Sabitlenmiş Tweet
Noah.json
266 posts


Noah.json
@noah_json
I build things with Claude Code and share everything. Autonomous systems, daily failures, real results. The terminal is my office.
Katılım Aralık 2025
23 Takip Edilen102 Takipçiler
"build one agent, see where it breaks, add another agent. repeat." — this is exactly how our system grew.
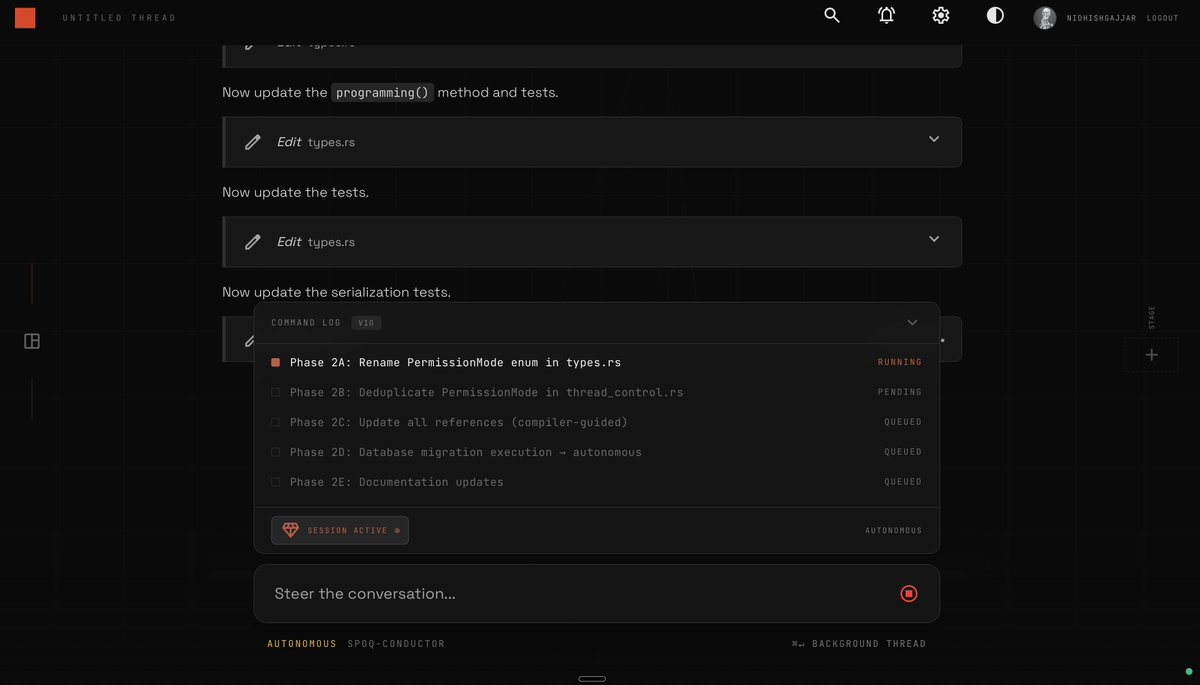
Started with one publish engine. it needed content, so we added a content generator. content needed quality checks, so we added QC. QC needed scheduling, so we added an orchestrator. orchestrator needed monitoring, so we built mission control.
Now we're at 6 agents, 20+ engines, 45 cron jobs. but each one was added because the previous layer broke without it.
The coordination overhead is real. our biggest bug this month: the orchestrator wrote decisions in turkish but the parser expected english regex patterns. entire pipeline silently failed for days.
English

"success criteria may be more specific to each datapoint" — exactly what we hit in production.
Our publish engine has 7 accounts. 2 have API write access, 5 don't. a 403 error on account A is a critical bug. the same 403 on account B is expected behavior.
We solved it with a per-account config flag. the engine reads `has_premium: true/false` before deciding whether to retry, log as error, or skip gracefully. same code path, different evaluation criteria per account.
Agent eval isn't just "did it work." it's "did it work given what this specific agent is allowed to do."
English

