Sabitlenmiş Tweet
mahdi
2.3K posts


mahdi
@mxhdiqaim
Software engineer, I solve math equations for fun, play Sudoku and read comic.
Abuja, Nigeria Katılım Aralık 2019
320 Takip Edilen387 Takipçiler
mahdi retweetledi

Nigerian defense-tech startup Terra Industries unveiled its latest autonomous defense systems including interceptor drones, mine-detection vehicles and battlefield intelligence software reut.rs/4sYfyow
English
mahdi retweetledi


mahdi retweetledi

A Nigerian startup launched their app. Built a clean OTP flow. No rate limiting on the SMS endpoint. Shipped it.
Within 48 hours, their Termii balance went from ₦150,000 to zero.
They woke up to failed OTP delivery complaints from real users.
Checked their logs.
Someone had been hitting their /send-otp endpoint in a loop with thousands of requests sending SMS to sequential phone numbers that were not even their users.
This is called SMS pumping fraud.
Here is how it works:
• Fraudsters find your open OTP endpoint
• They send requests to thousands of phone numbers, sometimes numbers they control on premium routes
• Every successful SMS costs you money
• They get a cut from the carrier. You get the bill.
It is automated. It runs while you sleep.
The fixes that would have stopped it entirely:
• Rate limit by IP: max 3 OTP requests per IP per hour
• Rate limit by phone number: max 3 requests per number per 10 minutes
• Add a minimum delay between requests
• Implement CAPTCHA or device fingerprinting on the frontend
• Alert yourself when SMS spend spikes above a threshold
None of this is complicated.
All of it takes less than a day to implement.
That startup lost ₦150,000 in two days and had to shut down OTP entirely while they fixed it.
Their users thought the app was broken.
Some never came back.
The breach was not dramatic.
No hacker. No sophisticated attack.
Just an open endpoint and a bot.
Secure your OTP flow before you launch.
Not after you've learned the hard way.
English
mahdi retweetledi

There is a developer in Nigeria right now.
Coding by generator light. Buying data 1GB at a time. Getting rejected by companies offering ₦80k. Being told they're not experienced enough.
Watching their mates abroad earn 20x their salary for the same skill.
Still opening their laptop tomorrow morning.
That is not desperation.
That is the most elite form of discipline on earth.
And the world hasn't paid them what they're worth yet.
But it will LETS GOO🚀
English
mahdi retweetledi

This is a huge unbounded query on a 70M row table.
I wouldn’t run it as-is. I’d break it down step by step.
1. Understand the use case
- Does the UI really need 6 years of data in one call?
- Can we limit the range or paginate?
2. Check indexing
Make sure there’s an index on the filter
INDEX(created_at)
or better if combined filters exist
INDEX(created_at, other_filters)
3. Avoid returning massive payloads
- Add pagination / cursor-based API
- Or return aggregated data instead of raw rows
4. Consider partitioning
If this query is common
- Partition by date (created_at)
→ Only relevant partitions are scanned
5. Precompute / cache
For reports:
- Use materialized views / summary tables
- Or cache results (Redis, etc.)
6. Async processing
If it’s a heavy report
- Trigger a background job
- Return a report ID / download link
English
mahdi retweetledi

mahdi retweetledi

Harsh truth: you cannot vibecode an app unless you are a developer yourself.
English
mahdi retweetledi

