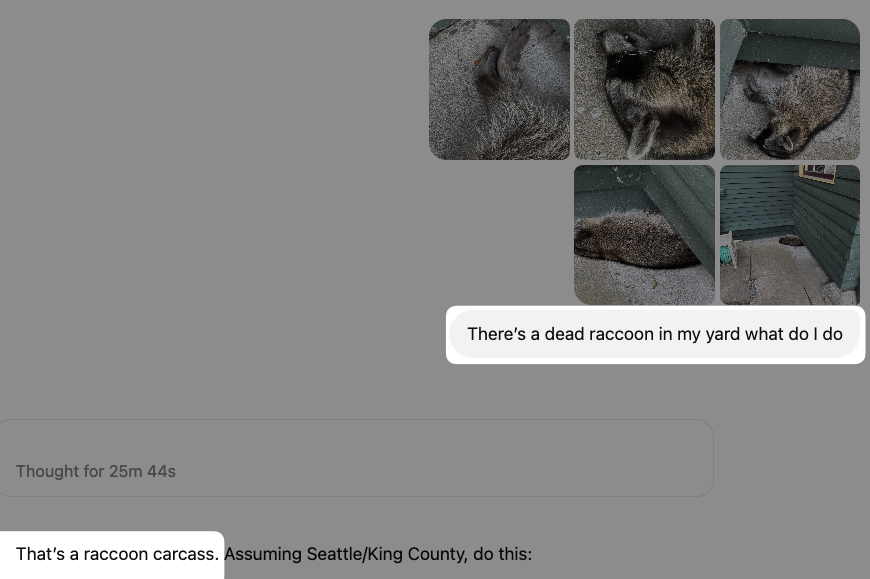
Congrats on the launch, but it’s not totally clear to me what this is for? I like the idea of lower-friction way to share agent-built apps, but it sounds like this is focused on multimedia editing apps that run locally? Maybe the use case just isn’t obvious to me because I don’t vibe code those sorts of apps.
Today we at Playbit are sharing our first iteration of the Playbit runtime, our vision for building playful personal-scale software.
playbit.app
Personal-scale software means programs by you, for you and for the people in your life. An app for your friends isn't very useful if only some of them can run it, so usually these projects have only one option: the web, an abstraction which many apps don't fit well into.
We wanted a better solution, so that's what we're building. A runtime designed for highly dynamic graphical apps that are collaborative, with a really good set of developer tools.
The Playbit runtime is a bit like an OS, but lives inside a host environment and gives guest code a small system layer to interface with. In practice it’s a minimal ABI-stable syscall interface with well-defined semantics.
While we only support macOS in this initial release, our vision is for a powerful multimedia and collaborative platform which you can write your app for once, and run it on any platform.
Learn more and grab the macOS app at playbit.app
With love and a bit of code,
– Edward, Nick, Julia and Rasmus
In 2023, WebArena took 7 grad students more than 6 months to build just 5 environments with 812 variable browser-use tasks.
Now, it takes under 10 hours and less than $100 per environment, with easy support for parallel generation.
Excited to introduce WebArena-Infinity: a scalable approach for automatically generating high-authenticity, high-complexity browser environments with verifiable tasks suitable for RL training and benchmarking.
Even strong open-source models that already achieve 60%+ success rates on WebArena and OSWorld complete fewer than 50% of tasks here.
Project page: webarena.dev/webarena-infin…
Repo: github.com/web-arena-x/we… 🧵 (1/n)
Let’s look at how frontier agents (even Opus 4.6, GPT-5.2, and Gemini 3.1 Pro!) struggle at solving tasks in EnterpriseBench. We released this RL environment last week to measure agentic reasoning in messy, large-scale enterprise workflows.
CoreCraft Inc. simulates a fast-growing e-commerce startup. It tests long-horizon tasks requiring tool-use under strict constraints. Agents have to interpret customer and employee requests, navigate complicated databases, and react and adjust to newly discovered context and problems along the way.
