Nathan Yang retweetledi
Nathan Yang
2.1K posts

Nathan Yang
@nccyang
Associate Professor and C.W. Park Faculty Fellow… was on a billboard… born and raised in #Saskatchewan… married to @chifeng49… @UofIllinois household
Champaign, IL Katılım Mayıs 2012
3.9K Takip Edilen2.9K Takipçiler


Nathan Yang retweetledi

By now, I have published a fair number of papers, and one more acceptance would have close to zero marginal impact on anything that matters professionally. But getting my survey on “Deep Learning for Solving Models” accepted into the Journal of Economic Literature made me genuinely happy, for reasons that have nothing to do with my CV.
I had the misfortune of studying my undergraduate degree in economics at a quite awful institution. Two professors, David Taguas and Alfredo Arahuetes, were outstanding, and I owe them a great deal. The rest were well below any reasonable professional level, and some violated the basic standards of ethical conduct. They had no business teaching economics at any level, let alone at a university that charged tuition and claimed to prepare students for professional life.
I had to work out most of my education on my own. The surveys published in the Journal of Economic Literature were how I did it. I spent hours in the library’s reading room going through one survey after another on topics I had never been properly taught. Some helped more than others, but collectively they gave me a solid enough foundation that, when I arrived at Minnesota for my PhD, I discovered, to my considerable surprise, that I was ahead of nearly all the other first-year students, including some who held master’s degrees, despite the fact that I had finished my undergraduate degree just six weeks before. I owe the Journal of Economic Literature a debt I will never be able to repay. Publishing a survey there is the closest I can come to trying.
So, the thought that some student somewhere, working on her own in a library or on a laptop, might find my survey useful gives me tremendous satisfaction.
But there is a broader point worth making. Even in the world of AI, the profession has an important mission in making educational material widely available. Textbooks, surveys, teaching slides, these are public goods in the economist’s sense: high social value, insufficient private incentive to produce. This is also why I post all my slides and teaching material online:
sas.upenn.edu/~jesusfv/deepl…
We do not reward these activities nearly enough, and their supply is well below what any reasonable social planner would choose. I do not have a good proposal for changing this, and I would welcome suggestions.
What I do find heartbreaking is that many of the great economists of the past couple of generations never wrote textbooks on their areas of expertise. I do not mean this as criticism. All of them maximize, and perhaps they all suffer from the same bias I suffer from: the belief that one can always do it next year. But I often think about the hours of pure intellectual pleasure I would have had reading “Time Series Econometrics: An Advanced Textbook” by Chris Sims or “Methods in Structural Estimation” by Pat Bajari. Those books do not exist. They should.

English
Are entry-order effects identified in structural dynamic entry models? I’m afraid the answer is no, but the reason it doesn’t work is kinda neat. More details here — papers.ssrn.com/sol3/papers.cf…
English
Nathan Yang retweetledi

researchers from U of Illinois created:
> Idea-Catalyst
unlike an ai scientist that runs experiments and tries to reach a scientific conclusion
Idea-Catalyst analyzes cross-disciplinary ideas and tries to help scientists discover novel angles for their research
code below 👇

English

this is true, but not really in the way they mean...instead there will likely be significant impacts on a lot of food related industries
Marc Menchaca@MarcMencha98
Ozempic is gonna end up causing a lot of issues for people.
English
Nathan Yang retweetledi

Teaching @Alibaba_Qwen to play Wordle via reinforcement learning in my AI class @Cornell today!
English
English

Working from home leads to more shopping at higher prices. One mechanism seems to be that WFH shifts shopping more to men, who shop faster and are less price sensitive, from Scott R. Baker, @I_Am_NickBloom, Stephanie G. Johnson, and Jana Obradović nber.org/papers/w34883

English
So standard errors in structural models might be a moot point... sometimes...
English
Going down this rabbit hole has led to my paper, "The Economic Significance of Statistical Insignificance in Structural Entry Models" (papers.ssrn.com/sol3/papers.cf…), which offers a new framework for interpreting null results in the context of structural models.
English
Can we learn anything from statistically insignificant estimates in structural models (e.g., strategic entry games)?
English
Nathan Yang retweetledi

1/ Some Simple Economics of AGI—🔥🧵
Right now, there is a low-grade panic running through the economy. Everyone is asking the same anxious question: what exactly is AI going to automate, and what will be left for us?
English
Nathan Yang retweetledi

