
nb2sy
7.3K posts
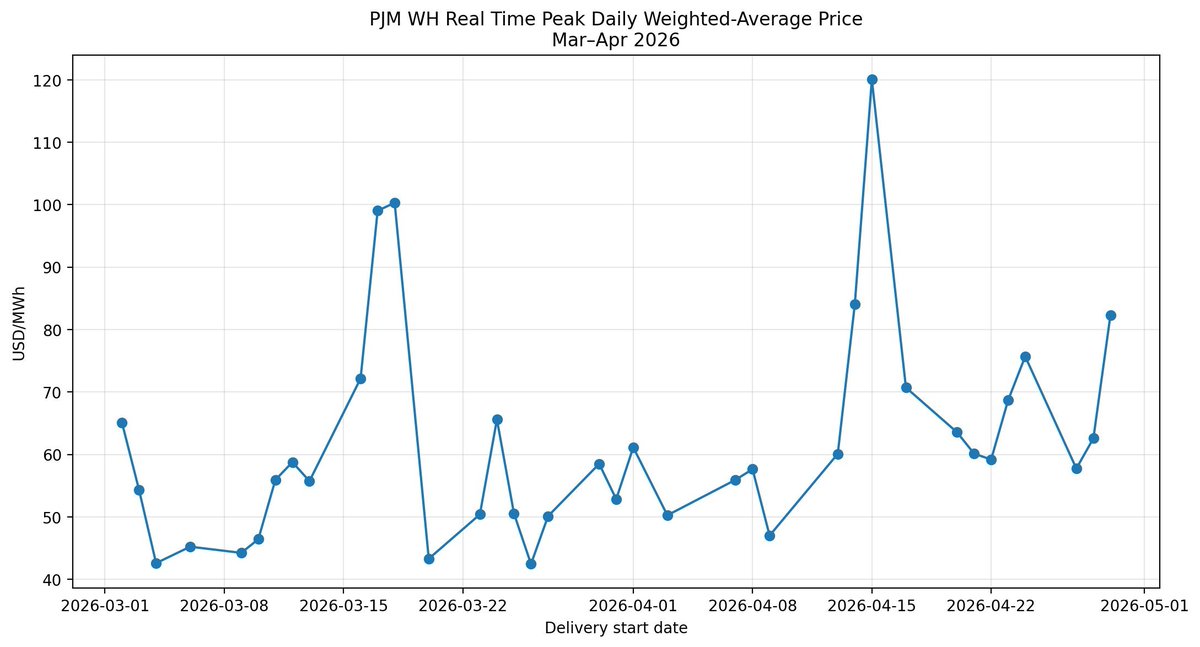

GPU spot prices continuing down from their spike.


