Dezső Németh retweetledi
Dezső Németh
640 posts


Dezső Németh
@nemethd
@Inserm, CRNL, Lyon | implicit cognition | statistical learning | predictive processing | memory consolidation | https://t.co/iVvezrq3Iz
Lyon, France Katılım Haziran 2009
423 Takip Edilen323 Takipçiler


In our new preprint, we tested whether mind wandering is a general marker of psychopathology or something more specific.
Result: it correlates with many symptom dimensions; but only ADHD uniquely predicts it when shared variance is controlled.
biorxiv.org/content/10.648…
English
Dezső Németh retweetledi

Cortical circuits are often thought to be specialized, but the same large-scale activity patterns can arise from different circuit architectures. In other words, different instruments can play the same tune, and the same instrument can sometimes play different tunes.
Micah G. Allen@micahgallen
Neural manifolds do not map one-to-one onto circuit architecture. This study shows that distinct recurrent circuits can generate similar low-dimensional dynamics, yet still leave identifiable constraints on neural selectivity and population activity. cell.com/neuron/fulltex…
English

Congratulations to all awardees, and thank you for your outstanding service to our community!
Full announcement: sciencedirect.com/science/articl…
English
🎉 Congratulations to the 2025 Cognition Outstanding Reviewer Award recipients:
Recognized for exceptional clarity, depth, and insight, their reviews set the highest standard and advance our field through thoughtful, rigorous evaluation.
This year’s recipients:🥁
English
Dezső Németh retweetledi

Optimizing a design for correlation may be bad for a design for comparing groups or conditions. And the other way around. osf.io/mu896

English
New preprint: we introduce an eye-tracking method to track, trial by trial, how expectations form and update during probabilistic learning. Results suggest conservative, repetition-based updating rather than strongly error-driven learning.
doi.org/10.64898/2026.…
#predictions
English
What if the contradictions in statistical learning aren’t real disagreements—but artifacts of non–process-pure tasks (à la Jacoby)?
Executive functions, sleep, development, mind wandering—all may reflect the same issue.
A different lens changes the story.
osf.io/preprints/psya…
English
Dezső Németh retweetledi

BREAKING🚨: Stanford University just launched a FREE AI tool for researchers!
It writes Wikipedia-quality reports with 99% accuracy & citations.
Here’s how to access it for free:
English
New paper out in Cerebral Cortex!
We show that frontal midline theta synchronization enhances cognitive flexibility: the brain updates old predictions faster when statistical regularities change.
tACS + eye-tracking + learning
doi.org/10.1093/cercor…
English
Dezső Németh retweetledi

We have a new paper out: Most ventral pallidal cholinergic neurons are bursting basal forebrain cholinergic neurons with mesocorticolimbic connectivity jneurosci.org/content/early/…
English
Dezső Németh retweetledi

High-impact papers are crucial in academia.
Like it or not.
As a PhD student, you quickly learn that such papers are cool. They make advisors happy. Everyone admires you.
During a postdoc, high-IF papers are not just cool. They are mandatory for a PI job. They give you awards and interviews.
During the tenure track, they often become your ticket to a permanent position. Many young PIs are fighting to get their papers published in Nature/Science/Cell. It’s like getting a micro-Nobel prize. Many feel relaxed only when they publish in Nature (their tenure is finally safe!).
But:
Because such papers require a lot of time (often years), you live in constant uncertainty.
You HOPE you will get it. You spend evenings at work, you look for stronger results, and you’re battling through a battalion of failed experiments.
Then you submit it…
Then:
Stage 1. Editors reject 9/10 papers. Yours might be among them.
Stage 2. The paper goes to reviewers but they are brutal. For some reason (and you know why!) they just don’t want to see your paper in Nature. Many papers get rejected in the first round.
Stage 3. If reviewers can’t come up with reasons to kick you out immediately, they will request a lot of new experiments and changes to your work. Obviously, that will take months (if not years). Of course, some reviewers are great and genuinely help improve your work. But they are not as common as you might hope.
Stage 4. After addressing all problems and submitting it again, you will likely see some reviewers still resisting. They can simply reject your paper because they didn’t like how you addressed their requests. Or they will find new flaws and will get you to do another round of revision. (If you’re lucky, they will accept the paper.)
Stage 5. If reviewers are divided between “accept” and “reject”, the editors may send your paper to additional reviewers. That will start another cycle of hell with a likely negative outcome.
Stage 6. If you are rejected, congratulations - you’ve just wasted months on nothing. But because you need that paper, you resubmit it to another high-IF journal, and it all starts with Stage 1.
So, it’s like gambling.
You gamble your career on this publication.
During those 6–24 months of fighting with reviewers and editors, someone else may publish the same work. Then you’re screwed.
Or your paper is likely not accepted in any high-IF journal. After loosing a year or more on trying to push it through, you will have to publish it in a low-IF journal.
Is it a healthy game?
No. You get exhausted. Anxiety skyrockets.
But unfortunately that’s how academia works. I’ve been through this myself. Most of my colleagues have the same experience. We definitely despise it.
And the worst part of it?
We’ve started to see it as completely normal.

