
Nathan Roll
208 posts
Nathan Roll
@nrol_ling
PhD student @Stanford/@stanfordnlp {AI, language, speech, brain} researcher
palo alto Katılım Temmuz 2024
264 Takip Edilen174 Takipçiler

@andrewgwils @mrtnm @dongkyucho @ShikaiQiu @rumichunara @Pavel_Izmailov An interesting way to cast the forgetting problem! Some finetuning tasks seek to 'forget' certain behaviors and not others, is this solved here by selectively sampling rollouts that should be preserved?
English

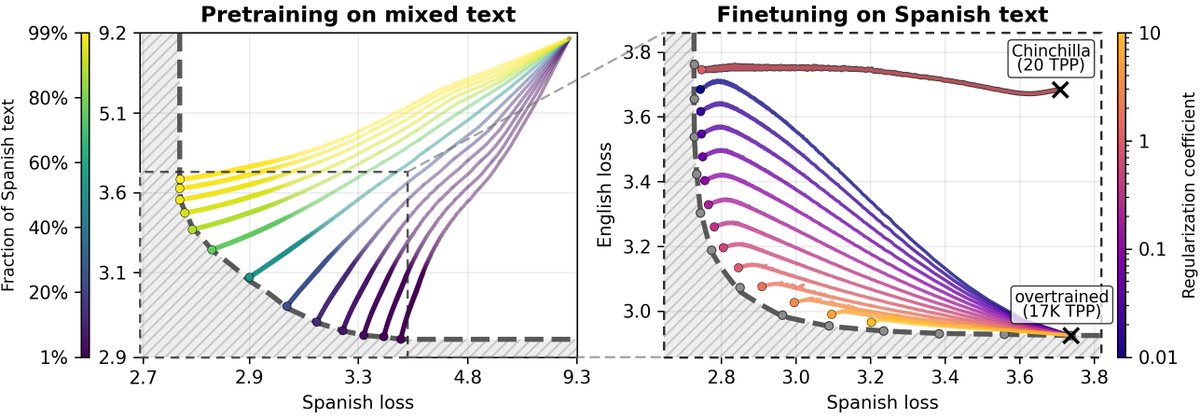
How much does a language model forget when finetuned on new tasks? We show both model size and optimization matter and forgetting can be nearly eliminated with self-generated replay!
arxiv.org/abs/2605.26097
w/@mrtnm @dongkyucho @ShikaiQiu @rumichunara @Pavel_Izmailov 1/8
English

Continual learning has started to take shape.
But it may not look like what you expect.
The usual assumption is simple:
a model updates its weights as it sees new data.
But another version is coming into view:
1. very large, long-lived context windows
2. context treated as learnable “fast weights”
3. harness optimization, where skills, prompts, tools, evals, and workflows become trainable state too
Now imagine an enterprise agent working inside one specific environment.
The base model carries the slow weights: general reasoning, coding ability, world knowledge.
The context carries the fast weights: org knowledge, project history, logs, eval results, tool traces, learned skills, and task-specific strategies.
Then the agent loop improves that state while the work is happening.
Not after the task.
During the task.
That means a days-long agent run could improve its own context, skills, and workflow as it goes.
Eventually, maybe years-long ones.
Because the improvement step is part of the agentic loop, since it's optimizing the harness and context.
At that point, we will have real autonomous agents.
They may learn by optimizing the world around the model.
My bet: we see a continual learning system like this before the end of 2026.

English
Nathan Roll retweetledi

For the last NLP seminar of the quarter, we are excited to host @GretaTuckute from Harvard University!
Date and Time: Thursday, May 28, 11:00AM — 12:00 PM Pacific Time.
Zoom Link: stanford.zoom.us/j/93941842999?…
Title: Learning and Representing Language in Brains and LLMs
Abstract: For the first time in history, we have a system other than the human brain that can generate fluent language: large language models (LLMs). Do the human brain and LLMs converge on shared representations and computations, and if so, what can LLMs tell us about the nature of human linguistic representations? In this talk, I will first characterize the human language network, a set of frontal and temporal brain regions that causally support language processing. I will then show that the alignment between the human language network and LLMs is strong enough that LLMs can non-invasively modulate language responses in the human brain. Moreover, this alignment can be attributed to small sets of interpretable LLM-based features, providing insight into the main axes of brain activity when humans comprehend sentences. Finally, I will turn to the question of how such linguistic representations can emerge from the messy acoustic signals that humans actually receive. I will introduce AuriStream, a self-supervised textless NLP model that learns from continuous speech and shows that linguistic structure can emerge without prespecified text tokens, given the right temporal predictive learning objective. Together, these results position LLMs as tools for characterizing the representational principles in the human language network—and AuriStream as a step toward understanding which inductive biases can give rise to human-like language representations from raw speech.
Hope to see you all there!