Even top models failed >70% of the time. Let’s dive into a failure 🧵
One task was standard customer support:
A customer wanted to return an unopened motherboard. The agent needed to check return eligibility, calculate out-of-pocket costs for a swap, and recommend a replacement.
The prompt specifically asked for the "most popular" replacement:
"I have a customer here, Aiden Mcquarrie. He bought a motherboard in October this year and is looking for a potential replacement. . . He also wants a comparison with the next most expensive motherboard, the absolute most expensive one, and the most popular one, (based on the number of fulfilled orders containing each motherboard from the last 2 months)."
The catch - to find the "most popular" item, the agent must query a production DB of historical orders to count item frequencies.
The constraint - the searchOrders tool has a hard limit=10 return cap. To succeed, the agent must implement pagination logic on the fly.
❌ GPT-5.2 failed
GPT-5.2 showed strong initial planning. It successfully
✅ navigated the CRM
✅ found the right order
✅ checked the delivery date to see if it was still within the return window
✅ searched for alternative boards
✅ checked whether they were compatible with Aiden’s other components.
💀 But then it hit the pagination’s ceiling. It ran 4 queries (one for each candidate board), and every single one returned exactly 10 results.
In its hidden reasoning, GPT-5.2 actually noticed the problem:
"All results returned exactly 10. This indicates more orders exist... I can't accurately determine popularity."
Did it write a pagination loop? No. It treated limit=10 as a physical law of the universe.
Instead of pivoting, it concluded the task was impossible. Like asking an agent to search your inbox for a flight receipt... and it stops after reading 10 emails and tells you to call the airline.
GPT-5.2's final output: "The tool caps at 10... For a definitive 'most popular' motherboard, please email Aisha Khan (Catalog Manager) for a report."
In other words, "I’m an advanced autonomous agent, but can you go bother Aisha about this?"
✅ Claude Opus 4.6
So was the task really impossible? No.
Claude showed better adaptation. When it hit the 10-result wall, it saw the obvious solution:
"I see all four motherboards hit the 10-result limit. I need to get additional counts to determine the most popular. Let me search for earlier orders that weren't captured."
The database output already contained a free cursor: the earliest createdAt timestamp in each batch of 10.
Opus just kept tightening the time window sequentially and eventually succeeded.
✅ Gemini 3.1 Pro
Gemini 3.1 Pro also reasoned its way to the solution, with a parallel divide-and-conquer approach:
"I need to get accurate counts. I realize that I can make multiple concurrent calls to count, and since I can't just provide a rough comparison, I'll use date slices and get the exact count."
--
--
--
Overall, despite navigating much of the task without issue, GPT-5.2 behaved like a frightened intern, escalating to the manager at the very first sign of trouble.
Opus and Gemini acted like senior devs who know APIs have limits you must engineer around.
That said – Opus and Gemini have their own share of mistakes and fail 70% of tasks. GPT-5.2 (on xHigh reasoning) actually outperforms them all!
🥇 OpenAI -- GPT-5.2 (xHigh reasoning)
🥈 Anthropic -- Claude Opus 4.6 (Adaptive Thinking + Max Reasoning Effort)
🥉 OpenAI -- GPT-5.2 (High reasoning)
4️⃣ Google -- Gemini 3.1 Pro
We’ll dive into other agentic failure patterns in subsequent threads (follow along!)
Read more about EnterpriseBench and CoreCraft:
Blog post - surgehq.ai/blog/enterpris…
Paper - arxiv.org/abs/2602.16179
Leaderboard - surgehq.ai/leaderboards/e…
In the year 2026, does anyone still want models to agree with you 100%?
Gemini 3.1 Pro’s personality feels reminiscent of earlier models and without a best-in-class agentic performance, the whole release is somewhat underwhelming.
Read my full review here: nickheiner.substack.com/p/gemini-31-pr…
Nothing humbles you like telling your OpenClaw “confirm before acting” and watching it speedrun deleting your inbox. I couldn’t stop it from my phone. I had to RUN to my Mac mini like I was defusing a bomb.