English
New article out:
Statistical learning does not stay stable across childhood—as often claimed. Longitudinal data reveal a gradual developmental decline and growing individual differences. Methodology matters: cross-sectional ≠ longitudinal.
onlinelibrary.wiley.com/doi/10.1111/co…

English
Dezső Németh retweetledi

Better artificial intelligence does not mean better models of biology
Opinion by Drew Linsley (@DrewLinsley), Pinyuan Feng (@Pinyuan3), & Thomas Serre (@tserre)
Free access before Feb 11: tinyurl.com/2uvx445m

English
Dezső Németh retweetledi

Fascinating (& terrifying) article published in Science, on AI-assisted writing of scientific manuscripts.
Authors find evidence of:
1) accelerated research output due to LLMs
2) especially true of non-native English speakers
3) a complete reversal in correlation between writing complexity and publishability (!)
science.org/doi/abs/10.112…

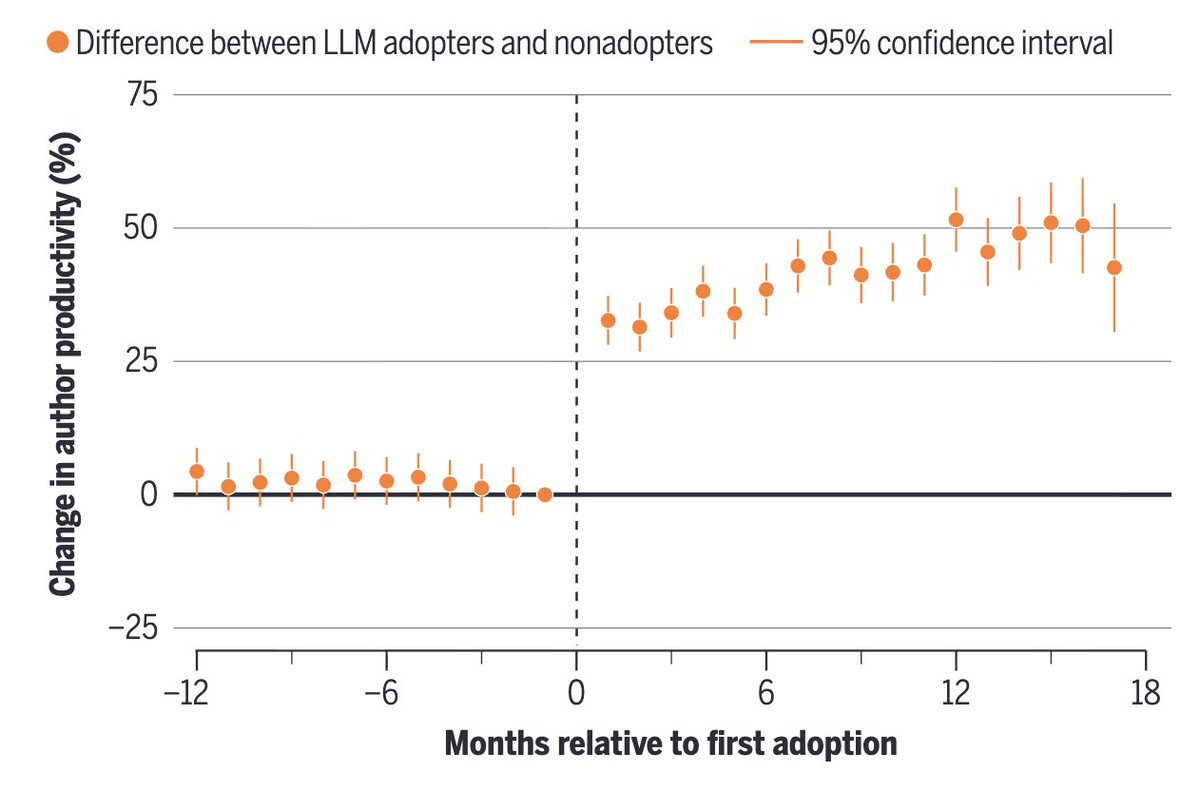
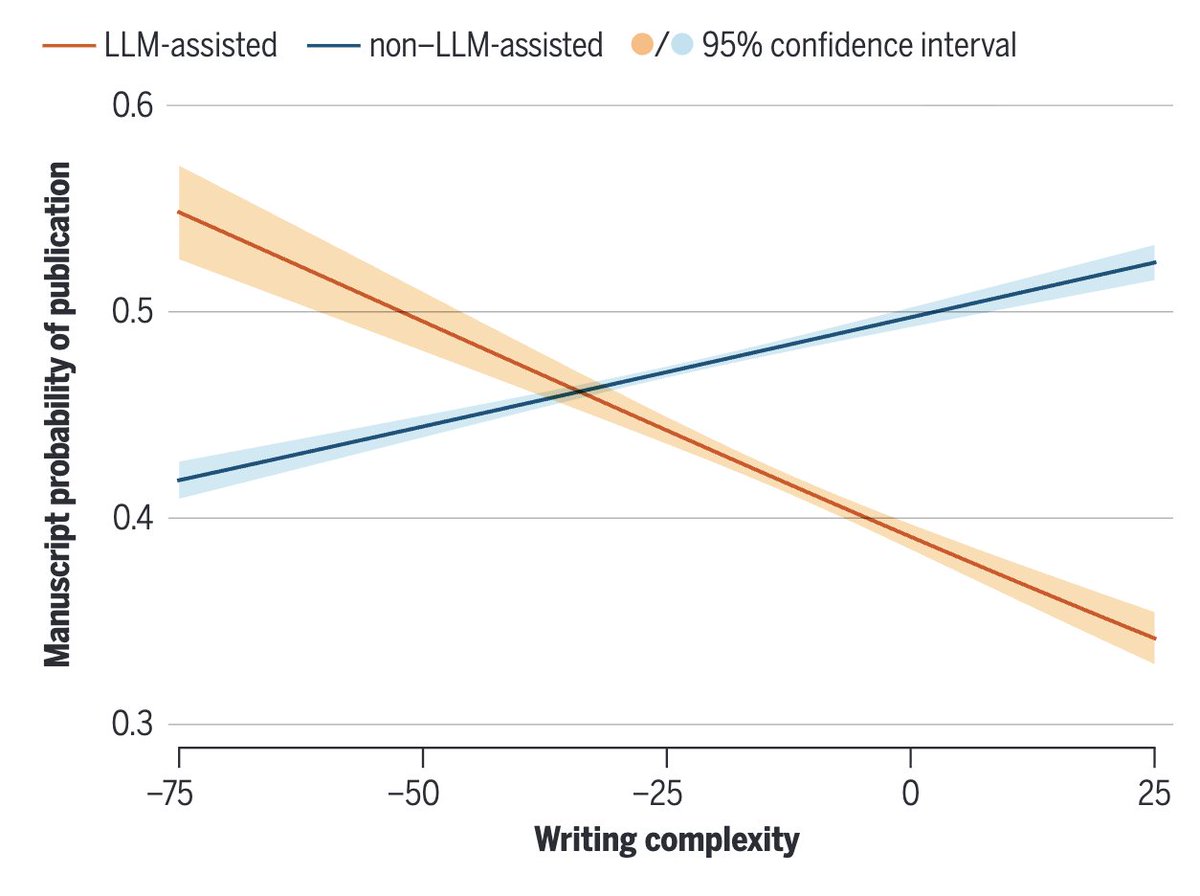
English
Dezső Németh retweetledi