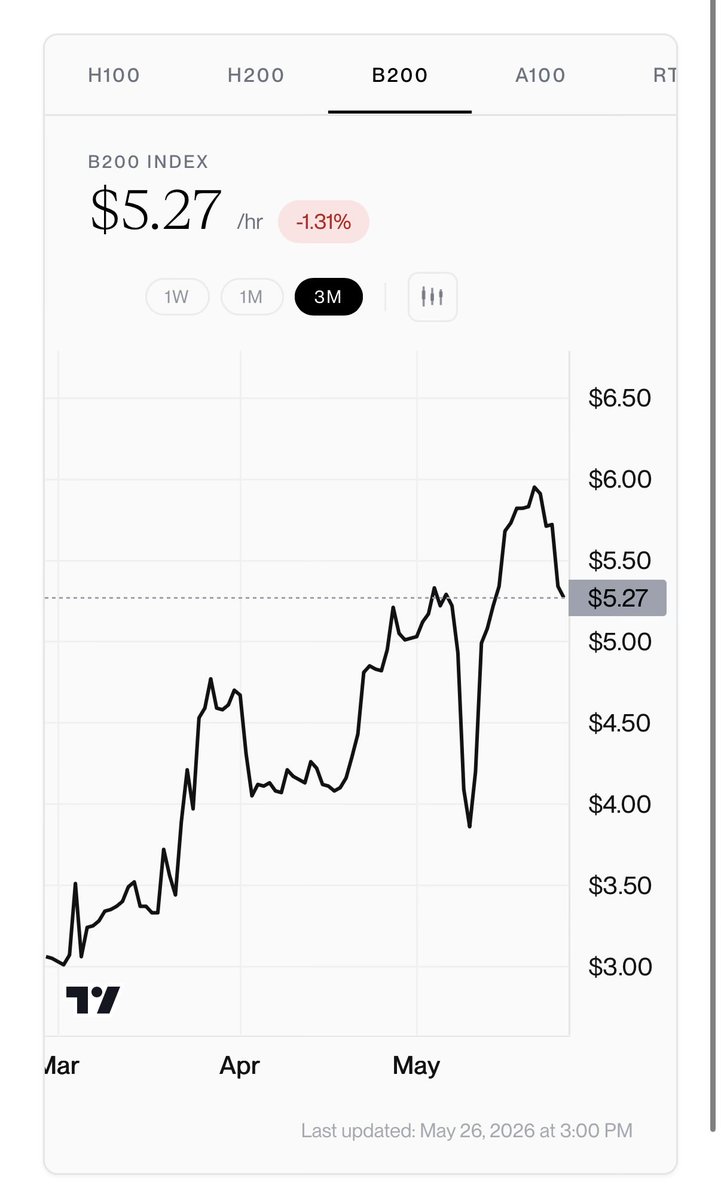
Brandon Carl@brandonjcarl
More GPU price normalization via @OrnnExchange. Easing is across H100, H200, B200 and A100.
English
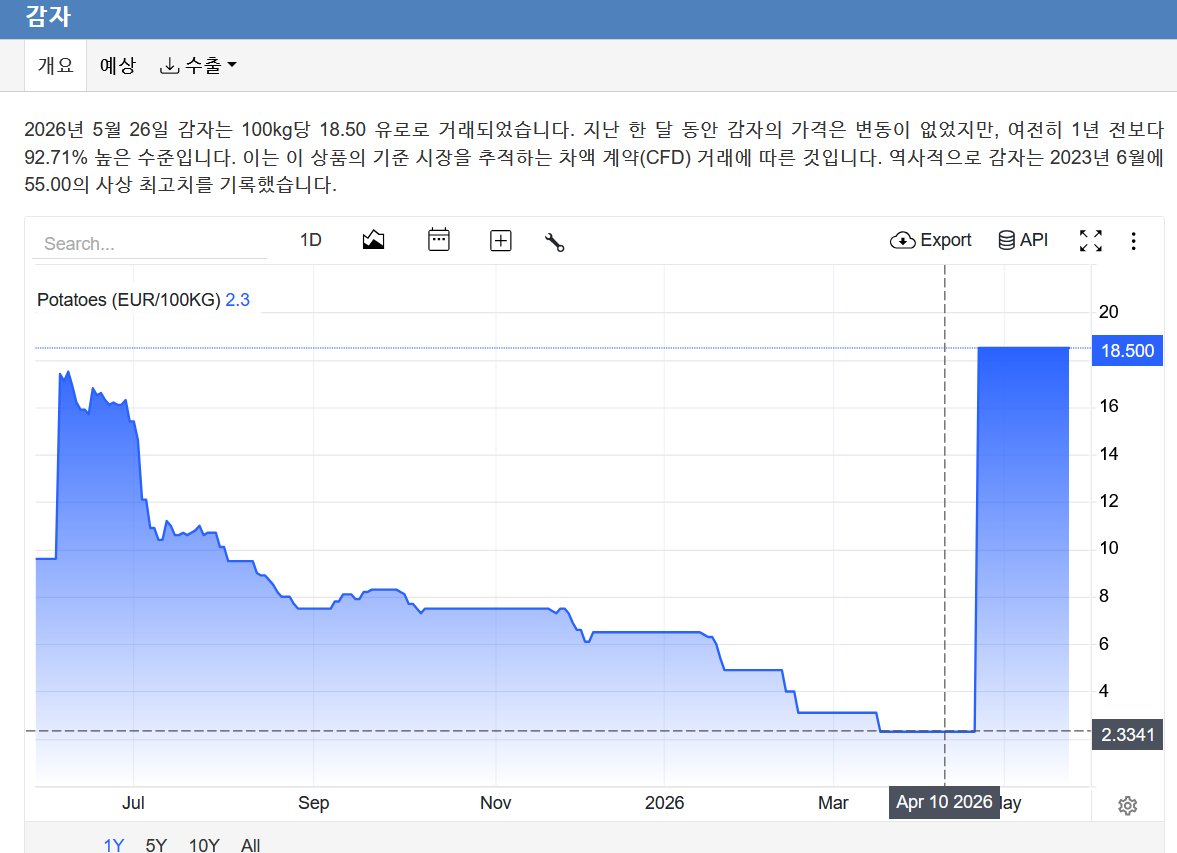