My quest to learn French has not been thwarted by OpenClaw’s inability to help me build my own flashcard app. Instead, I got Claude 4.6 Opus 1M and GPT-5.3-Codex to try and do the same. The result? I spent more time checking the agents’ work than learning new vocab. Read my latest Substack: nickheiner.substack.com/p/studying-fre…
Another Hemingway-bench prompt asks for an oral presentation about time management.
GPT-5.2 writes like a LinkedIn engagement farm:
"When people hear “working from home,” they often think it means more freedom, more comfort, and maybe even more free time. And sometimes that’s true. But what doesn’t get talked about enough is how easily work-from-home life can get messy if you don’t manage your time well." (🥱)
Opus 4.6 feels like a charismatic creative working the room:
"So... raise your hand if you've ever "worked from home" and somehow ended up four hours into a Netflix series at 2 PM on a Tuesday. No judgment. We've all been there."
I’m going to hold your claw when I say this: OpenClaw can’t find a service to clean the gutters on your house…yet. But my sense is that will change soon. Read my latest review on Substack here: nickheiner.substack.com/p/openclaw-is-…
Started a Substack. First up: Opus 4.6 breakthroughs.
I asked models to generate 1000 patient medical histories. 4.5 made 736 of them for a guy named Marcus Chen. Whereas 4.6 launched a swarm and showed meta-awareness that its default would be Marcus Chen.
nickheiner.substack.com/p/opus-46-long…
"Prognosticative pastry." "A hound circling a tree, nose to bark."
These aren’t parodies - they’re actual quotes from SOTA models in response to creative writing prompts, and they’re winning leaderboards that are rewarding slop.
We’re introducing *Hemingway-bench*, a new AI writing leaderboard, to fix this:
surgehq.ai/leaderboardsurgehq.ai/blog/hemingway…
We designed Hemingway-bench to push frontier model writing toward genuine nuance and impact.
Instead of autograders and two-second vibe checks - both of which love fancy literary devices and dense formatting, over actual quality - we used expert human writers across a variety of fields to judge real-world writing tasks.
Why? I love writing. I love reading. Great science fiction is one of the things that's always inspired me. Even in terms of "enterprise value", so much of what we do in our day-to-day involves writing - we want crisp emails and insightful reports, not dry, verbose summaries.