today’s one-sentence horror:
sudo has been largely maintained by a single person for ~30+ years
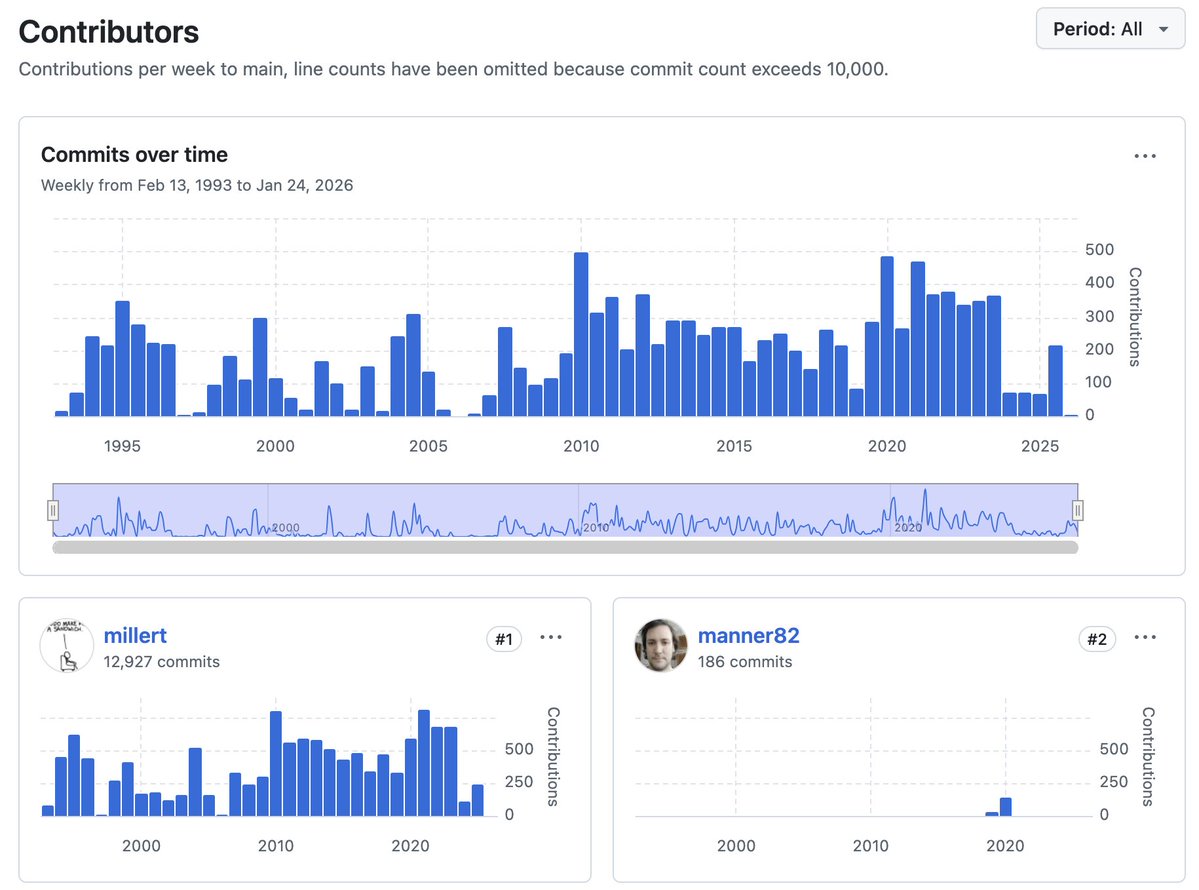

English
@DevAbraham035 @NijaDeveloper There is a saying that goes "the more you know something, the more you have questions about it and the more you don't know it"
The opposite is also true.
English


🧵 Backend Dev Villain Origin Story (Auth Edition)
Day 1
PM: “Can we use Clerk or Auth0?”
Me: “Nah… I’ll build auth myself. How hard can it be?”
Day 2
✔ JWT
✔ Refresh tokens
✔ HttpOnly cookies
✔ RBAC
✔ Middleware
Confidence level: God mode 💪
Day 5
❌ Token rotation bug
❌ Logout doesn’t revoke tokens
❌ Redis blacklist debate
❌ Safari cookie issues
❌ Security blog PTSD
Me at 2:37am: “Why is this token still valid???”
Day 7
Re-reading Auth0 docs “just for inspiration” 👀
Googling:
“Should I store refresh tokens in database?”
Final Boss Thought:
“Maybe SaaS auth isn’t that expensive…” 😭
Caption:
Backend devs don’t build auth for features.
We build it for character development.
🤣😂🤣😂
Golang devs: “I want control.”
Node devs: “I want flexibility.”
Java devs: “I want standards.”
Auth: “I want your sanity.”
What do you think solo Developer should do?
#authenticate #clerk @clerk @Amospikins
English

If you code with C#, PHP, ASP .NET (3.5, 4.5), Python and looking for a job
Target:
- Poland
- Germany
- Austria
- Czech
- Sweden
- Netherlands
- Denmark
These countries have companies that use legacy systems written in the stacks above and need maintenance
I have a friend that was netting $6k/month maintaining code at a Swedish company
Tech_baby@Tech_babby
Stop complaining that there are no jobs Target local farms in Georgia USA - Target Dental practices in Sydney Australia - Target local E-commerce Shopify businesses in Oshodi Lagos(joke oh) 😭 - Target small logistics companies in Manchester UK - Target real estate companies in Texas USA You can simply use Google maps or ChatGPT to find them! Go sell your skill🙏🏽 If you want to build for impact? target bigger industries in California, UK etc.. Build impressive projects to get noticed!! Build, Be loud and Bold!! Should I hold your hand and drag you? 😫
English
mahdi retweetledi

