
Nico Scapel
405 posts

Nico Scapel
@nicoscapel
Designer at the intersection of art, technology and systems. Founder @hardsimple_ltd
London, UK Katılım Nisan 2008
5.1K Takip Edilen512 Takipçiler

🚨BREAKING: Microsoft open sourced a 4B parameter model that generates production-ready 3D assets from a single image, and the speed numbers are genuinely hard to believe.
It's called TRELLIS.2 and it uses a new geometry format called O-Voxel that can be converted to a textured mesh in under 100 milliseconds on CUDA, which means real-time 3D asset generation is now actually within reach.
Most image-to-3D tools force you to pick between speed, quality, and topology correctness. TRELLIS.2 refuses that tradeoff by representing geometry natively in a sparse voxel format that supports arbitrary complexity from the start.
→ Outputs GLB files with full PBR texture maps ready for Blender, Unity, and Unreal Engine
→ Pretrained TRELLIS.2-4B checkpoint available directly on Hugging Face with model card and usage details
→ Web demo live now so you can test it without installing anything
4.6K stars. MIT License. 100% Opensource.
Link in comments.
English

English

@nicoscapel @Dimillian Thank you for sharing, this is exactly what I was looking for. It's expensive though!
English


robot carrying things on stairs is such a low hanging fruit for very useful robotics
engadget.com/big-tech/amazo…
English
Reviewing imaginary products in Sora 2 with @ijustine cameo 😮 still ways to go on product design I would not put my groceries on this 🤣
English

1/4 LLMs solve research grade math problems but struggle with basic calculations. We bridge this gap by turning them to computers.
We built a computer INSIDE a transformer that can run programs for millions of steps in seconds solving even the hardest Sudokus with 100% accuracy
English
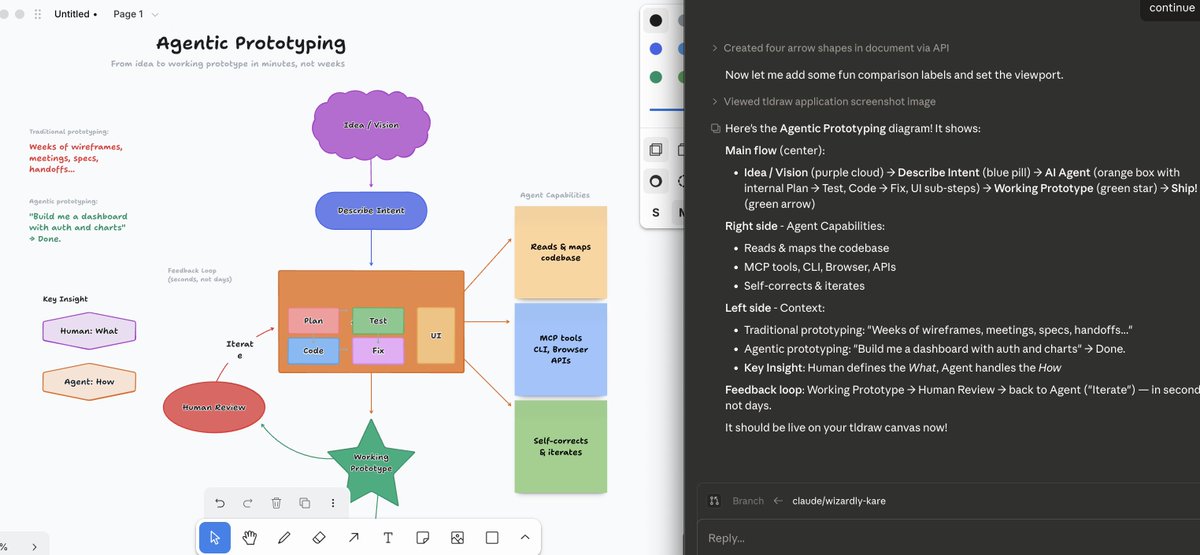

Just published github.com/tldraw/tldraw-…
- Mac arm only atm
- start the app
- ask your agent to curl localhost:7236
tldraw@tldraw
1. create a diagram from my code 2. ok, I updated the diagram, please update the code to match it
English
@doodlestein The one person industrial research and hardcore programming lab 👀
English

My FrankenSQLite project is rapidly approaching completion. In honor of that milestone, I created a nice website for the project that tries to explain in the most intuitive and visual way possible all of its cool technical innovations and advantages:
frankensqlite.com