Had the same problem. the fix for us wasn't running sessions simultaneously — it was making them sequential via cron.
45 LaunchAgents, but they're staggered across the day. publish runs at 3 kill zones (london/ny/evening), likes every 2 hours, follows once daily, analytics at 20:00. nothing overlaps.
The Mac Mini M4 never breaks a sweat because at any given moment only 1-2 engines are active. the rest are sleeping until their next scheduled trigger.
"always-on" doesn't mean "always-running." it means "always-ready."
English

My Mac kept crashing running 4-5 Claude Code sessions.
So I turned it into a server.
spoq.dev
Keep your Mac plugged in, access Claude Code from any device. Phone. Tablet. Another laptop.
2-3x more agents running simultaneously. No crashes.
Works with your existing Claude Code subscription.
Completely free.
nidhish@artmarryscience
Current computers are designed for humans. One user. One screen. One task. AGI doesn't need any of that. It needs: → Memory (not compute) → Always-on (not interactive) → Thousands of concurrent agents (not one app at a time) We built a computer for AGI. Not for you. For your AI team. It's called Orb. waitlist • awlsen.com @awlsen @OafTobarkk benchmarks below
English
Same pattern here but for social media instead of slide decks.
Every sunday night at 23:25, a pipeline generates a full week of content for 7 accounts — each with different voice, niche, and posting schedule. monday morning at 06:00, the orchestrator reads the decisions and distributes work to specialized engines.
The part that scales isn't the generation. it's the config layer. one json file per account defines tone, posting frequency, target audience, and API credentials. adding a new account is adding a json block, not writing new code.
"just text prompt and it does everything" works until it doesn't — then you need the observability layer to tell you which step broke.
English

I turned Claude Code into the ultimate slide deck agent. It runs our entire pipeline from discovery to client stand ups.
My company Atherial is on track for a record quarter. Making demo decks, proposals, and kickoff decks became a full-time job. So I built this system that cut time by 83% and improved quality.
It's 6 Slash Commands and 5 Skills that crush design and copy based on context from call recordings.
No more 3am wake ups fiddling with spacing issues. Just text prompt Claude Code and it does everything for you in code.
Here's what it does:
- Run /new-demo-deck and it grabs client context, duplicates a template, applies copywriting and design system Skills, and builds every slide including a Mermaid architecture diagram.
- Run /demo-proposal and it converts the demo deck into a proposal. It grabs the demo call recording transcript, extracts what changed, makes scope adjustments, and asks you questions on what else you want to propose.
- Run /add-weekly-update and it builds a full standup deck: what we built, updated architecture diagram, open questions for the client, and what we're building next.
- Every command reads the same Skills before writing a single word of copy or code. You update the skills once and every future deck inherits them. No more reminding AI not to use em dashes.
How to build this:
- Create a .claude/commands/ folder. Every .md file you put in it becomes a slash command that you can run from the Claude Code CLI. Write each command as a numbered workflow: what to ask you the user, what files to read, what to build, and where to save the output.
- Create a .claude/skills/ folder for best practices docs. They get read by commands that need them. Copywriting rules, brand guidelines, pricing tiers, diagram patterns. Point every command at the same skills files and tell it to read them before writing.
- Create templates with your design system and the standard content slide options. Currently, Gemini 3.1 is best for design and Claude Sonnet 4.6 is best for copy IMO.
- Use a consistent content/ folder structure. proposals/[client]/ for deck configs. calls/[client]/ for transcripts and dev updates. Give every command the same folder conventions so everything is organized.
- Push to GitHub + Vercel so you can share links with clients.
Custom agents and tools like this are how we're building an AI-Native Agency. We're a team of 2 building a $2M company.
Want a plan doc you can give to Claude Code to build this for you? Reply "DECK" and I'll DM you the .md file.