English
@SAIRfoundation Is verifying a proposed proof harder than generating it? I wonder what capability transfer there might be here.
English

Terence Tao: AI is creating a “traffic jam” in math
If AI generates more proofs than humans can verify, science needs new infrastructure. SAIR competitions build that infrastructure by surfacing high-quality results, so the best work is not lost in a flood of AI-generated math.
English
@drmtown To refine this, I think human writing lies at distinct points on the perplexity/density pareto frontier, which is guided by genre and context. "personality" costs tokens, but so does humor and joy.
English

My working theory is that human writing has more information density, more perplexity, and more emotional range than AI writing, and people who are used to reading both recognize that intuitively, which leads to being turned off by the latter.
Megan Stevenson@MeganTStevenson
Why is it so repulsive/cringe when someone uses obvious AI writing? I feel this, but can't decide if it's a feeling I want to defend. 1/
English

Computer use is getting insane!
Geoff got himself a nice comfy white collar office job with a dell pro max workstation wtf

English


Cool paper by AllenAI and CMU on how to pretrain LLMs for long-context understanding
The setup is legit and the findings are interesting, and they show that most LLMs have architectural issues 🧵

English


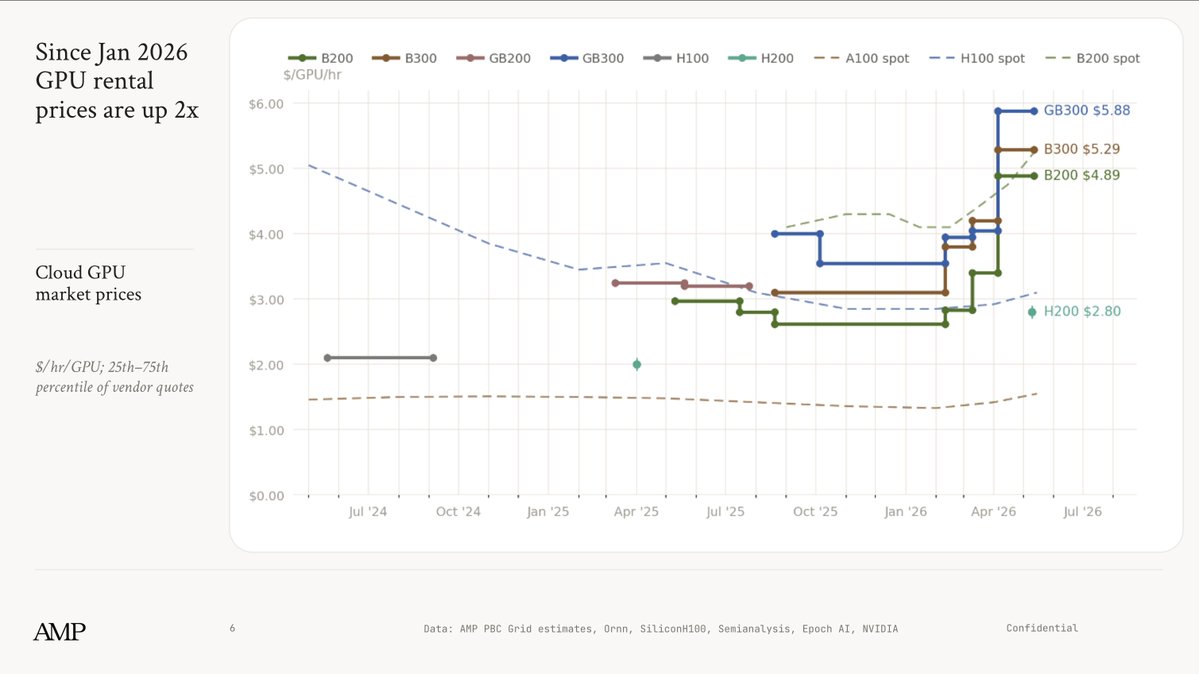
apparently not everyone is aware of this, so sharing it here
since jan 2026, GPU rental prices are up 2x+
we are living through the covid of compute, and all the toilet paper is gone
stay safe out there researchers
English
@percyliang Sick! Could the slight deviations from expectation be explained by changes to the data mix?
English

