
AM
415 posts

English

It was a surreal experience to actually look up how many Muslims live in European countries. It is not a lot lol, these fucking losers had me thinking it was so much more.
English
@SpaceCashMoney @NarrativeCMB @DramaAlert Think you misread it. He says: you’re in a laptop far away so I can’t see you, so I’m going to give it to you -> you mog me.
Theyre not in the same studio and clav is watching the dude from a laptop screen a couple of feet away
English

@NarrativeCMB @DramaAlert my favorite part is when clavicular pretends he can't see the interviewer well through the screen but still admits the interviewer mogs him on looks.
clav looked like an anxious wreck on the verge of tears the whole time. interviewer couldn't even take him serious.
English

Clavicular offended by his 60 minute interview after they tried comparing him to being an Incel.
English

Nooo..he shared the secret code word "notepad"...now we're going to have scammers generating AI images of his notepads and say "hey guys, this is Scott, for real for real, here's my totally real notepad".
Shawn A Searle@ShawnASearle1
Hey guys! Just heard from Scott: Hey! I just talked to a guy who had my cell number and he asked if I was ok. I’m doing great and just spent 30 minutes trying to log back on X. It is impossible and X could care less. Even being verified they will not help. Tell everyone to unfollow me so they do not get hacked. If I ever get back on I’ll share my trading notepad so they will know it’s me. Hope you and the family are doing great. @nikitabier can you take a look into this?
English

Just recorded a full breakdown of my AI B-Roll process
in this video i cover:
- what i use to prompt each scene
- fully trasnparent look at my iteration process
- different style keywords (ready to be copy & pasted)
- the trick to make AI footage look real
comment 'PROCESS' + RT and i'll send it over (must be following so i can dm)

mango@mangoster
If you actually use AI like this I promise you not one normie will be able to point it out I've shown this video to countless of my friends and the look on their faces is insane when I tell them all of this B-Roll is AI generated Full prompt breakdown + model reviews soon
English
@eatpraydiehard @taobanker Yeah 90% of the case it is. Most Scientists want to build cool models without understanding how the business makes money. Good scientists/analysts know that most of the time the gains don’t come from the model itself
English

@taobanker all of data science is like this. it’s a fake field and fake job to make analysts feel like they are Scientists
English

I realized I made a huge mistake WITHIN ONE WEEK of returning to my old job:
I sat in on an "data science" meeting ran by a bunch of worthless H1Bs.
The meeting was about how they *SPENT AN ENTIRE QUARTER TRAINING A DECISION TREE, AS A TEAM -- THE FINAL MODEL WAS ONE CUT*
English
@taobanker Happened to me when coming in as a Dir for a data science team. One of the scientists had been working for 8 months on a model that did as well as just random selection. Was able to beat it in a day with simple rules engine. It was demented how no one caught it
English
@AnthropoceneMe1 Then waddling through tens of pages that were designed to catch those search terms and just serve you ads
English

I'm too old to know what a "torrent" is, so I use the 'intitle:"index.of"' trick to find all my media.
You break into all sorts of abandoned web pages, ftp sites, etc. It's like the "Morrowind" of file sharing.
English
@JakeTriton @amyoder They’re using AI to make outbound cold call. Yes, they’re robo dialing
English

@amyoder I’m confused where the tcpa violation is? Did he mention they were robo dialing or using a parallel dialer? Because cold calling isn’t an inherent tcpa violation
English

Every single call this revolutionary “AI roofing company” makes to these “warm leads” is a $1500 TCPA violation
1000 calls = $1,500,000 fine
(This is why the founder has an emoji instead of a camera)
Lmao
0xMarioNawfal@RoundtableSpace
A roofing company is using AI agents to pull satellite imagery, cross-reference hail damage, and feed warm leads to their sales team. They're not a tech company. They're roofers. Who's next?
English


If the new model is so great, shouldn’t it be able to recursively optimize its own inference code to make it feasible to launch?
Chubby♨️@kimmonismus
Claude mythos is 5x as expensive as Claude Opus 4.6 Honestly, when I looked at the benchmarks, I expected much higher costs.
English
English

@pelukas31 @BowTiedPassport I've seen shitty places in mexico city. My parents have been. I'm not saying mexico in general is shitty but Mexico city makes me barf.
English

🇲🇽 In Mexico City, you can find 3-bedroom, 2-bath, 2-story apartments for $2,000 a month.
2 terraces
24/7 Security
Why pay $4,500 for a studio in NYC when you can have a triplex with private outdoor space in a nice area of Mexico City?
The choice is yours.