-12% since earnings.
Let consumers eat chips!
Barchart@Barchart
BREAKING 🚨: Walmart $WMT Timberrrrrrrrrrrrrr 📉📉📉
English


@blitzdolls @takis2910 Let’s wait and see. The market is currently expecting quarterly growth of more than 30%.
English


Taiwan's April 🏭 production growth slowed as 🗝️ #chips output dropped to 11% y/y (was 26%), shallowest rate in >2yrs. Note 🇨🇳 semi-conductor output accelerated by 22%, outpacing 🇹🇼, whilst 🇺🇸 is short 10%. Trend (is your friend, or foe?)
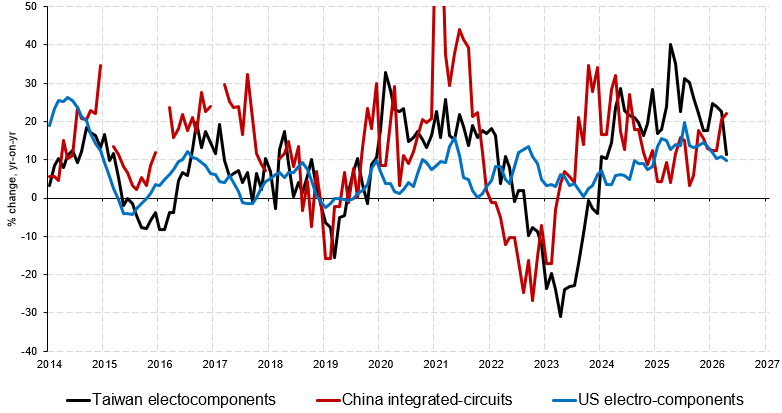
English
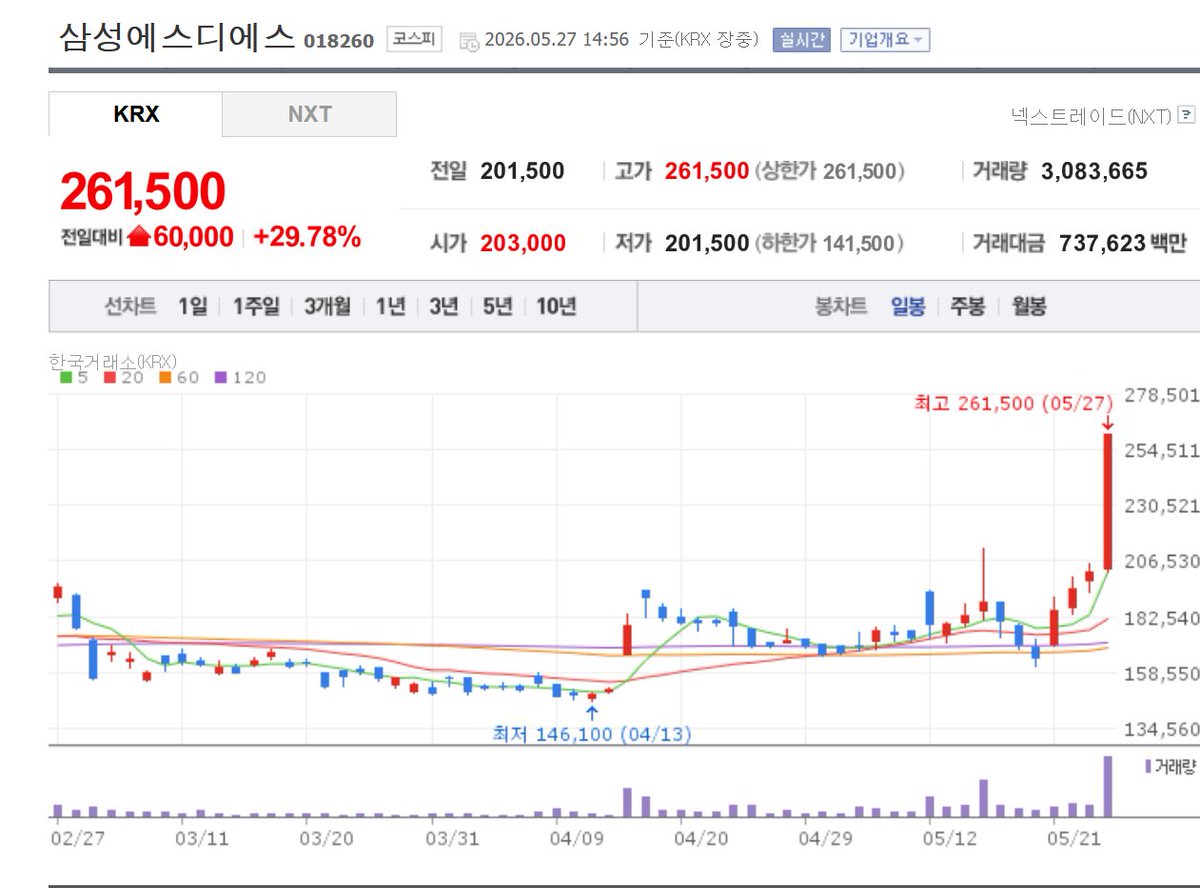