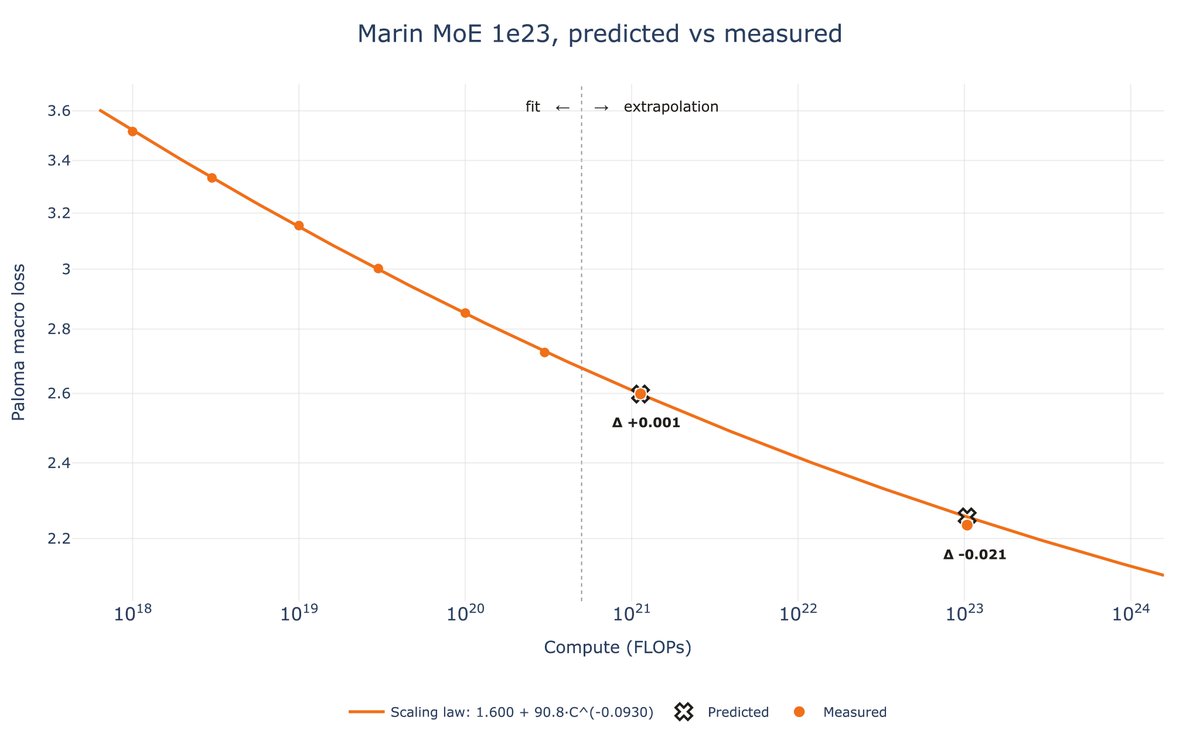
Not only do we want to train a good model, we want to know it'll be good before we even start training.
About a month ago, the Marin team launched a 129B (16B active) 1e23 FLOPs MoE run and preregistered a loss of 2.252. The run finished this past week and landed at 2.234.
x.com/percyliang/sta…
English
Nathan Roll retweetledi

