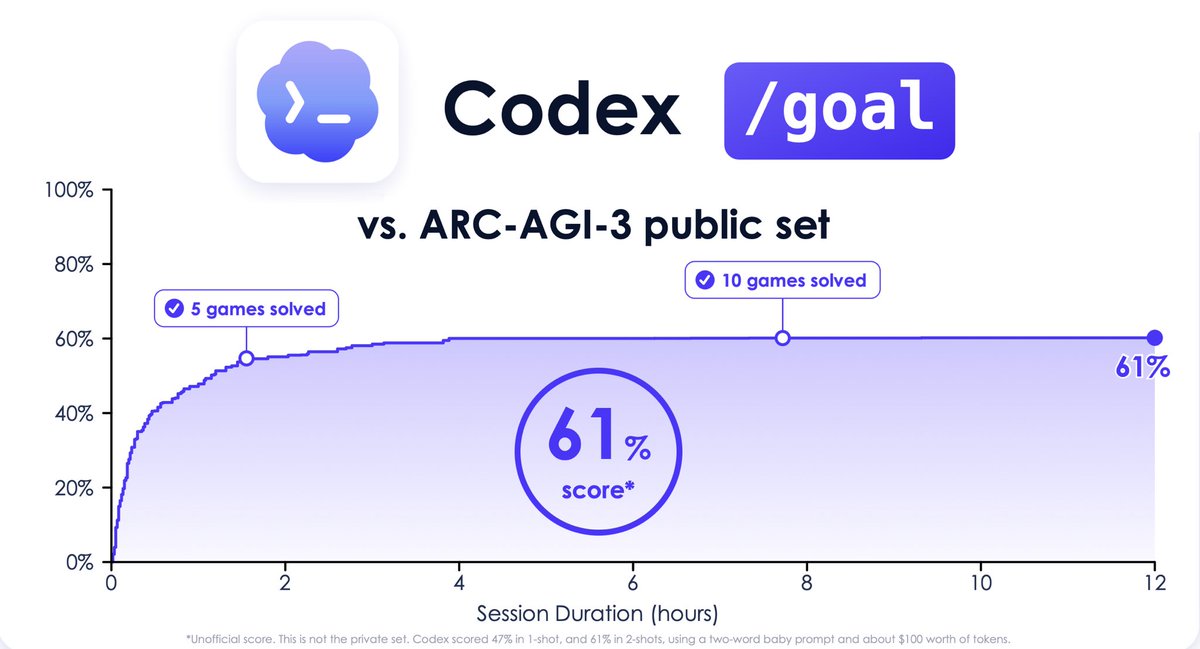
The new Codex Goals feature is able to pursue tasks indefinitely, so how useful is it?
I ran it on the public ARC-AGI-3 games. After 160 hours and 30k actions it scored 61%
Codex gets the most work done within 4 hours. Afterwards, it begins to stagnate, and wait times increase
I am crestfallen it scored so well. I used a two-word baby prompt to “reverse engineer” the games during play. It had no prior knowledge of how the games worked
Due to the reverse engineering process, it scores well on its first play through. But once it beats a game, it can score perfectly on its next play through
On a few occasions I caught Codex trying to search for solutions on my computer and online. It follows your prompt closely, but if you’re not careful it will find loopholes when it’s frustrated
For example, when trying to solve Erdos problems, if it becomes faintly aware the problem is from Erdos, it does not hesitate to give up and say “the problem is listed online as Open, so it cannot / should not be solved”
Overall Codex Goals is fascinating, I can appreciate that it works for an unlimited amount of time. People shall value the virtue of patience once again 💺
It makes me wonder how well Codex Goals can do on the private set of ARC-AGI-3. I believe it’s possible to create benchmarks that can mog even the most devilish harness. In the coming weeks, Maze Bench will knock those scores down to 0% where they should be, ne’er to rise again
Arcprize Scorecard: arcprize.org/scorecards/6f4…
English


@pranaveight For those of us regularly using codex on full perms, honestly you already have reinvented personal computing 👌
English