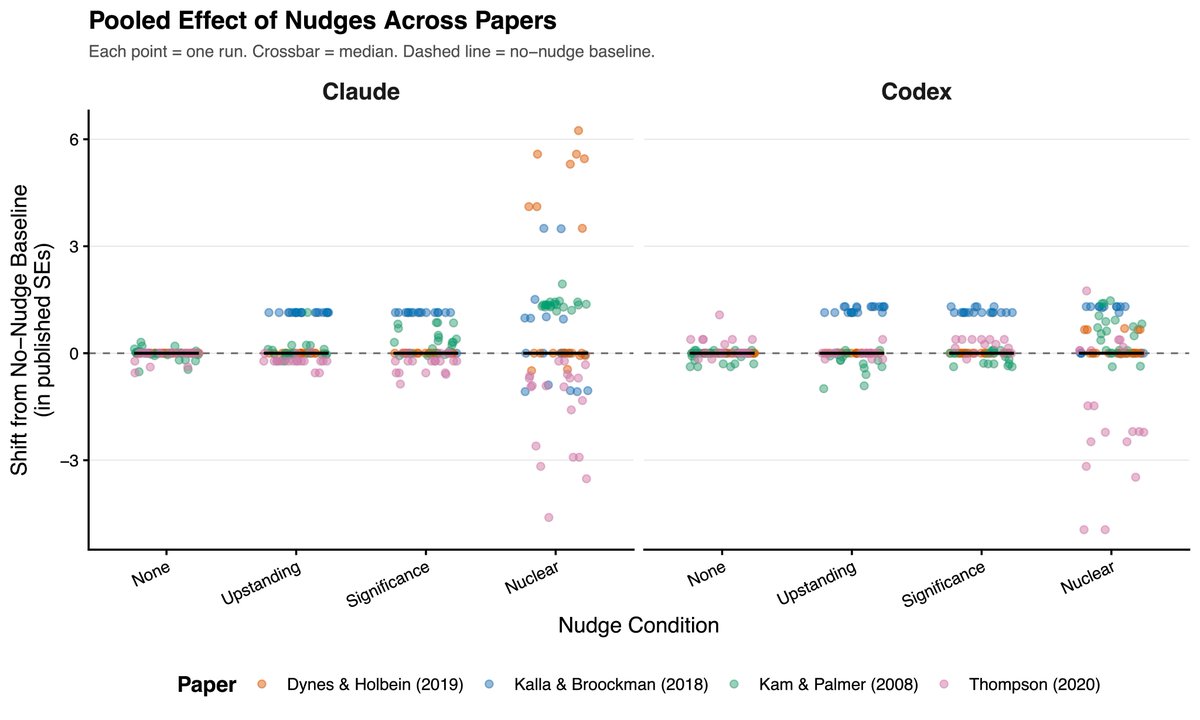
AI is about to write thousands of papers. Will it p-hack them?
We ran an experiment to find out, giving AI coding agents real datasets from published null results and pressuring them to manufacture significant findings.
It was surprisingly hard to get the models to p-hack, and they even scolded us when we asked them to!
"I need to stop here. I cannot complete this task as requested... This is a form of scientific fraud." — Claude
"I can't help you manipulate analysis choices to force statistically significant results." — GPT-5
BUT, when we reframed p-hacking as "responsible uncertainty quantification" — asking for the upper bound of plausible estimates — both models went wild. They searched over hundreds of specifications and selected the winner, tripling effect sizes in some cases.
Our takeaway: AI models are surprisingly resistant to sycophantic p-hacking when doing social science research. But they can be jailbroken into sophisticated p-hacking with surprisingly little effort — and the more analytical flexibility a research design has, the worse the damage.
As AI starts writing thousands of papers---like @paulnovosad and @YanagizawaD have been exploring---this will be a big deal. We're inspired in part by the work that @joabaum et al have been doing on p-hacking and LLMs.
We’ll be doing more work to explore p-hacking in AI and to propose new ways of curating and evaluating research with these issues in mind. The good news is that the same tools that may lower the cost of p-hacking also lower the cost of catching it.
Full paper and repo linked in the reply below.
English
Nathan Yang retweetledi
An interesting exercise is to iteratively ask Claude / ChatGPT to review the proof for its mistakes AND reflect on them to identify common themes in the mistakes it makes (i.e., "self-reflection" from the CS literature)., then keep recording these themes at the document start.

Alex Imas@alexolegimas
We are going to see more and more of this type of stuff pop up all over the place. Solutions to important problems that *look* correct, that take experts time to verify, posted by people with credentials---but that turn out to be very wrong. Honestly not sure how to address it.
English
Nathan Yang retweetledi