Super interesting paper just out in Nature Human Behaviour!
Do humans learn like transformers?
In a smart experiment, the authors trained humans and transformer networks on the same rule-learning task, manipulating only one thing: the distribution of training examples, from fully diverse (every example unique) to highly redundant (the same items repeated).
The first results are already interesting:
Diverse examples lead both human and artificial systems to generalise rules to novel situations.
Redundant examples lead both humans and artificial systems to memorize examples.
Additionally, the switching between these two strategies appear at similar tradeoffs.
So, do humans and transformers learn in the same way? Not quite! And it’s here that things get super interesting:
If you show diverse examples first, humans learn to generalize without losing the ability to memorize later. Transformers, by contrast, do not show the same benefit: when training shifts toward memorization, earlier generalization does not reliably carry over.
Humans can accumulate learning strategies more flexibly than transformers.
Paper in the first reply

English
Dezső Németh retweetledi

Interesting research from Google.
Research has shown that neural networks don't just memorize facts. They build internal maps of how those facts relate to each other.
The view of how transformers store knowledge is associative: co-occurring entities get stored in a weight matrix, like a lookup table. The embeddings themselves are arbitrary.
But this view can't explain something these researchers found.
This new research demonstrates that transformers learn implicit multi-hop reasoning when graph edges are stored in weights, even on adversarially-designed tasks where associative memory should fail. On path-star graphs with 50,000 nodes and 10-hop paths, models achieve 100% accuracy on unseen paths.
This geometric view of memory challenges foundational assumptions in knowledge acquisition, capacity, editing, and unlearning. If models encode global relationships implicitly, it could enable combinational creativity but also impose limits on precise knowledge manipulation.
Paper: arxiv.org/abs/2510.26745
Learn to build effective AI agents in our academy: dair-ai.thinkific.com

English
Dezső Németh retweetledi

A massive discovery in neuroscience: fMRI signals don't always match true neural activity. In ~40% of cases, signals increased where activity actually decreased. This challenges the core assumptions of tens of thousands of studies.
#Neuroscience #fMRI #BrainResearch #CognitiveScience #MedicalResearch neurosciencenews.com/fmri-neural-ac… via @neurosciencenew
English
Dezső Németh retweetledi

𝗥𝗲𝘁𝗵𝗶𝗻𝗸𝗶𝗻𝗴 𝘁𝗵𝗲 𝗰𝗲𝗻𝘁𝗿𝗮𝗹𝗶𝘁𝘆 𝗼𝗳 𝗯𝗿𝗮𝗶𝗻 𝗮𝗿𝗲𝗮𝘀
New paper I anticipate will become a classic in neuroscience and a must-read for students at all levels.
Understanding brain function beyond brain areas.
doi.org/10.1038/s41593…

English
Dezső Németh retweetledi
𝗛𝗼𝘄 𝗱𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗶𝘀 𝘁𝗵𝗲 𝗯𝗿𝗮𝗶𝗻-𝘄𝗶𝗱𝗲 𝗻𝗲𝘁𝘄𝗼𝗿𝗸 𝘁𝗵𝗮𝘁 𝗶𝘀 𝗿𝗲𝗰𝗿𝘂𝗶𝘁𝗲𝗱 𝗳𝗼𝗿 𝗰𝗼𝗴𝗻𝗶𝘁𝗶𝗼𝗻?
Distributed brain processing, this goes to the top of the list!
doi.org/10.1038/s41583…

English