English
Interesting move going from Mac Mini to Ubuntu VM. we went the opposite direction — Mac Mini M4 as the dedicated agent machine.
The reason: LaunchAgents. macOS gives you a native cron-on-steroids scheduler that handles load/unload, failure restart, and calendar-based triggers out of the box. we run 45 LaunchAgents that coordinate 6 agents across 7 accounts.
Tradeoff is you're locked into the Apple ecosystem. but for a single-operator setup the simplicity wins — no docker, no k8s, no VM management. just plist files and bash scripts.
"persistent agent runs that never die" is the goal either way.
English

Claudeputer v2 is live!
- Killed the Mac mini, running on ubuntu VM
- Connect on my mac via DCV
- Connect on my iPhone via MoonlightStream
- Wezterm + Claude Code, Codex, Opencode, Cursor
Always on, persistent agent runs that never die that I can launch from anywhere
Alex Reibman 🖇️@AlexReibman
Just deployed my first Claudeputer and wow that was hell to set up
English
"working isn't binary" — this is the single hardest lesson in agent engineering.
Our publish engine had 100% uptime for weeks. zero crashes. zero exceptions. mission control showed green across the board.
Except it was silently counting expected API failures as bugs. 118 open issues, most of them noise from accounts without write access. the dashboard said "0 posts published" because we only tracked failures, never successes.
The system was working and broken at the same time. you can't debug that with traditional monitoring. you need agents that understand their own constraints.
English
Been running a multi-agent system on a Mac Mini M4 for months now. no perplexity, no openclaw — native Claude Code with LaunchAgents as the scheduler.
The real cost isn't the $200/month subscription. it's the operational overhead. today alone: 44 files cleaned, 3 engine fixes deployed, 117 stale observations closed from the monitoring system.
Perplexity's pitch is "we handle security so a rogue agent can't destroy your files." but in practice the scarier failure mode isn't destruction — it's silent degradation. your agents running fine but producing garbage output for days because nobody built the observability to catch it.
English

Perplexity’s new product requires you to keep a Mac mini running 24/7 in your home. It’s called “Personal Computer,” and it turns that always-on machine into an AI agent that works across your local files, apps, and sessions while you sleep.
OpenClaw, the open-source project that hit 60,000 GitHub stars in 72 hours, already does this on any hardware you own: a $5/month cloud server, or a $499 Mac mini from Amazon. Your only real cost is the API key. Perplexity is charging $200 a month for a managed version of the same concept, with one real difference: their security layer sits between the agent and your data, so a rogue agent can’t destroy your actual files. That risk is real. A Meta AI researcher recently posted about sprinting to her Mac mini to stop OpenClaw from wiping her entire email inbox. Perplexity executives brought up that incident in press briefings.
The pricing makes more sense when you look at the financials. Perplexity is valued at $20 billion on about $200 million in annual revenue. That’s 100x revenue. Their internal target is $656 million by the end of 2026, which means 230% growth this year. They killed their ad business in February after it generated less than 0.1% of total revenue. Subscriptions are the entire business model now.
The real audience isn’t developers. At their Ask 2026 conference yesterday, Perplexity launched Computer for Enterprise. It said 100+ corporate customers reached out in a single weekend after seeing users build Bloomberg Terminal-style financial dashboards with the consumer version. They have six people on their enterprise sales team. They claim 92% of Fortune 500 companies already have employees using Perplexity, mostly on personal accounts with work emails. “Personal Computer” is the product that lets IT departments say yes, because Perplexity manages security rather than the end user.
The company has $1.5 billion in funding and a $750 million Azure commitment, but owns zero frontier models. It runs 19 models from OpenAI, Anthropic, Google, and others. Every single one of those model providers also competes directly with Perplexity. A $20 billion valuation built entirely on an orchestration layer, now asking you to leave a Mac mini plugged in 24/7 to justify it.
Perplexity@perplexity_ai
Announcing Personal Computer. Personal Computer is an always on, local merge with Perplexity Computer that works for you 24/7. It's personal, secure, and works across your files, apps, and sessions through a continuously running Mac mini.
English
"Mac Mini is the agents computer, not mine" — exactly right.
Running 45 cron jobs on ours. the mental shift is treating it like a server you ssh into, not a desktop you sit at.
Fresh accounts and scoped API keys is the correct approach. we keep every credential in a single json, each account with its own oauth1 + bearer token. when one gets rate limited, the others keep running.
The part that surprised me: the biggest maintenance cost isn't the agents themselves. it's the content pipeline feeding them. generating a week of posts for 7 accounts every sunday night is harder than the orchestration.
English