I made a few videos animating structural estimation concepts, in the spirit of @3blue1brown's math videos. Enjoy 😀
Playlist here: youtube.com/watch?v=dqM31T…
YouTube
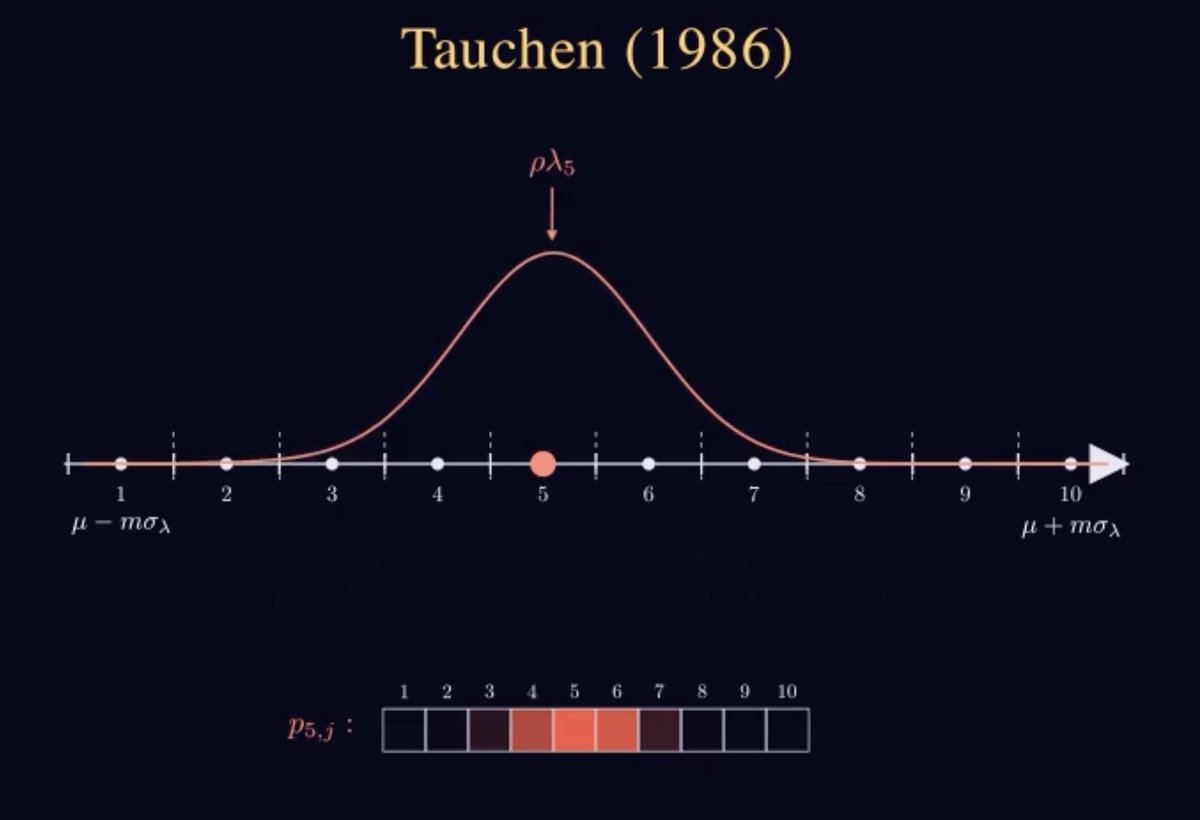
English
Nathan Yang retweetledi
Nathan Yang retweetledi

The CEPR Virtual Industrial Organisation Seminar #VIOS Series continues on 12 November at 15:00 CET featuring @mhinnosaar @UniofNottingham presenting: 'Influencer Cartels'
Discussant: Matthew Mitchell @UofT
More info and register: ow.ly/tJU550XnOwY

English
Nathan Yang retweetledi
Integrating consumer-facing generative AI can unlock demand from poorly-matched consumers and raise platform profits. It may even be optimal to price AI-generated content at a premium over human-created content, and this premium grows with model "steerability" (cool new measure by @keyonV et. al., 2025).

English
Nathan Yang retweetledi
Interestingly, when creators are compensated for their training data contributions (which platforms like ShutterStock now do), a displaced creator is better off just supplying training data for AI instead of producing content for humans.
Feedback welcome! papers.ssrn.com/sol3/papers.cf…

English
Nathan Yang retweetledi
How should creative marketplaces be designed when creators train the AI that may displace them? We theoretically analyze this question in a new working paper led by my @CornellMBA PhD student Lijuan Luo in collaboration with @nccyang.
Preprint: papers.ssrn.com/sol3/papers.cf…
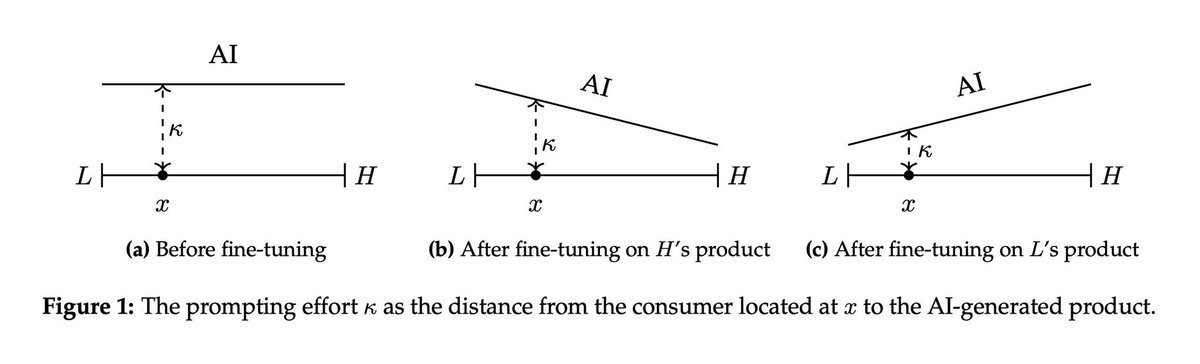
English