@richraposa @ClickHouseDB There is something magical in that linux pipe - curl | clickhouse_client . Nice work.
English
Nate Busa
4.4K posts

@natbusa
Director of AI and Automation at Neom | AI @Stanford | CTO Program @Wharton | Technology Strategy, Innovation, Product Development












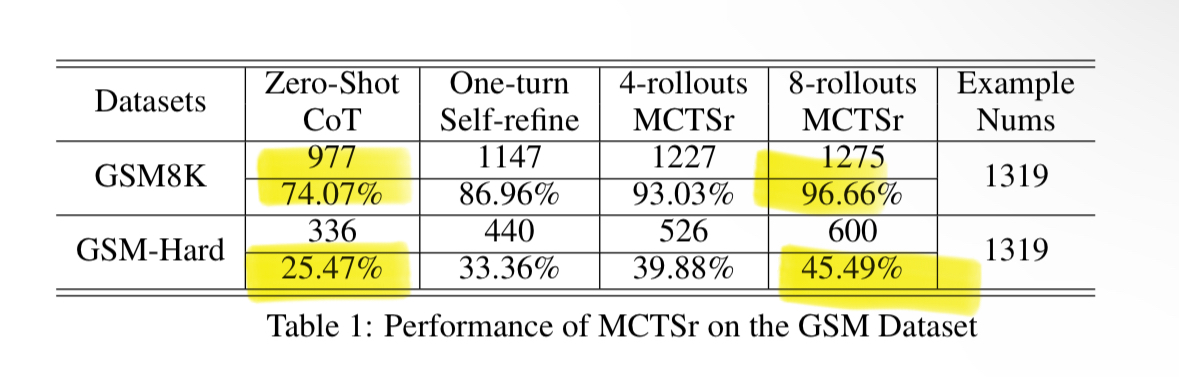



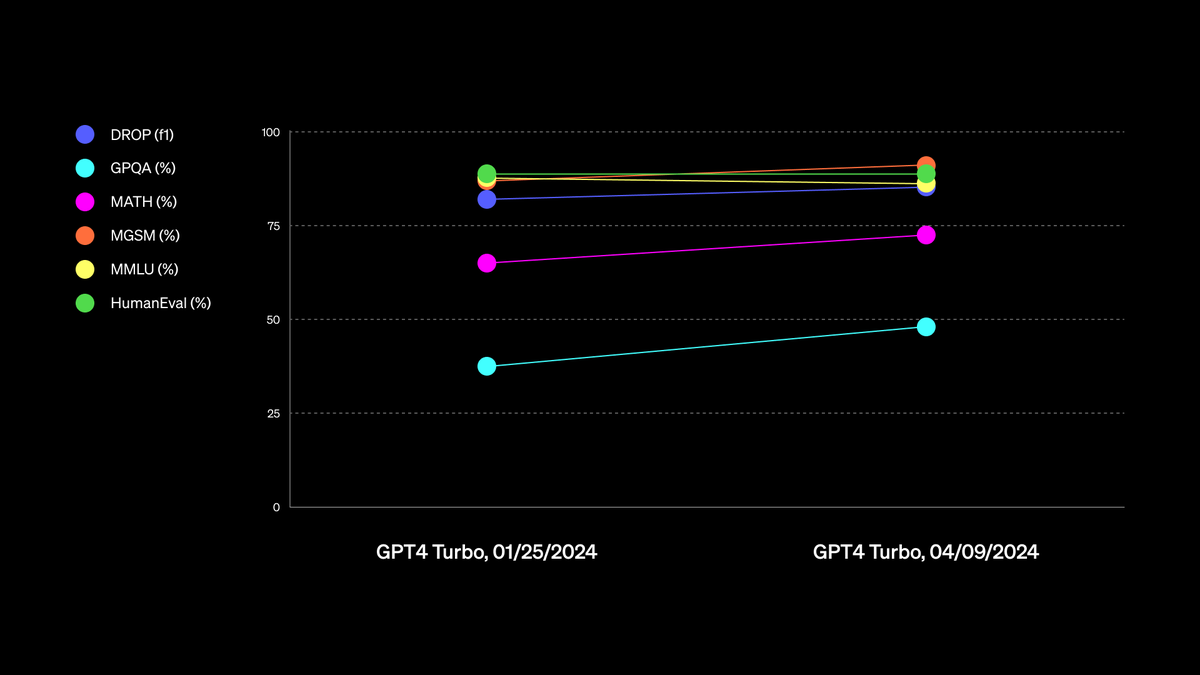

ChatGPT doesn't give you information. It gives you information-shaped sentences.