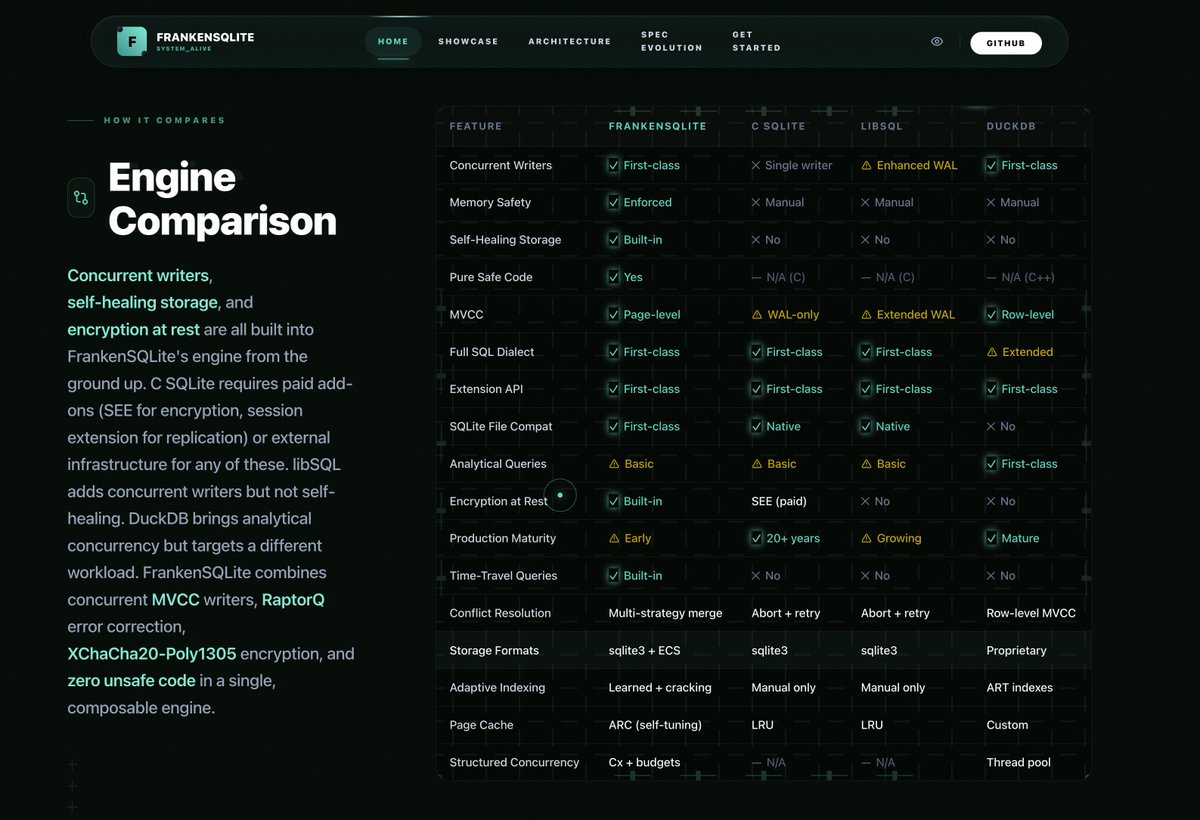
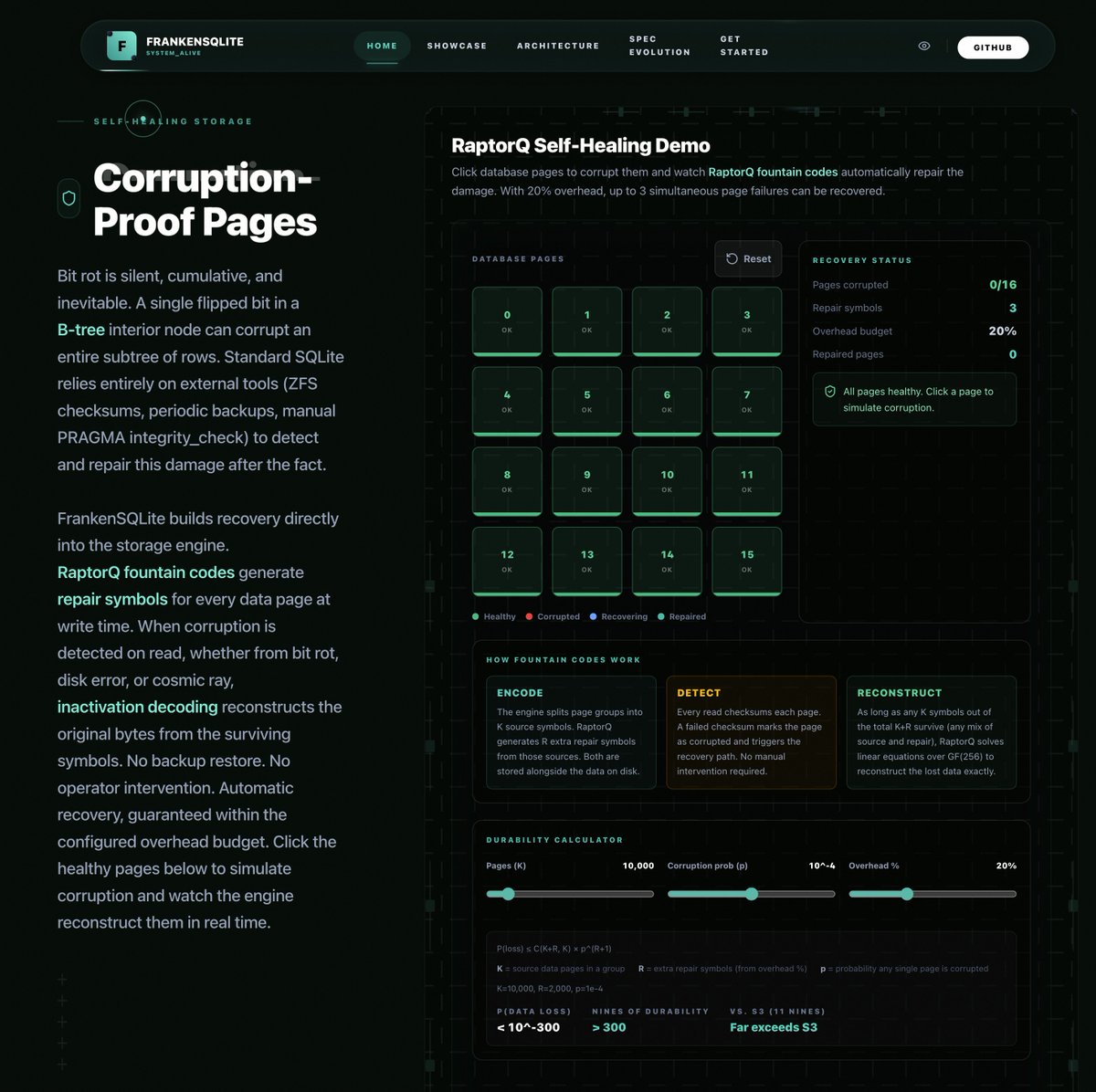
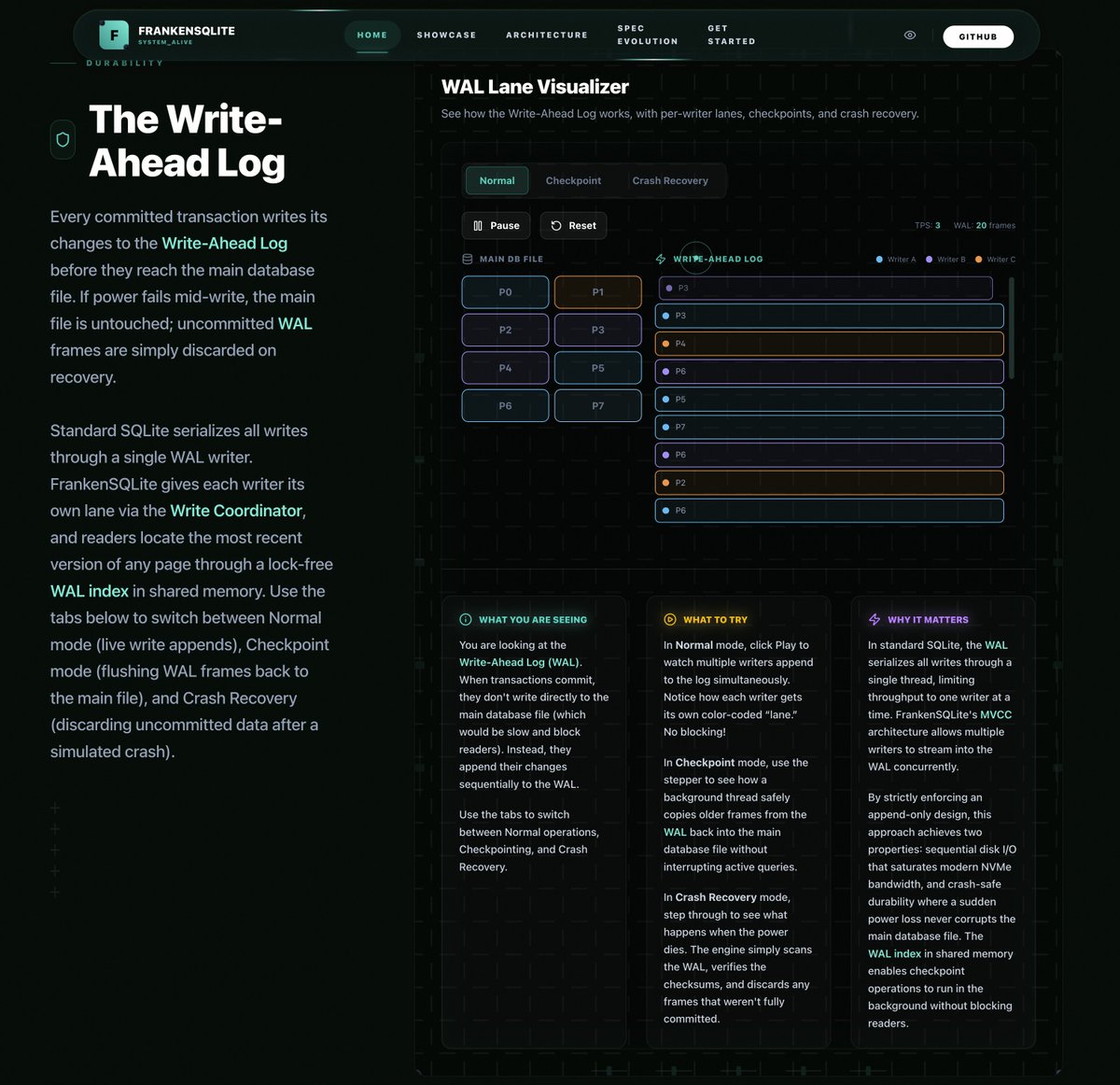
English
@doodlestein Great use of agents to build technical docs with interactive visualizations. Maybe beyond prompt and specs these are the type of artifacts to iterate on during planning and research stages - optimized for human understanding. Eg start with the docs vs document the code.
English
I made a nice website for my asupersync library (a Rust library for asynchronous programming that is a complete replacement not just for tokio, but for the entire tokio ecosystem, with a much more robust "correct by design" approach grounded in structured concurrency research):
asupersync.com
I tried to take all the crazy "Alien Artifact" math ideas that make the project so powerful and make them as intuitive as possible through a series of 30 different interactive visualization exhibits, each with a narrative explanation.
Even if you don't use Rust, you might find this fascinating to learn about. These ideas are normally relegated to journal articles and couched in very impenetrable mathematical terms, making them pretty inaccessible.
I think I'm likely the only one to even try to make some of the more esoteric things simpler for non-experts in concurrency research to understand (and trust me, I wanted this as much for my own benefit, since the clankers are the ones that came up with all this lunacy!).
Essentially every single substantive idea from asupersync is explained in this way. Hope you like it!
English
This could be a big unlock - we are slowly reverse engineering how brains train for very lossy but generalized and robust spatial & semantic sensing. Makes me think of Project Prakash which pioneered vision recovery in adults by focusing on simple parallax and segmentation exercises. nei.nih.gov/about/our-impa….
English