Signs of a slowdown in semis?
x.com/takis2910/stat…
Τάκης Χριστοδουλόπουλος @takis2910
Taiwan's April 🏭 production growth slowed as 🗝️ #chips output dropped to 11% y/y (was 26%), shallowest rate in >2yrs. Note 🇨🇳 semi-conductor output accelerated by 22%, outpacing 🇹🇼, whilst 🇺🇸 is short 10%. Trend (is your friend, or foe?)
English


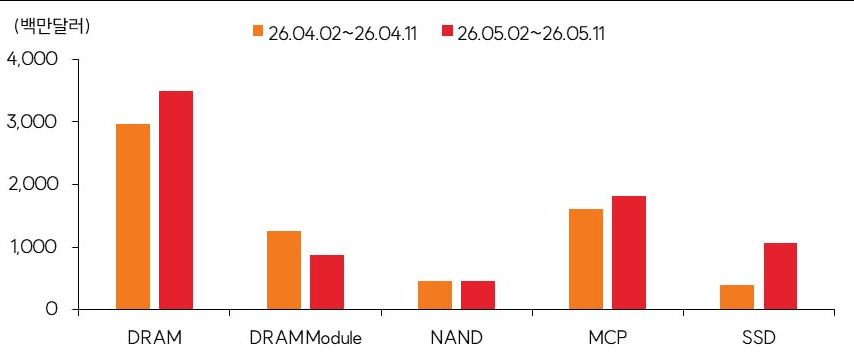
다시 말해서 하이퍼스케일러들이 지금의 CAPEX상승률을 지속할 수 있으려면 그들의 마진이 증가해야 하므로, 이들의 FowardEPS를 증가시켜 PER을 낮추던가, 반도체제조사들의 PER을 높히던가 둘중 하나는 되야한다는 말 입니다.
Rihard Jarc@RihardJarc
The FOMO in semis is palpable, and investor positioning is now heavily crowded in that space. At the same time, the sentiment is negative on hyperscalers, because of concerns regarding their CapEx spend on semis and questions on the ROI of that spend. But the catch is that if hyperscalers don't see good returns on their AI CapEx (semi spend), there won't be sustainable demand for semis, like the valuations and margins of many of these stocks are now pricing. So both can't be true. Either semis valuations have gone too far, or hyperscalers are too low.
한국어

