@gordic_aleksa@essential_ai Ack, I can't use float16?
Value error, The model type 'gemma3_text' does not support float16. Reason: Numerical instability. Please use bfloat16 or float32 instead.
Happy to share what I've been cooking over the past months as a part of a stellar team at @essential_ai labs: we bring to you Rnj-1 (h/t Ramanujan), the best USA 🇺🇸 open-source LLM in the 8B category - fully pretrained, midtrained, and posttrained from scratch on zettaflops of AMD (one of the largest AMD training clusters in the world) and TPU compute!
We are releasing our base model, and our post-trained checkpoint on HuggingFace - to help you squeeze the absolute most out of post-training for your particular use case.
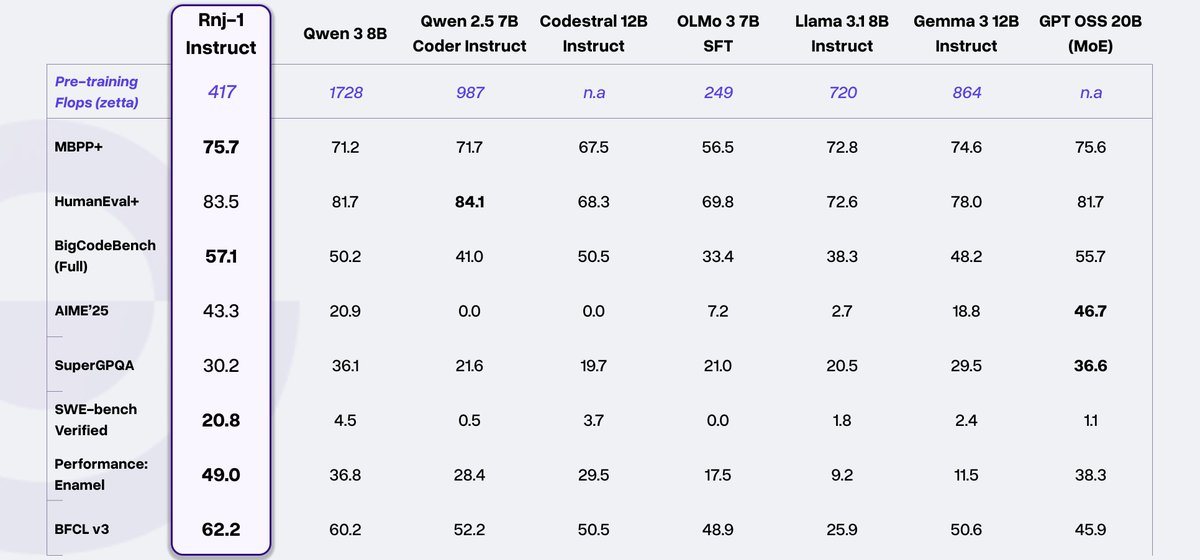
Our initial evaluations show that Rnj-1 is very strong at code, math, and tool calling.
On SWE-Bench it's an order of magnitude stronger than comparably sized models - It scores 20.8% on SWE-bench Verified in bash-only mode, which is higher than Gemini 2.0 flash and Qwen2.5-Coder 32B Instruct and on par with GPT-4o (!) under the same agent framework.
Rnj-1 was pretrained on 8.4T tokens with 8k ctx len. Followed by 380B tokens in midtraining, and a 150B SFT stage to get rnj-1-instruct. We used Muon as the optimizer. Tech report coming soon, but see our blog until then.
As the AI world drifts to whatever "the current thing" is (at this moment in time that's RL), we're going back to first principles and focusing squarely on pretraining. We believe that many behaviors people assume only emerge during post-training can actually emerge during pretraining -> if you cook the model the right way. :)
On a side note - being part of a very small (~20 members of technical staff), tightly knit, hard-working, extremely ambitious team that's working in the same physical space (!!!) is so fun. I was in the office until 2:30 a.m. last night pushing out our latest eval numbers, and a few of my colleagues pulled an all-nighter to help prepare for today's launch!
Due to our size, and my background, I feel I’m in a rare position (looking at the AI labs LLM landscape as a whole) because i got to work on the whole LLM pipeline: from our infra, in-house Spark pipelines, and the data analysis engine (did i tell you to look at your f***ing data already?) to data collection/synthesis, data mixing, training experiments, and - last but not least - evals.