We’re excited to introduce Doc-to-LoRA and Text-to-LoRA, two related research exploring how to make LLM customization faster and more accessible.
pub.sakana.ai/doc-to-lora/
By training a Hypernetwork to generate LoRA adapters on the fly, these methods allow models to instantly internalize new information or adapt to new tasks.
Biological systems naturally rely on two key cognitive abilities: durable long-term memory to store facts, and rapid adaptation to handle new tasks given limited sensory cues. While modern LLMs are highly capable, they still lack this flexibility. Traditionally, adding long-term memory or adapting an LLM to a specific downstream task requires an expensive and time-consuming model update, such as fine-tuning or context distillation, or relies on memory-intensive long prompts.
To bypass these limitations, our work focuses on the concept of cost amortization. We pay the meta-training cost once to train a hypernetwork capable of producing tasks or document specific LoRAs on demand. This turns what used to be a heavy engineering pipeline into a single, inexpensive forward pass. Instead of performing per-task optimization, the hypernetwork meta-learns update rules to instantly modify an LLM given a new task description or a long document.
In our experiments, Text-to-LoRA successfully specializes models to unseen tasks using just a natural language description. Building on this, Doc-to-LoRA is able to internalize factual documents. On a needle-in-a-haystack task, Doc-to-LoRA achieves near-perfect accuracy on instances five times longer than the base model's context window. It can even generalize to transfer visual information from a vision-language model into a text-only LLM, allowing it to classify images purely through internalized weights.
Importantly, both methods run with sub-second latency, enabling rapid experimentation while avoiding the overhead of traditional model updates. This approach is a step towards lowering the technical barriers of model customization, allowing end-users to specialize foundation models via simple text inputs. We have released our code and papers for the community to explore.
Doc-to-LoRA
Paper: arxiv.org/abs/2602.15902
Code: github.com/SakanaAI/Doc-t…
Text-to-LoRA
Paper: arxiv.org/abs/2506.06105
Code: github.com/SakanaAI/Text-…
GIF
English