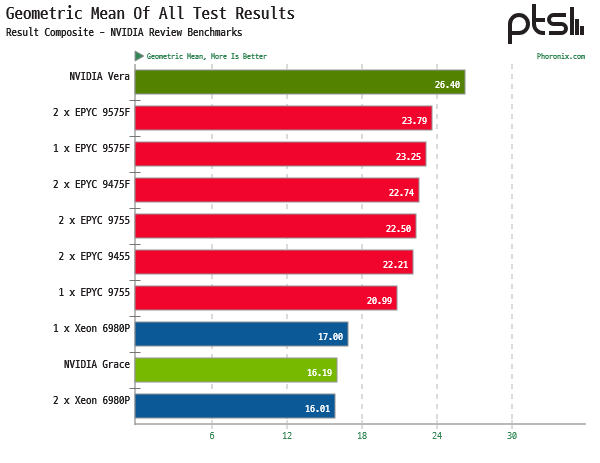
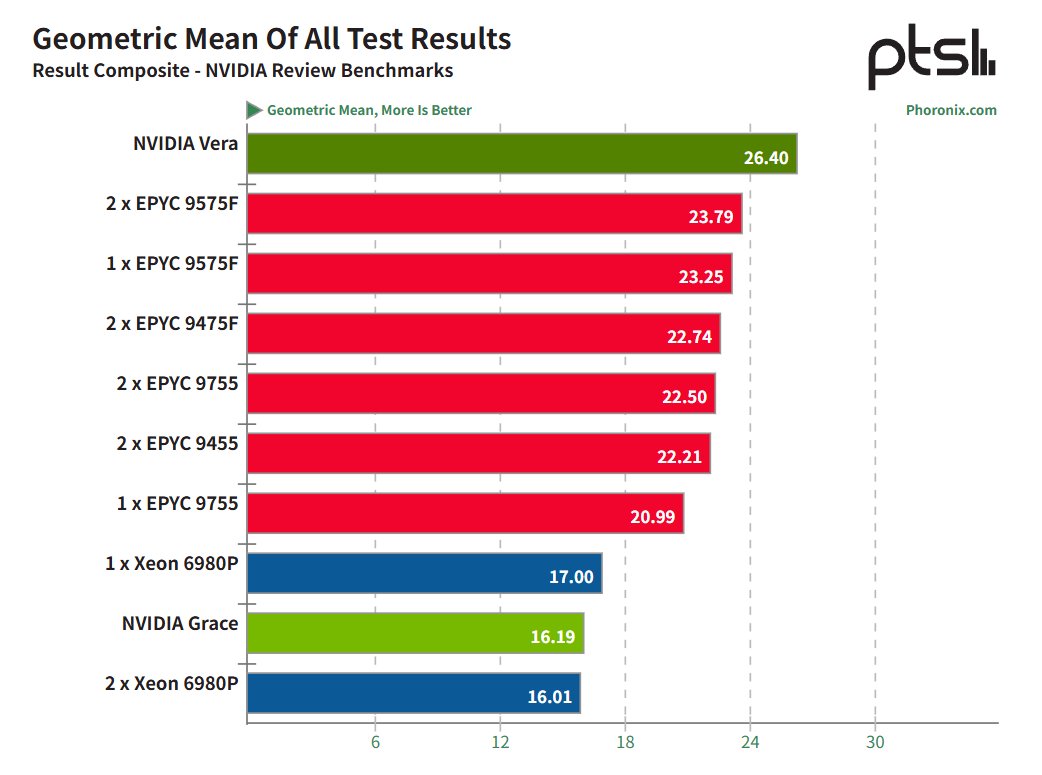
논지는 제 생각과 비슷합니다. 지금까지의 인프라투자는 전적으로 "특이점을 선점"하면 모든것을 "독식"한다는 전제 하의 경쟁이었습니다. 그러나 그간 자본지출 결과 더 공격적인 스케일업으로도 특이점도 달성할 수 없을 뿐더러, 더 이상 성능에 기여하는 영향이 적어지고 있습니다.
Dr Vinnie Boombatz@halfblindmonkey
Hearing Northland is downgrading $INTC: Summary Downgrading $INTC on valuation. INTC is making measurable progress in its turnaround, and we expect estimates to rise as demand for server CPUs picks up. However, we are modeling overall datacenter spending to decline in CY27 as hyperscalers become increasingly cash-strapped. Assuming INTC’s DC business grows by 40% in CY27, we get to an estimate of $3.20 and a P/E multiple of 38x the out-year. Even under this optimistic scenario, shares are expensive. We suspend our price target.
한국어
이것은 데자뷰인가. 불과 얼마전에 증권사들이 목표주가를 PER로 뻥튀기 할 것이라고 얘기했었죠. 어림짐작이 아니고, 제가 보는 데이터를 그들은 더 면밀히 볼텐데 그러면 어쩔 수 없이 PER을 올려야 한다고 계산기 튕겨보고 예언한 겁니다 .결과는?
Brandon Carl@brandonjcarl
UBS is raising their Micron forecast by 200% at the same time that DeepSeek has proven techniques that dramatically drop KV Cache needs. Exhibit 1. After years of “20% higher forecasts” they are racing to catch up to price action. Exhibit 2. Higher competition, higher input costs, algorithmic breakthroughs and long dated liability-style receivables are late-stage shortage indicators leading to early-stage gluts.
한국어
nb2sy retweetledi