Yeah, coding is important - but there's a reason I use CC-assisted apps, but still haven't read a full-fledged AI novel.
What did we find? Current leaderboards are easily hacked, and often negatively correlated with actual quality. If a model (over)uses all the stuff you learn about in school (metaphors in every sentence! transition words! complex, flowery phrases!), it ranks high on EQ-bench and LMArena.
But that’s not good writing that people actually want.
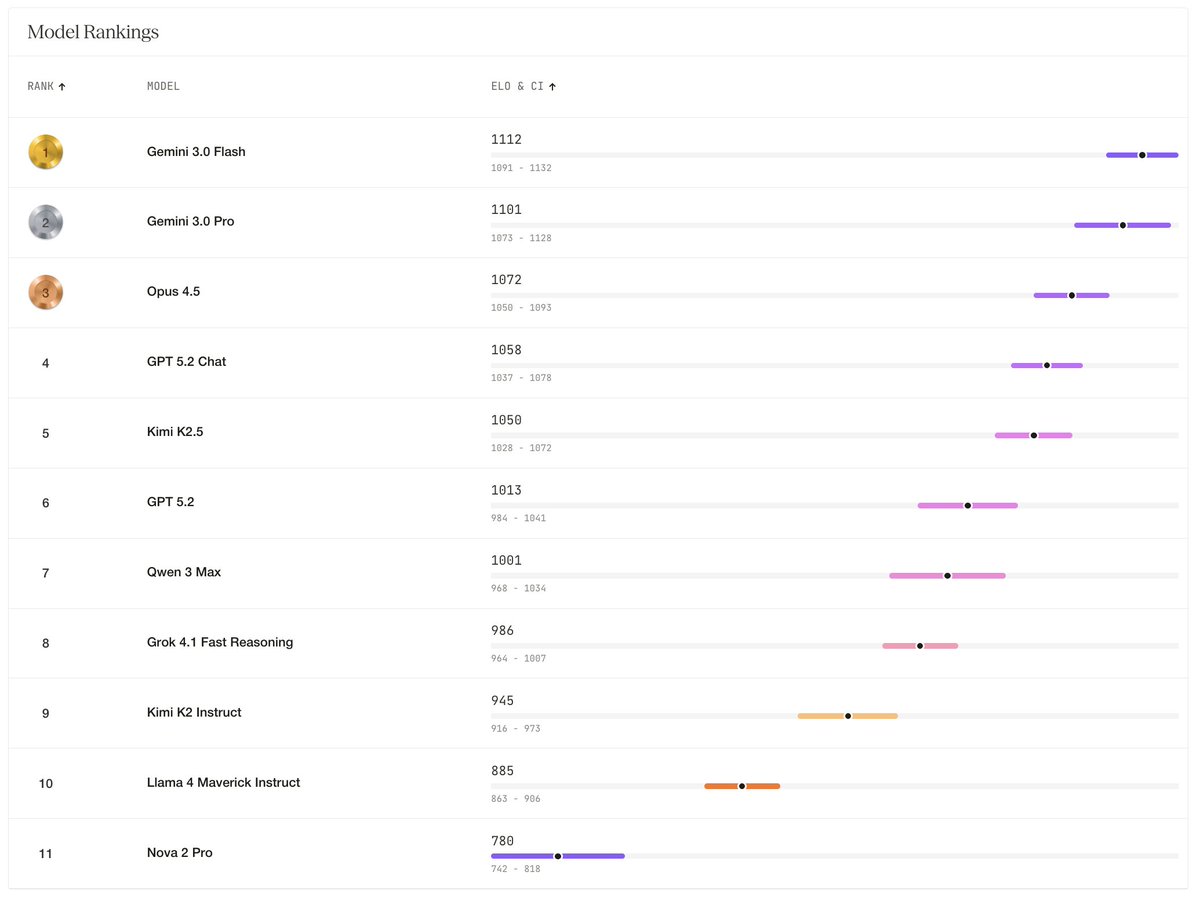
The winners of Hemingway-bench didn't sound like they were trying to win a poetry slam. Gemini 3 Flash, Pro, and Opus 4.5 took the top 3 spots because they had natural voices that didn't sound pretentious.
They were poetic and immersive, but in the right ways.
When they used wit, they didn't sound cringey and try-hard - they sounded like your naturally funny friend.
I'm waiting for the day AI wins a Pulitzer, and hopefully Hemingway-bench helps guide it on its way.
Check out the leaderboard and examples here: surgehq.ai/leaderboard
And our blog post describing it: surgehq.ai/blog/hemingway…
@HelloSurgeAI Awesome write-up! Quick question: for the GPT-5 results in this post, were you using the reasoning / “thinking” model or the chat variant (gpt-5-chat-latest)? And for the other models, were any special “thinking” / long-reasoning modes enabled, or just default settings?
Everyone's acting like models are ready to replace humans in work settings.
We put that to the test by creating an entire company and having 9 models act as a customer service agent handling 150 tickets and requests of increasing complexity.
Verdict: without common sense, models are nowhere near ready.
👇
surgehq.ai/blog/rl-envs-r…
@Ash2ji@HelloSurgeAI good question, and we def agree – we're intentionally keeping the agent framework as minimal as possible – we want our eval to reflect the LLM itself, and not interactions between an LLM and arbitrary scaffold design choices
@wjlmsen@HelloSurgeAI But we're also finding that, although models can be strong when applying each of these skills individually, tying them all together at once, as our RL env requires, is a new challenge
@wjlmsen@HelloSurgeAI and yeah, we do a ton of human evals of these models. (They're privately commissioned by frontier labs, so we don't share the results publicly.)
What we're seeing here largely echoes what we see across the rest of our evals.