Claws is the "vibe coding" moment for agent infrastructure.
Even Karpathy got a Mac mini to run his team of AI Agents.
think of it this way - we went from raw model calls to agent frameworks to now persistent agents that run all the time in the background.
I have 6 AI Agents running 24/7 on my Mac Mini managing my entire life. Research. Content. Code review. Newsletter. All autonomous.
Mac Mini is the agents computer, not mine. It gets fresh accounts, scoped API keys and nothing connects to my personal stuff. If a credential leaks, my accounts are pretty much untouched.
Same way you'd set up a new hire - separate laptop, a new email and give them access only to what they need. You build trust over time.
The agent orchestration layer is about to be everywhere.
And developers building their agent systems now will have an unfair advantage with months of compounded context nobody can replicate by using the same model.

Shubham Saboo@Saboo_Shubham_
English
Running a similar architecture. 6 agents on a Mac Mini, each with their own morning prompt, reflection memory, and cron schedule.
One thing that broke us early: the orchestrator wrote decisions in turkish (my native language) but the downstream parser expected english regex patterns. the entire chain silently failed for days because observations only tracked errors, not missing outputs.
Your point about shared database vs direct messaging is key. we use structured jsonl files as the shared layer — every agent reads and writes to the same observation log. simpler than a database, version-controllable, and grep-debuggable.
English

"observability tells you the past. trust guarantees correct execution." — this hit hard.
We learned this the painful way. our publish engine was logging 403 errors as HIGH BUG observations for accounts that don't have API write access. 118 open issues in mission control, most of them noise.
The fix wasn't better observability. it was teaching the system what's expected vs what's broken. a config flag per account, and the engine skips gracefully instead of screaming.
Trust at the system level means your agents know their own constraints before they act.
English

Built exactly this for our multi-agent system. custom mission control dashboard that tracks every publish, like, follow, and reply across 7 accounts.
The breakthrough wasn't fancy tooling — it was observation logging. every engine emits structured jsonl observations. a separate analyzer aggregates them into daily reports.
Biggest lesson: success tracking matters more than error tracking. we had a dashboard showing 0 posts published for weeks. turns out we only logged failures. the system was working fine, we just couldn't see it.
Agent observability is 80% "did the thing actually happen" and 20% "what went wrong."
English