Code Arena updated its rankings today. Alibaba's Qwen3.7-Max scored 1541, placing it above GPT-5.5, Gemini-3.5-Flash, GLM-5.1, and Kimi-K2.6. Only Claude Opus 4.7 and 4.6 rank higher. By vendor, Alibaba now ranks #2 globally.
Two things worth noting.
First, Code Arena is not a traditional benchmark. Developers submit real tasks. Models generate full, interactive web applications from scratch. Users then blind-vote on the results. It is one of the more credible measures of vibe coding ability available today.
Second, Qwen3.7-Max is designed as an agent foundation model. Long-horizon task execution and tool calling are core to its architecture. Alibaba says the model can sustain over 1,000 tool calls across 35-hour task sessions. Code Arena's format, building complete apps rather than solving textbook problems, aligns with that design. The score and the product thesis match.
Claude has held the top of this leaderboard for months. Qwen3.7 is the first Chinese model to crack into that tier. A notable data point for anyone tracking the global coding model race.

English
@solavia_A This chip means that a new market outside hyperscalers is opening up, and it also signals that the growth in HBM demand may slow. Mac Ultra models with 128GB or more memory are already seeing strong demand for running open-source models locally.
English

Intelの次世代データセンターGPU Crescent IslandがHBMではなくLPDDR5Xを使うと報じています。
基板画像ベースの話なので確定一次ソースではありませんが、20個のLPDDR5Xモジュールパッドが確認され、160GB構成になる可能性があるとされています。IntelがHBM不足とコストを避けるためにLPDDR5Xへ寄せていると見ています。
これはHBMが足りないだけで終わらずLPDDR5X、SOCAMM、サーバー向けDRAM、基板、電源回路、MLCCにも需要が移ります。HBMが詰まるほど、代替メモリや周辺実装の需要が増えると思われる。
日本語
몇 번 얘기한적 있는데 GPT-5.3이후 모델은 단일 AI모델이 아니라 AI그룹입니다. 왜인지 모르겠지만 파라미터를 늘리니까 Ai성능이 좋아져서 인프라 확장을 시작했던 것처럼 왜인지 모르겠지만 다수AI가 공동작업하면 결과가 더 좋아져서 지금까지 온거죠.
Brandon Carl@brandonjcarl
Remarkable results by pursuing parallel paths using Tiny Recursive Models. It simply destroys frontier LLMs on these puzzle tasks at orders of magnitude lower costs. It goes to show what using the right algorithm for the right tasks can achieve. alphaxiv.org/abs/2605.19943
한국어