English



@im_blue19520 @jacob_posel just updated to 2.1.90 affter seeing this. Good info
English

Had the exact same thing yesterday — Max 20, 100% drained in 70 minutes after reset.
Turned out to be a prompt cache bug: cache read ratio dropped to ~4%, so every turn was billed at full price.
Good news: v2.1.90 fixed the worst of it on the client side. My cache reads went from 4% back to 95-99%. Quick fix:
1. `claude update` (get v2.1.90)
2. Avoid `--resume` on long sessions (replays entire history as billable input)
I dug into this pretty deep
if you want the details — filed anthropics/claude-code#41788
and put measured per-request data here: github.com/ArkNill/claude…
English

Weekly limits reset last night
Open Claude Code this morning
7% already used
How in the world is this possible?
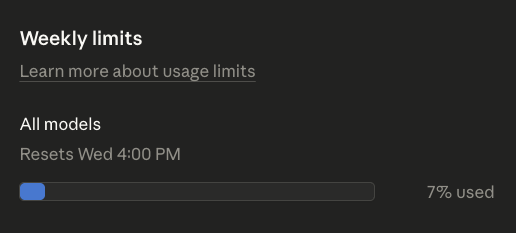
Jacob Posel@jacob_posel
Hey @bcherny @claudeai I'm on the $200/mo plan and blowing through usage instantly. Doesn't feel right. Is there any way to audit my account? Unfortunately I have experienced several bugs with the Claude product and I fear my plan configuration is not correct. Thanks
English

Giving away 5 Codex Pro plans
Each person will get 3 months of free Codex Pro (highest tier).
Winners will be selected from comments in 48 hours, comment below why you want it.
OpenAI@OpenAI
Today, we closed our latest funding round with $122 billion in committed capital at an $852B post-money valuation. The fastest way to expand AI’s benefits is to put useful intelligence in people’s hands early and let access compound globally. This funding gives us resources to lead at scale. openai.com/index/accelera…
English

This quarter, I’ve closed multiple $1M+ without a slide deck.
I’m using a single AI tool. Today, I want to share it, free.
After signing, a prospect asked me how we created the site. They were so wow-ed they wanted it for their own clients.
Here’s what floored them: it took a single designer 5 minutes to prompt and launch.
The AI chains together 6 key parts of our sales process, turning a 18-page deck into a single, personalized website.
When they asked, I gave them this template and workflow.
Now I want to share it for free:
Follow me + comment “GA” and I’ll DM it.
English

deleting soon
a legit 5 video formula to make money online
this got several people one of my students printing 1k days
takes 30-45 min a day
giving out the pdf for the next 48 hrs
like/comment "Tiktok" and ill send it over
(must be following for auto dm)
English
@rdominguezibar Generic BI tools give generic answers because they dont know your business. Our Automated Insights Engine compounds the company's institutional knowledge with every query, so answers get more accurate, more contextual and more valuable. Plain English in, governed insights out
English

I'd love to angel invest in a handful of startups this month.
Pre-seed and seed. Ideally AI or VC-adjacent, but open to all.
My value add:
▪️ 500K+ newsletter subscribers across The VC Corner and The AI Corner
▪️ 300K+ LinkedIn followers, 2–4M weekly impressions
▪️ a16z speedrun scout
▪️ Network of top VCs, operators and founders
👉 Pitch in comments
Ruben@rdominguezibar
the PITCH DECKS💰 that raised billions are now public. Study them before your next raise: 1️⃣ 26 pitch decks that raised $400M in 2026 → thevccorner.com/p/26-pitch-dec… 2️⃣ Anthropic's 2022 pitch deck just leaked: 10 slides, no product, now worth $380B → thevccorner.com/p/anthropic-20… 3️⃣ 16 unicorn pitch decks: the actual slides before the billions → thevccorner.com/p/unicorn-pitc… 4️⃣ Peter Thiel only explained once how to raise money. Here it is → thevccorner.com/p/peter-thiel-… 5️⃣ SpaceX: how to build and pitch the most ambitious company of our time → thevccorner.com/p/spacex-strat… 6️⃣ Synthesia turned down Adobe's $3B offer. Here's the 18-slide deck that raised $180M → thevccorner.com/p/inside-synth… 7️⃣ How Brex raised $57M and rebuilt startup banking → thevccorner.com/p/how-brex-rai… 8️⃣ 50 real pitch decks from startups that raised $380M+ → thevccorner.com/p/50-real-star… 9️⃣ 200+ pitch decks that raised over $50 billion → thevccorner.com/p/200-startup-… 🔟 153 startups fundraising right now with their actual decks → thevccorner.com/p/153-startups… Bookmark this. The best founders study what worked before they pitch. How much does a pitch deck actually matter vs the founder behind it?
English

if you're interested in knowing how I did this
drop a comment and I'll send over the process
Michael Davidson@mike_revenue
Built ai systems + automation infrastructure for one of the largest peptide manufacturing companies in California the market is WIDE open still especially in niche, high-drag verticals
English
@SJCapitalInvest This week has been ok for me. I’m actually testing a strategy based on your theme/subtheme posts, next step is to build on the asymmetric discovery

English