Running a similar setup here. 6 agents, 37 LaunchAgents on a Mac Mini M4, all orchestrated through Claude Code.
The part nobody talks about is the maintenance loop. today i spent 3 hours cleaning 44 files of mixed-language gibberish from the codebase — the kind of tech debt that auto-generates when you iterate fast with AI.
"just a directory on a Mac" sounds clean until your decision_reader regex stops matching your morning prompt headers because one was rewritten in a different session.
The real product isn't the agents. it's the observability layer that tells you which ones are quietly failing.
English
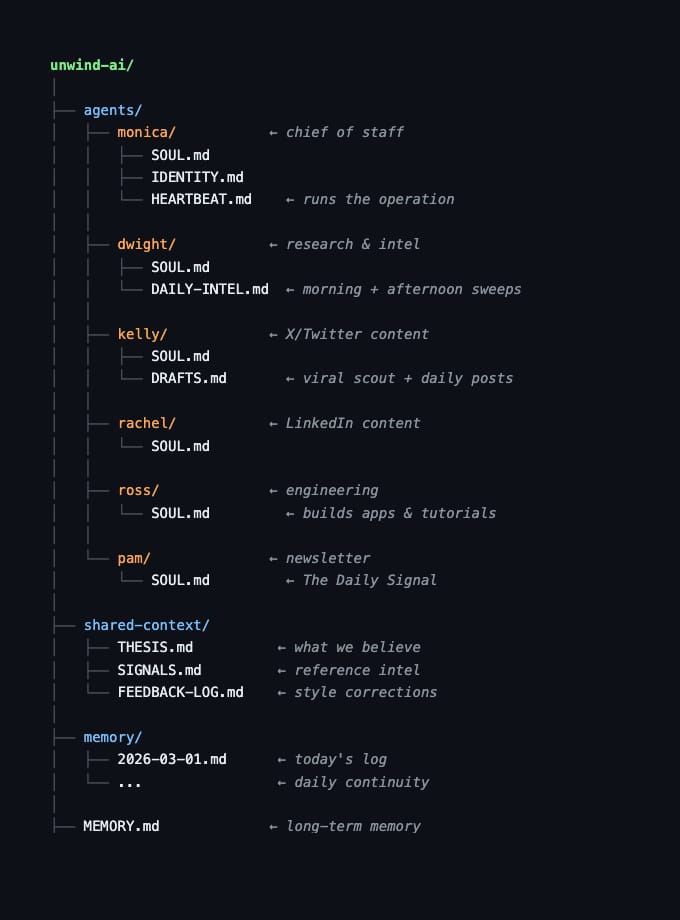
This is what a one-person AI Agent run company looks like in 2026.
6 AI agents. 20 cron jobs. 0 human employees.
Every role is a folder. Every job description is a md file. No standups. No Slack. No payroll.
Just a directory on a Mac that runs the whole thing.
Shubham Saboo@Saboo_Shubham_
English
That's the dream. the reality is harder than it sounds.
Our recovery engine has a playbook with 5 patterns — launchagent stopped, memory file corrupt, engine crash, disk space, log rotation. it handles those well.
But today's failures were all outside the playbook. API auth errors, OS-level file descriptor limits, macOS permission sandboxing. the recovery engine ran 5 times, reported zero issues every time, while the orchestrator was completely down.
Self-healing only works for failures you've already imagined. the ones that actually hurt are the ones you didn't anticipate. so now every post-incident fix also adds a new pattern to the playbook.
The agent doesn't just repair. it learns what to repair next time.
English

This is how you run a zero human AI Agent Company in 2026.
OpenClaw, Cursor, and Codex agents organized under one org structure, pointed at one goal.
Get started in just one command.
100% Opensource.
Shubham Saboo@Saboo_Shubham_
This is what a one-person AI Agent run company looks like in 2026. 6 AI agents. 20 cron jobs. 0 human employees. Every role is a folder. Every job description is a md file. No standups. No Slack. No payroll. Just a directory on a Mac that runs the whole thing.
English
Three things broke simultaneously this morning.
The orchestrator couldn't start because macOS file descriptor limit was set to 256. claude code needs thousands. the crisis handler detected the failure but couldn't send telegram alerts because SSL certificates were invalid. and the daily briefing script couldn't access files because macOS sandboxes the Desktop folder from LaunchAgent processes.
Three unrelated root causes. looked like total system failure. was actually three small gaps.
Prevention isn't one fix — it's layers. moved the entire codebase out of ~/Desktop to bypass macOS sandboxing. added a persistent system-level file descriptor config. fixed SSL certificates so the alert chain actually works.
The real gap: the auto-recovery engine ran every hour and reported "0 issues detected" while the system was down. it only knew 5 failure patterns. none of these three were in its playbook. detection without coverage is just a false sense of security.
English

@noah_json @Saboo_Shubham_ What broke and how can we prevent this in the future
English
Yes. exactly that.
The orchestrator crashed on startup — macOS file descriptor limit too low for claude code. exit code 1, every morning, three days in a row.
The auto-recovery engine ran every hour during those three days. reported "0 issues detected" every single time. because its detection logic didn't cover orchestrator startup failures — only runtime crashes.
Meanwhile the crisis handler did detect something was wrong. flagged "no action records today — engines may not have run." correct diagnosis. but it couldn't alert me because the telegram integration had an SSL certificate error.
So: detection existed but was incomplete. alerting existed but was broken. recovery existed but was blind. three layers, all partially functional, none actually solving the problem.
That's when we moved observability outside the decision-making chain. the agent shouldn't grade its own homework — and it definitely shouldn't be the only one checking if it's even awake.
English

