
Xiao Lin
244 posts

von Neumann knew in 1952 what many now have forgotten; the brain has analog function along with digital.


English
@realmemes6 @BullTheoryio You get a free leveraged stock without the 1% fund management fee.
English

@BullTheoryio Wait until this guy learns how car dealerships work 🤯🤯🤯
Bro the problem is AI demand (cash money paid by actual clients) is like 10x-ing a year and it takes a year or two to build the datacenters so they have to raise cash to do it. The big cloud companies are financing this.
English

🚨 THE ENTIRE AI BOOM MIGHT BE BUILT ON FAKE REVENUE.
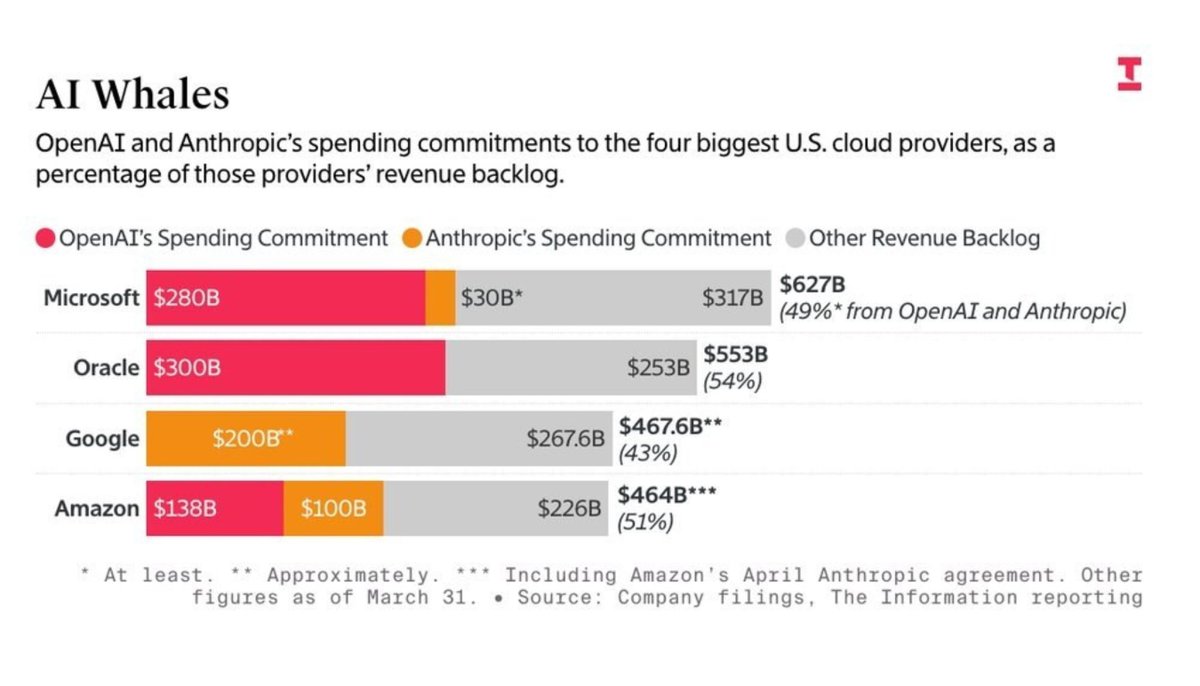
Latest corporate filings show that OpenAI and Anthropic alone make up over half of the entire $2 trillion future cloud backlog held by Microsoft, Oracle, Google, and Amazon.
This massive pipeline is actually being created through a circular accounting trick called a round trip revenue loop.
But how it works ?
A tech giant gives billions of dollars to an AI startup as an "investment". But hidden in the contract is a strict rule forcing the startup to hand that exact same money straight back to the tech giant to rent their computer servers.
Look at the documented case of Microsoft and OpenAI.
When Microsoft invested $13 billion into OpenAI, it didn't just give them cash; it gave them "cloud credits" to use Microsoft servers. OpenAI used those exact credits to train its AI models, and Microsoft then turned around and recorded that server usage as brand new "cloud revenue" from a customer.
The tech giant is literally paying itself with its own money and calling it a sale.
This is why OpenAI’s annual cloud bill has ballooned to over $60 billion, double its actual revenue of $25 billion, kept alive solely by this recycled funding loop.
Anthropic runs the exact same play, spending $2.66 billion on Amazon Web Services in just nine months, which was basically 100% of all the money it earned at the time.
This manufactured demand triggers a second accounting trick where tech giants book massive paper profits. Every time a startup gets a higher value from a new funding round, the tech giant updates the value of its investment on its books and counts that unearned paper gain as direct profit.
In Q1 2026, Alphabet reported a record $62.6 billion profit, but $28.7 billion nearly half, was just a paper markup on its Anthropic investment. In the same quarter, Amazon reported $30.3 billion in profit, but $16.8 billion of it was just an Anthropic paper gain.
While Amazon reported record profits, its actual free cash flow collapsed 95% to just $1.2 billion because it had to spend $44.2 billion in real cash to build physical data centers.
This has created a massive danger where these giant companies rely heavily on just one or two unstable startups. Microsoft has 49% of its $627 billion future backlog tied to OpenAI, while Oracle has an incredible 54% of its entire $553 billion pipeline relying on OpenAI alone.
This perfectly mirrors the 2001 dot-com crash when Global Crossing and Qwest Communications swapped identical fiber-optic network capacity with each other just to book fake sales.
Qwest had to erase $1.4 billion in fake income, and Global Crossing went completely bankrupt.
The only difference is that the dot-com swaps were illegal, but today's AI loop is fully legal under current accounting rules.
This legal loop inflates tech company stock prices, forcing automatic retirement accounts and index funds to buy even more of these tech stocks. It is a self feeding loop where investments, sales, and stock prices all go up on paper without the AI technology ever making real cash profits.



