@CarlosZarattini Deixa ver se eu entendi sua posição: então o dado que desmonta essa mentira de vez diz que menos de 3% dos beneficiários trabalham de carteira assinada... Puxa, 3% é realmente um desmonte...
Português
bgeneto
115 posts



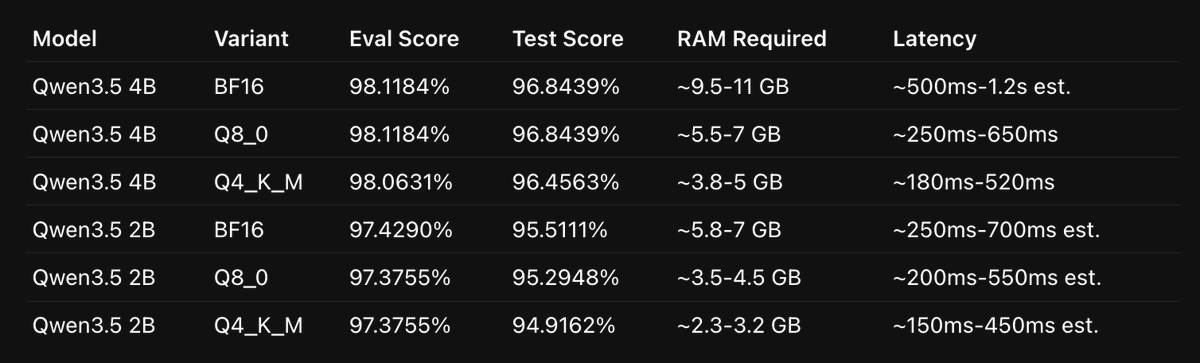




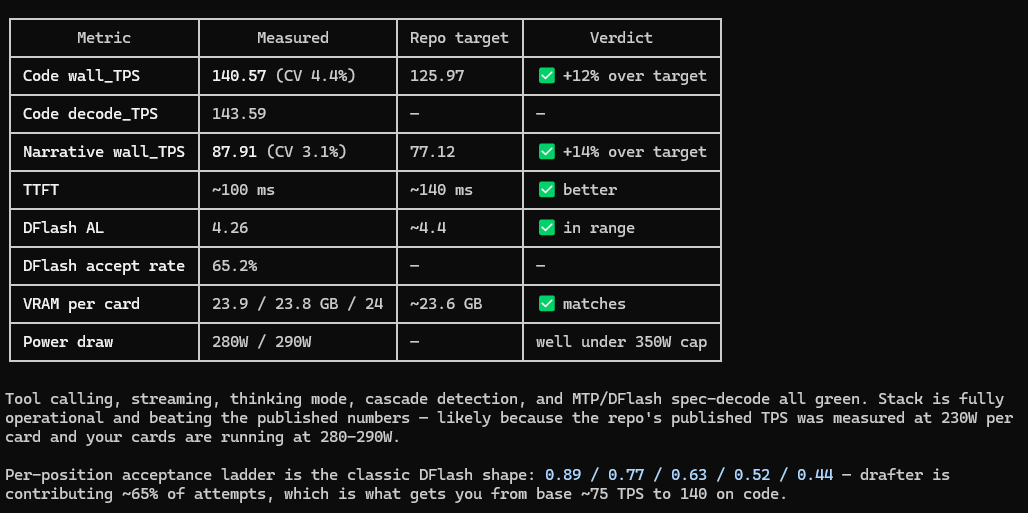



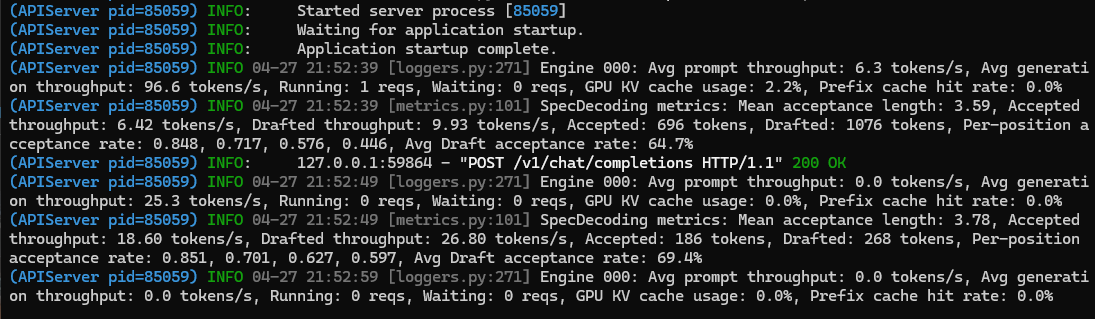










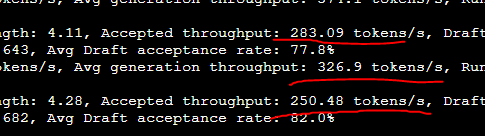
My 4090 went from 26 -> 154 tok/s Qwen 3.6 27B🤯 Same GPU. Same Q4_K_M . No FP8, no extra quant. The unlock: ik_llama.cpp + speculative decoding using Qwen3-1.7B as the draft model. 85% acceptance rate. Full config + benchmarks 👇🏻