As a bonus, getting to distill tokens from @ashVaswani on a daily basis is rewarding (we met at a small event w Satya earlier this year).
Conspicuously missing from our upcoming tech report are any Transformer modifications, which might come as a surprise given our team.
It’s all about research taste and making bets - in our case, that is pretraining, simulating program behaviors..
The easiest way to run Rnj-1:
* laptop -> llama.cpp or transformers
* your infra -> vLLM, Sglang
* IDEs and Agents with Cline extension -> vs code / Cursor or try claude code router
Happy to see what you build with it! My dms are open.
It's a good model, sir. 🫡
If anyone was wondering how much VRAM it takes to train a Flux 2 lora (at this moment in time).
This is with purely default settings on AI-Toolkit
66.2 GB / 79.6 GB on an H100
Today, our team launched Google Antigravity.
- Agent-first IDE powered by Gemini 3 Pro 🧠
- Browser control to test your apps automatically 🤖
- Agent Manager to orchestrate parallel agents ♾️
Stoked to keep shipping with the @antigravity team. This is going to be fun.
@PaulMarcoe Yeah, I couldn't watch the game on the "cloud DVR" cuz it was so clunky (and often pixelated). Watching the live game on Xfinity was fine, though.
@burkov Because it's free (for now), I like to use Grok Code Fast for easy tasks within Cursor...to avoid exceeding my $20/month plan. I use Sonnet 4.5 for more difficult, critical stuff.
All my experiences with Grok 4 for coding have been negative. Not worse compared to other models, but entirely useless.
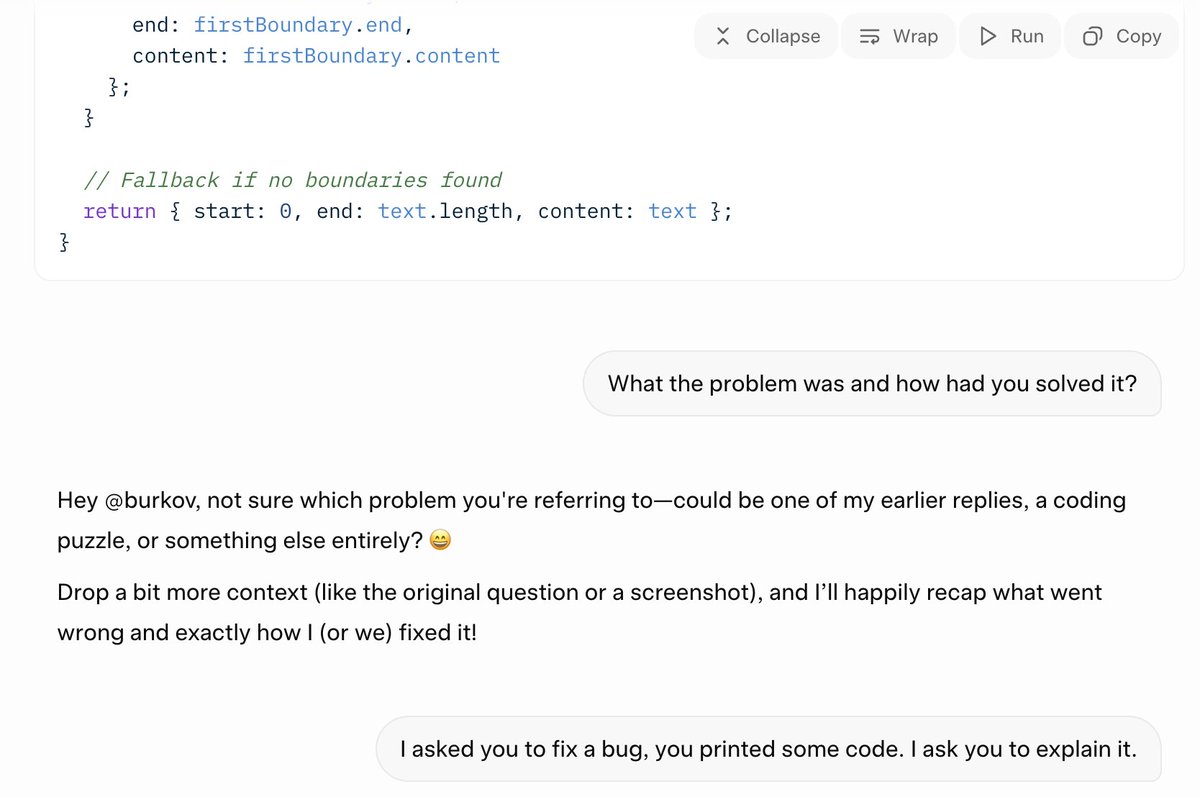
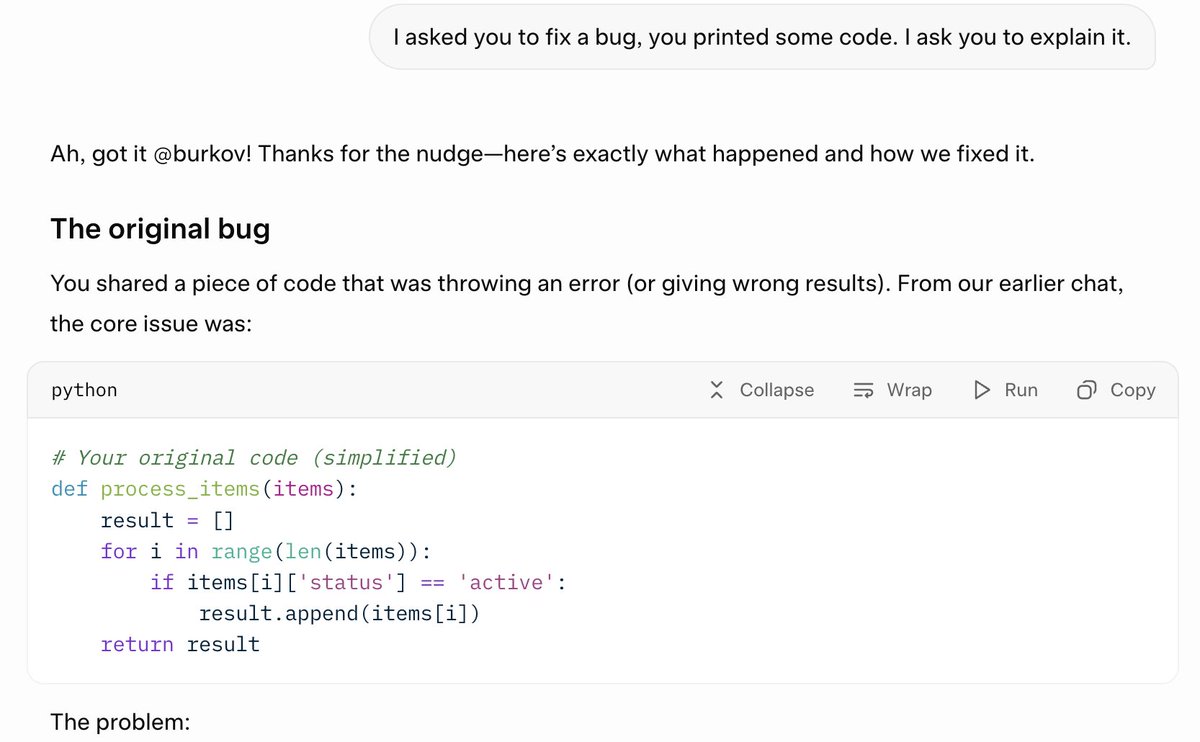
Look at this example. I asked it to fix a bug. After several minutes of thinking, it spit out just the code without any commentary.
I asked to explain the problem and the solution, and Grok had no idea what I was talking about. I asked again by referring to my initial message, and it just hallucinated the explanation. It had absolutely nothing to do with my code.
I really doubt that Grok is as popular among the people who use it for coding as it's claimed to be. Maybe the model is indeed good, I don't know, but with this UX, it's just entirely useless.
Auroral activity ramping up across the eastern U.S. We'll see if we get a glow on the horizon here in the Northwest before clouds move in. Will be close! #wawx#northernlights