After many years of development, I’m excited to share the interior of the first electric Ferrari designed by LoveFrom. Tactile controls and digital interactions blend into one cohesive interface, shaped through deep collaboration across engineering, interaction, graphics, typography, sound, and industrial design. So incredibly proud of the thoughtfulness and care the team brought to every detail.
ferrari.com/en-US/auto/fer…
English

slop is basically content that maximizes reward to perplexity ratio. Mechanistically, this is reward hacking by means of collapsing output distribution into a basin with a few Pareto-optimal patterns, essentially constructing a degenerate grammar specific for this training setup.
Andrej Karpathy@karpathy
Has anyone encountered a good definition of “slop”. In a quantitative, measurable sense. My brain has an intuitive “slop index” I can ~reliably estimate, but I’m not sure how to define it. I have some bad ideas that involve the use of LLM miniseries and thinking token budgets.
English




This is a recently completed British train station. It is pathetic, value engineered to a level of comatose ugliness that dispirits & dulls the mind, dissuading passengers & degrading the trains that run through it. It is not civic or sociable architecture....

English
Nico Scapel retweetledi

Introducing hardsimple.
A design and technology studio exploring the next wave of computing: intelligent, collaborative, and spatial.

English
Drawing isn’t about mastering faces or trees. It’s about learning to see. Once you can see, you can draw anything.
Design isn’t about making apps or UIs. It’s about being deeply curious about people. Once you truly observe, you can design anything.
English
Prompt: A French art house film trailer about 'le slop' / Sora 2
English

Thanks for asking:
Here is some more research and the researchers extending and confirming the work of Professor Claude Shannon in tests Distinguishing, another way to judge the throughput not using bits per second scales, published in "Applications of information theory to Psychology", Holt, 1955 pages 67-75:
•Garner & Hake, 1951, Points of scale, 3.2 bits of Distinguishing
•Pollak, 1952, Pitch, 2.2 bits of Distinguishing
•Garner, 1953, Loudness, 2.1 bits of Distinguishing
•Eriksen & Hale, 1954, The size of Squares, 2.2 bits of Distinguishing
•McGill, 1954, Points Of Scale, 3.0 bits of Distinguishing
•Attneave, 1955, Pitch detection in Orchestra leaders, 5.5 bits of Distinguishing
•Beebe, 1955, Sugar Concentration, 1.0 bits of Distinguishing
•Klemmer & Frick, 1953, Points on a surface, 4.4 bits of Distinguishing
•Pollack & Frick, 1954, Musical Pitch, 7.0 bits of Distinguishing
English
Humans have a Shannon Limit to how much information they can process in any given second.
An astonishingly low ~60 bits per second from sense organs.
This means human consciousness is always limited.
I remade this video for clients about a decade ago.
English