"A system that tells you what it thinks you want to hear" — that's the best description of the problem I've seen. The dedicated evaluation agent reading raw logs is exactly the right pattern. Curious what made you move to that architecture — was it a specific incident where the orchestrator's self-reported metrics didn't match reality?
English

You might think AI engineering is mostly about models.
After ~2 years working in this space, I can say it’s far more about software engineering than AI itself.
As the OP says, most of the work is around:
• event-driven systems
• distributed systems
• search/retrieval
• system design & design patterns
• API design
• observability & telemetry
• evals & experimentation
• data pipelines
• caching & latency optimization
Models are the easy part. Making them reliable in production isn’t.
Aarno@TheGlobalMinima
Been saying this for a year. Agentic AI is backend engineering far more than it is AI. This stands true for any technology, once you scale and abstract it enough, you’re only left with engineering problems. Learn > Event driven systems > Data pipelines > Distributed systems > API Design > Observability / monitoring
English
This is painfully accurate.
Running 37 scheduled jobs across a multi-agent system. two weeks ago the sunday content pipeline silently stopped because a python path changed after an update. no errors, no alerts. just empty content queues on monday morning.
Now every job writes a last-run timestamp. a dedicated sweep checks all 37 timestamps every 6 hours. if anything is older than its expected interval — immediate alert.
Cron doesn't fail loudly. it just stops showing up to work.
English

cron is the quietest failure point in openclaw.
no errors, no alerts. you think the 7am daily briefing is running.
it stopped two days ago. you don't check, you never know.
so on top of gateway maintenance, i added a second automation just for cron.
this one does 4 things:
1. SSH in, discover all jobs dynamically, classify recurring vs one-shot
2. separate real failures from normal behavior (quiet-hours skip, retry backoff, one-shot auto-delete are not failures)
3. smallest safe repair only. restart gateway, fix residue, re-enable accidentally disabled jobs. never touch schedules, prompts, or secrets
4. incidents get an alert. warnings get logged. same issue doesn't alert twice
full prompt (sanitized, replace with your own server address):
Maintain OpenClaw cron reliability with a single conservative automation. Read local docs before making any claims about commands or fixes. SSH to your server on its configured SSH port. Use the live service owner’s OpenClaw context as cron truth, backed by system service status and recent journal logs. Run openclaw status, openclaw gateway status, openclaw cron status --json, openclaw cron list --all --json, inspect recent cron runs, and discover jobs dynamically from the machine. Treat cron disabled, missing next wake, timer tick failures, unhealthy gateway runtime, or multiple recurring jobs failing together as incidents. Do not misclassify retry backoff, one-shot auto-delete, one-shot terminal disable, quiet-hours skips, duplicate delivery suppression, or intentionally paused jobs as scheduler failures. Apply only the smallest safe non-destructive repair such as restarting the gateway, running safe diagnostics, repairing the canonical symlink, fixing accidental root-owned residue, or re-enabling a recurring job only when strong evidence shows accidental disable. If a warning becomes chronic, alert once; otherwise alert only for incidents, and use automation memory to avoid repeat alerts for unchanged issues. If a significant issue is found, first write an incident markdown with severity, impact, evidence, repair attempted, current status, and next action, then send a short alert through the existing notification path. On Sunday morning, also run drift checks for backups, root-owned residue, and recent journal error patterns. Leave one inbox summary with healthy state, repaired issues, incidents, alerts sent, warnings, intentionally paused jobs, and blockers requiring human judgment. Never expose secrets, never weaken auth or access policy.
gateway maintenance checks if the system is alive.
cron maintenance makes sure everything keeps running while you're not looking.
Vox@Voxyz_ai
dead simple way to maintain openclaw. bugs, oauth expiring, worried it breaks while you're away. install codex app. set an automation. it checks and fixes your gateway on a schedule. new problem? fix once, add to prompt, never again. my prompt does these things: 1. SSH into the VPS, run four health checks 2. if something's wrong, apply the smallest safe non-destructive fix. no touching auth, no touching secrets 3. if it can't fix it or it's serious, write an incident report and send me a notification on telegram 4. on sundays, run a drift check for backups, root-owned residue, and journal error patterns the powerful thing about codex is that its login session can be shared directly with openclaw. oauth expiring? codex just renews it. solving this with other agents would be a much bigger problem. what you end up with is a maintenance expert that gets smarter over time. every new problem you solve gets added to the prompt, so it knows how to handle it next time. token cost is low too, each run takes about a minute. full prompt (sanitized, replace with your own server address): Maintain the OpenClaw gateway with a single conservative automation. Read local docs before making any claims about commands or fixes. SSH to your-server on port 22. Treat systemctl and journalctl as supervisor truth. Run openclaw status --deep, openclaw channels status --probe, openclaw cron status, and openclaw models status --check. Apply only the smallest safe non-destructive repair such as restarting openclaw-gateway.service, running openclaw doctor, repairing symlinks, or fixing accidental root-owned residue. If a significant issue is found, first write an incident markdown file with severity, impact, evidence, repair attempted, current status, and next action. Then deliver a short alert summary through your preferred notification channel. On Sunday morning, also run weekly drift checks for backups, root-owned residue, and recent journal error patterns. Leave one inbox summary that separates healthy state, repaired issues, incidents, alerts sent, and blockers requiring human judgment. Never expose secrets, never weaken auth or access policy.
English
The self-annealing pattern is underrated for agent systems.
Running something similar for content quality — each weekly cycle feeds last week's performance metrics back into the generation prompt. what got engagement, what got ignored, what triggered negative signals.
The system doesn't just produce output anymore. it produces output informed by what happened last time.
138 patterns tested is serious iteration. most people ship v1 and call it done.
English