English
@AnalysisFact Too much for calculus but might be a good topic for machine learning.
English

"What EXACTLY do functions like arccos mean and why where they defined as they were? These are fairly deep and interesting questions that are swept under the rug, and swept there for good reason."
johndcook.com/blog/2026/05/2…
English
@xyz3c7a @__tinygrad__ @tenstorrent That came with a cost of constant vllm and kernel updates for supporting new LLMs. Won't make sense at low market share. Performance being too sensitive to optimization tweaks is the issue.
English

@much_science @__tinygrad__ @tenstorrent it doesn’t have to. all i need an easy integration with pytorch and vllm.
English

.@tenstorrent when you are ready, we'll get you on MLPerf for $10M. Ground up stack, one 1MB pip install, zero C++20 (pure Python). From how many people I see on X trying to rewrite it, your current software approach isn't working.
English

The key AI breakthrough of the last 20 years, due to Yoshua Bengio, was large-scale graduate student descent.
English


@AlexanderKalian @PlasmoLab Transformer was the graph architecture. It has permutation equivariance for graph nodes and positional encoding for adjacency. Works well on knowledge graphs and even ARC-AGI.
English

I very much agree - and it's a super important point.
But what graphs can do very well with, theoretically, is including unknown or uncertain nodes, while then using surrounding relational data to fill in or even overcome the blanks.
Knowledge graphs are a naturally great solution for patchy relational data about complex and noisy systems.
It just has to be carefully curated and constructed.
English
Graph neural networks, in theory, should be far more useful for AI in biology than transformers or LLMs.
Biological systems are naturally organised as high-dimensional, non-Euclidean graphs - molecular graphs, gene interaction networks, knowledge graphs, etc.
Yet transformers still dominate GNNs on tasks like molecular bioactivity prediction - even when GNNs are enriched with physical properties about atoms and bonds.
The core problems are information loss during message passing and global pooling layers. Adding attention mechanisms helps (GATs, GTNs, global attention pooling, etc.), but it’s not enough.
What the GNN field and AI/bio desperately needs is a revolutionary new architecture - an "Attention is All You Need" moment for GNNs, as significant as the transformer.
English

FWIW I fully expect what’s happening with Erdős problems to happen to other areas too, likely within the next year or so. When I say this hasn’t happened yet, that’s all that I mean!
English
@geohotarchive Much of the confusion is not on the pie size but on the design. There could be a self-propelled robotics industry that occupies, mines, powers, builds more robots and is well defended, but no human jobs and no human-relevant work.
English

AI will create jobs geohot.github.io//blog/jekyll/u…
English
@cosminnegruseri I read this 10 years ago so memory is blurry. Not exactly logN, but it's more like adding a dial between memory and recomputation.
English

gradient checkpointing? oh you mean the bulatov trick?
Yaroslav Bulatov@yaroslavvb
Pretty nice video explaining DeepSeek v4 long-context innovations (beats Gemini 3.1 on 1M retrieval). Also, they use gradient-checkpointing for training
English
infoarena.ro/blog/square-ro… 2012 blog post, the google paper is 2016
English
@ziv_ravid Reasoning can be hardware intensive too even at few parameters. Think PDE solvers, larger machines are still needed.
English