GitHub stores millions of repositories the same way they exist on our local machine - literally as git repositories. Nothing very special.
Instead of one copy, GitHub stores at least three copies of every single repository to make sure the code is never lost. This replication system is called Spokes at GitHub.
When we push code, the write is not accepted unless a strict majority of replicas - at least 2 out of 3 - can successfully apply the change and produce the same result.
Interestingly, the system watches real application traffic to detect failures. If three requests in a row fail to one of the servers for a repository, that server is marked offline, and traffic is routed to other replicas within seconds. No heartbeats needed - just monitoring the real user operations.
Each replica lives in a different rack. When an entire rack goes down, repositories remain available because the other copies live elsewhere. And when repairs are needed after a server failure, the whole cluster helps out - the bigger the cluster, the faster it recovers.
Spokes refuses write operations that it cannot commit to at least two places. This ensures that when your push succeeds, your code is already safe.
This is also why GitHub rejects pushes during partial outages. Reads might still work, but writes fail because the system refuses to risk losing data.
This is pretty much how GitHub stores repositories and, more importantly, prefers a simple design with consistency over durability and availability.
Hope you also found it interesting.
English
Why are people saying stack overflow is dead? I visited it yesterday
ℏεsam@Hesamation
this is a catastrophe. StackOverflow provided data to LLMs, LLMs replaced StackOverflow, and now no new Q&A hub exists to provide fresh data. it’s a self-undermining causal loop, like mold growing on food, consuming it, and dying once the food is gone.
English
mahdi retweetledi


mahdi retweetledi

In Enugu Disco a Nigerian engineer is being paid N200k/monthly while an Indian or Lebanese worker with lower experience is being paid $15k/month.
This happens in lots of other companies.
Nigerians can’t be treated this poorly even in their own country.
Where is NLC and co?
English
Verifying myself: I am mxhdiqaim on Keybase.io. FOddSV7c6hkcSLFgREdD3eJCvad4JxweVZnG / keybase.io/mxhdiqaim/sigs…
This is a piece of art., crafted before the mankind of 21st century.
Charlie Lamb@charlietlamb
People really be building anything these days man
English

Environment branching is a model where each environment has its own branch.
Code moves through the pipeline by merging from one branch to the next, usually in a sequence like dev → qa → staging → prod.
It gives teams very explicit control over what gets deployed. Developers work in dev, testers pick up changes in qa, staging stabilises releases, and production only receives what’s been promoted through each step.
This approach shows up often in legacy systems or setups without strong CI/CD tooling.
When promotions are manual, having separate branches can feel safer and easier to reason about.
The trade-offs are significant. Branches drift quickly, environments behave differently, and keeping everything in sync becomes its own job.
The model doesn’t scale well and tends to work against modern practices that rely on a single source of truth.
Environment branching offers control, but it comes at the cost of consistency. For most modern teams, it’s an anti-pattern unless the constraints of the system make it unavoidable.

English
@ethanjaack I don't really know what is wrong with these people. Before you even use their service, your account is deactivated.
This is a very bad experience @Hetzner_Online
English

@mxhdiqaim let's find you a host that actually respects your time and site
English


Why Redis is Single-Threaded (and why that makes it fast)
You check your 32-core server and Redis seems to fully utilize only one core.
This looks inefficient, so why is Redis still one of the fastest in-memory databases in the world?
1./ The real bottleneck isn’t usually the CPU
For classic Redis workloads (GET, SET, INCR), the time spent on CPU instructions is tiny.
Most real-world bottlenecks come from:
- Network bandwidth (sending data to clients)
- Memory bandwidth (moving data between RAM and CPU caches)
- Kernel overhead (syscalls, TCP/epoll processing)
In these cases, adding more CPU cores doesn’t increase throughput, the constraint lies elsewhere.
2./ Why multi-threading would make Redis slower
If multiple threads tried to read/write the same keyspace, Redis would need:
- Lock Contention
To safely read/write Key X, threads would need synchronization. Waiting for locks introduces latency.
- Context Switching
Switching between 32 threads burns CPU cycles and disrupts cache locality.
- Cache Coherence Penalties
If one thread updates data another thread recently cached, hardware has to invalidate caches across cores.
This 'cache thrashing' adds significant overhead.
In many workloads, these costs exceed the actual cost of executing the Redis command.
3./ The secret => a single-threaded event loop
Redis uses a non-blocking event loop powered by epoll/kqueue.
It can watch thousands of connections at once and only processes sockets that are ready.
Benefits:
- No locks
- Predictable latency
- Strict ordering (A → B → C)
- Simple, efficient execution path
Since all operations happen in memory, one thread can process hundreds of thousands to over a million commands per second.
4./ The accurate nuance => Redis does use multiple threads
Redis isolates command execution on a single thread, but uses additional threads where they help most:
✔️ 1. Main Thread
- Executes all commands and accesses the keyspace.
- This is intentionally single-threaded for consistency and performance.
✔️ 2. BIO Threads
Used for slow tasks that would otherwise block the main thread:
- Lazy deletion (UNLINK)
- AOF fsync operations
- Module background tasks
✔️ 3. I/O Threads (Redis 6.0+)
Optional multi-threading for:
- Reading network requests
- Writing responses
This improves throughput without touching the shared dataset or requiring locks.
Redis gets the benefits of parallel I/O without sacrificing deterministic, lock-free execution.
Let's summarise it -
Redis stays single-threaded for the part that touches data, eliminating locks, contention, and unpredictability, while using background and I/O threads for everything else.
This gives Redis both simplicity and speed, often outperforming more complex multi-threaded designs.
Happy Learning!!!
Please follow @techNmak for regular insights.
English