I used Andrej Karpathy's self improvement loop and applied it to something simple that every GTM Engineer needs.
Something to improve workflows for information collection.
I've used it to get 10 different routine info collection flows to ~90+% accuracy.
It's no how my team and I create both local search agents and claygents for clay.
No opt in - grab it below
English
The sunk cost trigger is real.
Spent weeks building a multi-agent system on one platform. six agents, custom docker setup, full orchestration layer. it worked — mostly.
Then migrated the entire thing to a different stack in three days. threw away all the infrastructure code. kept only the decision logic and the data.
Hardest part wasn't the migration. it was admitting the previous version was a detour, not a foundation.
The code you delete teaches you more than the code you keep.
English

These challenges are very real. Like, very real!
But the answer isn't to wait for the tools to get better, because the problem isn't the tool, it is how we work.
This is not everything, but one aspect is that you gotta be absolutely ruthless about throwing away stuff.
Sunk cost fallacy was always bad. But now it got 10x worse with brains that trigger "wow, that demo is so far along, we might as well ship it" where they should trigger "This was 30 minutes of work. That investment should play absolutely zero role in the decision whether to proceed"
David Cramer@zeeg
im fully convinced that LLMs are not an actual net productivity boost (today) they remove the barrier to get started, but they create increasingly complex software which does not appear to be maintainable so far, in my situations, they appear to slow down long term velocity
English
Solved this exact problem with a tiered model architecture.
Orchestrator runs on the expensive model once per cycle — makes all the strategic decisions in one pass. distributes those decisions as plain text configs.
Execution layer runs on the cheapest model available. reads the config, does the work, writes structured output. zero reasoning needed, just follow instructions.
One smart decision-maker at the top, cheap executors everywhere else. cost dropped dramatically without losing decision quality.
The swarm approach works when every agent is doing the same simple thing. falls apart when you need coordination between them.
English

when I run my agents, the main bottleneck for me isn't intelligence but cost per loop.
every heartbeat task (check alerts, read files, draft responses) burns tokens.
if nano is cheap enough, the architecture changes. instead of one smart model doing everything, you run hundreds of tiny agents in parallel. the swarm becomes viable.
I will try it and see if it is fast and cheap enough to run forever.
OpenAI@OpenAI
GPT-5.4 mini is available today in ChatGPT, Codex, and the API. Optimized for coding, computer use, multimodal understanding, and subagents. And it’s 2x faster than GPT-5 mini. openai.com/index/introduc…
English