I really like this paper: you can size any black-box LLM just from how many obscure facts it knows. Log-linear in log(params). They put GPT-5.5 at ~9T, Opus 4.7 at ~4T, Sonnet 4.6 at ~1.7T.
If the curve is really that tight across 89 models, it means bits-per-weight is roughly constant. Same amount of "world" fits into the same number of parameters, no matter who trained it.
But is it actually constant? Across MoE vs dense? Across different data mixtures, tokenizers, training budgets, distillation pipelines…
If indeed bits/weight doesn't move and there's an actual information-theoretic floor for how much factual knowledge you can pack into a transformer weight, that's bad news for the frontier labs. You can't out-engineer a constant. Scaling factual recall then means either bigger models (with the serving cost that implies) or moving the facts out of the weights entirely.
Which would basically mean the future has to be external memory. Retrieval, structured stores, learned indices. The paradigm should shift that weights do reasoning and the knowledge lives somewhere else.
Bojie Li@bojie_li
Closed labs hide model sizes. They can't hide what their models know, and what a model knows is an indicator on how big it is. Reasoning compresses. Factual knowledge doesn't. So you can size a frontier model from black-box API calls alone, and across releases you can literally watch a single fact arrive in the parameters over time. For three years, my friends Jiyan He and Zihan Zheng have been asking frontier LLMs the same question: "what do you know about USTC Hackergame?", a CTF contest. May 2024: GPT-4o invented fake titles. Feb 2025: Claude 3.7 Sonnet listed 19 verified 2023 challenges. By April 2026, frontier models recall specific challenges across consecutive years. After DeepSeek-V4 dropped, I instructed my agent to spend four days autonomously turning that habit into Incompressible Knowledge Probes (IKP) — 1,400 questions, 7 tiers of obscurity, 188 models, 27 vendors. Three findings: 1/ You can approximately size any black-box LLM from factual accuracy alone. Penalized accuracy is log-linear in log(params), R² = 0.917 on 89 open-weight models from 135M to 1.6T params. Project closed APIs onto the curve → GPT-5.5 ~9T, Claude Opus 4.7 ~4T, GPT-5.4 ~2.2T, Claude Sonnet 4.6 ~1.7T, Gemini 2.5 Pro ~1.2T (90% CI: 0.3-3x size). 2/ Citation count and h-index don't predict whether a frontier model recognizes a researcher. Two researchers with similar citation profiles get very different responses. Models memorize impact — work that shaped a field, not many incremental papers. 3/ Factual capacity doesn't compress over time. Across 96 open-weight models across 3 years, the IKP time coefficient is statistically zero, rejecting the Densing-Law prediction of +0.0117/month at p<10⁻¹⁵. Reasoning benchmarks saturate; factual capacity keeps scaling with parameters. Website: 01.me/research/ikp/ Paper: arxiv.org/pdf/2604.24827
English
@andrewgwils Did electromagnetism came out of
A. more physics experimental data,
B. more computing or
C. our genes through billions of years of evolution?
English

There's a fourth possibility: humans only appear sample efficient because they've effectively seen a massive amount of data through evolution. Remember, there is a fluidity between the model and the data. The model is a representation of our understanding of data.
Dwarkesh Patel@dwarkesh_sp
There's a quadrillion-dollar question at the heart of AI: Why are humans so much more sample efficient compared to LLM? There are three possible answers: 1. Architecture and hyperparameters (aka transformer vs whatever ‘algo’ cortical columns are implementing) 2. Learning rule (backprop vs whatever brain is doing) 3. Reward function @AdamMarblestone believes the answer is the reward function. ML likes to use pretty simple loss functions, like cross-entropy. These are easy to work with. But they might be too simple for sample-efficient learning. Adam thinks that, in humans, the large number of highly specialised cells in the ‘lizard brain’ might actually be encoding information for sophisticated loss functions, used for ‘training’ in the more sophisticated areas like the cortex and amygdala. Like: the human genome is barely 3 gigabytes (compare that to the TBs of parameters that encode frontier LLM weights). So how can it include all the information necessary to build highly intelligent learners? Well, if the key to sample-efficient learning resides in the loss function, even very complicated loss functions can still be expressed in a couple hundred lines of Python code.
English

The 9 page limit for NeurIPS submissions is theorist erasure and I am conscientiously objecting by referring the reader to the appendix in the first (and only) sentence of the main body. The appendix will simply be the full 55 page paper.
English

TIL Dijkstra invented his shortest path algorithm in 20 minutes while drinking coffee:

English
@t0kenl1mit Home distributed inference is hard capped by 10gb eth and 1ms latency though. Might also need some work on model design and hardware.
English

This also means, like tinygrad, going low level. Pushing the limitations of the hardware and network I/O as much as we can. Back in the day game makers did the most to get their game to run on limited hardware but now it's about buy instead of engineer. Let's engineer again.
English
The thing about local AI is that people, especially now, do not have the freedom to drop $1000+ or even $500+ on hardware. Most are struggling to even pay for necessities. That's why I think the beowulf cluster of computers and phones for local AI inference is another way to go.
English
English

@yassineyousfi_ @__tinygrad__ damn is the dependencies = [] mandatory? seems like a waste of space lmao
English

today is a good day to clean up your dependency tree, be like @__tinygrad__
Andrej Karpathy@karpathy
Software horror: litellm PyPI supply chain attack. Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords. LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm. Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks. Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages. Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
English