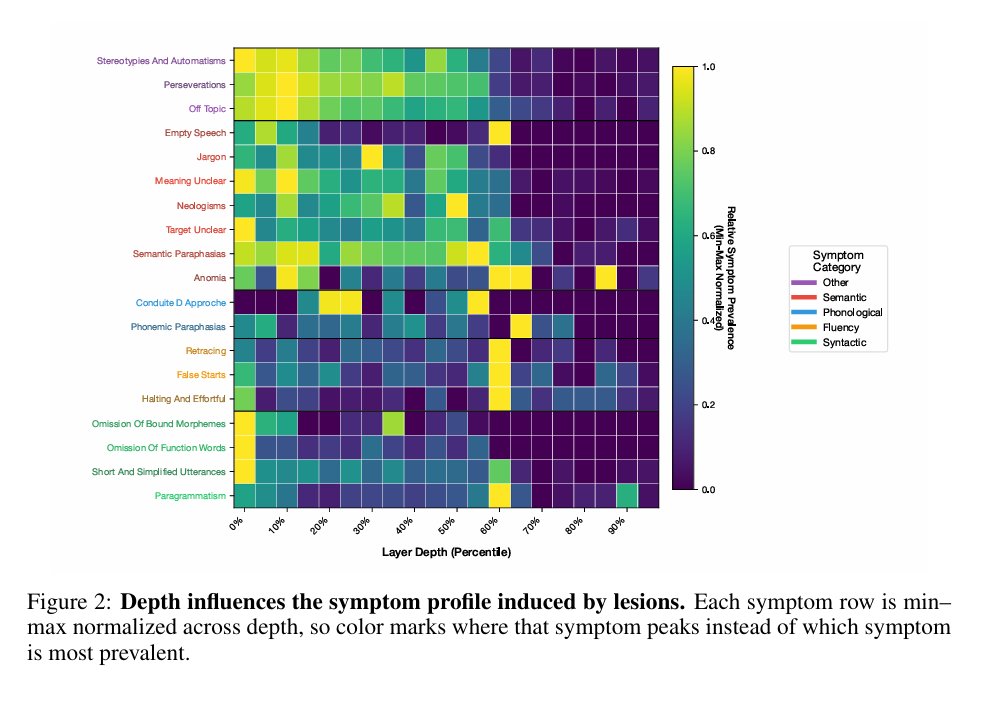
Human aphasia taught us neurological localization through selective loss.
AI aphasias may reveal the structure of AI language and point to a discrete cognitive domain that can be defined through its points of failure
A.Benítez-Burraco@abenitezburraco
Artificial aphasias in lesioned Language Models arxiv.org/abs/2605.16222 👆some LM lesions induce quantitatively similar profiles to some human aphasia types 👆qualitative differences suggest that aphasia syndromes are not mereley a consequence of disrupted language processing
English
@deliprao @abenitezburraco @hamandcheese Yes, in fact the only real similarities to humans were the symptoms themselves! The distributions are quite different, which could help us understand what’s fundamental about language as a task vs. the exact implementation in humans vs LMs.
English

@abenitezburraco @hamandcheese Super cool. Did you find aphasia categories in LLMs that are not observed in humans?
English
Nathan Roll retweetledi

Artificial aphasias in lesioned Language Models
arxiv.org/abs/2605.16222
👆some LM lesions induce quantitatively similar profiles to some human aphasia types
👆qualitative differences suggest that aphasia syndromes are not mereley a consequence of disrupted language processing
English
@micahgallen Fascinating! We’ve had a bit of this story temporally (look at e.g. ERP delays in children vs adults), so it’s cool to see “reorganization” spatially as well.
English

A new atlas reveals that functional connectivity patterns in the human neocortex shift dramatically from birth through old age, organizing brain regions along three dominant axes: sensory-to-association, visual-to-somatosensory, and modulation-to-representation.
nature.com/articles/s4158…
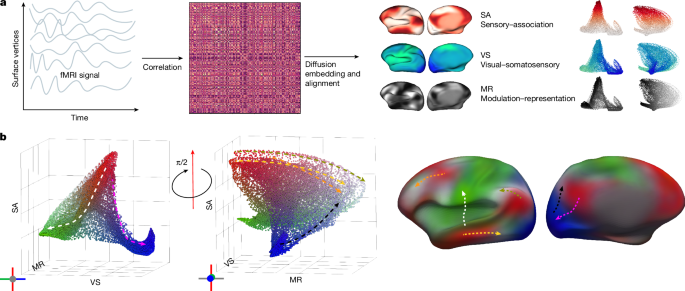
English
Nathan Roll retweetledi

This was a really fun project -- I think we're getting a much better handle handle on the neural dynamics of vision. (and still a ways to go!). I've heard from folks that the 30ms recurrent circuit we seem to be finding has been found in a bunch of other places as well...
Josh Wilson@Norcal_Neuro
1/ New preprint with @dyamins + team! Ventral visual representations within areas evolve over the course of the response along the same hierarchical complexity axis that distinguishes the visual areas, potentially driven by local recurrence. biorxiv.org/content/10.648…
English
@Sentdex @TheAhmadOsman There are two ways to get SOTA in this world...
English
@TheAhmadOsman you're even allowed to cherry pick which models you compare to!
English
For anyone who isn't sure, this is how you release a model and talk about the performance. Not 3-5 cherry-picked benchmarks.
Qwen@Alibaba_Qwen
Performance:Qwen3.7-Max performs strongly across benchmarks in coding agents , and improves massively in general-purpose agents. Qwen3.7-Max also demonstrates exceptional strength on the hardest reasoning benchmarks, and stands out in general capabilities and multilingualism.
English
@ChengLuo_lc Few do! I was just curious if you had a sense of scaling from smaller-param experiments.
English

@nrol_ling thanks for the attention, we currently not have the plan or resources to scale up to 1T but we are interested in how this works out for large scale
English
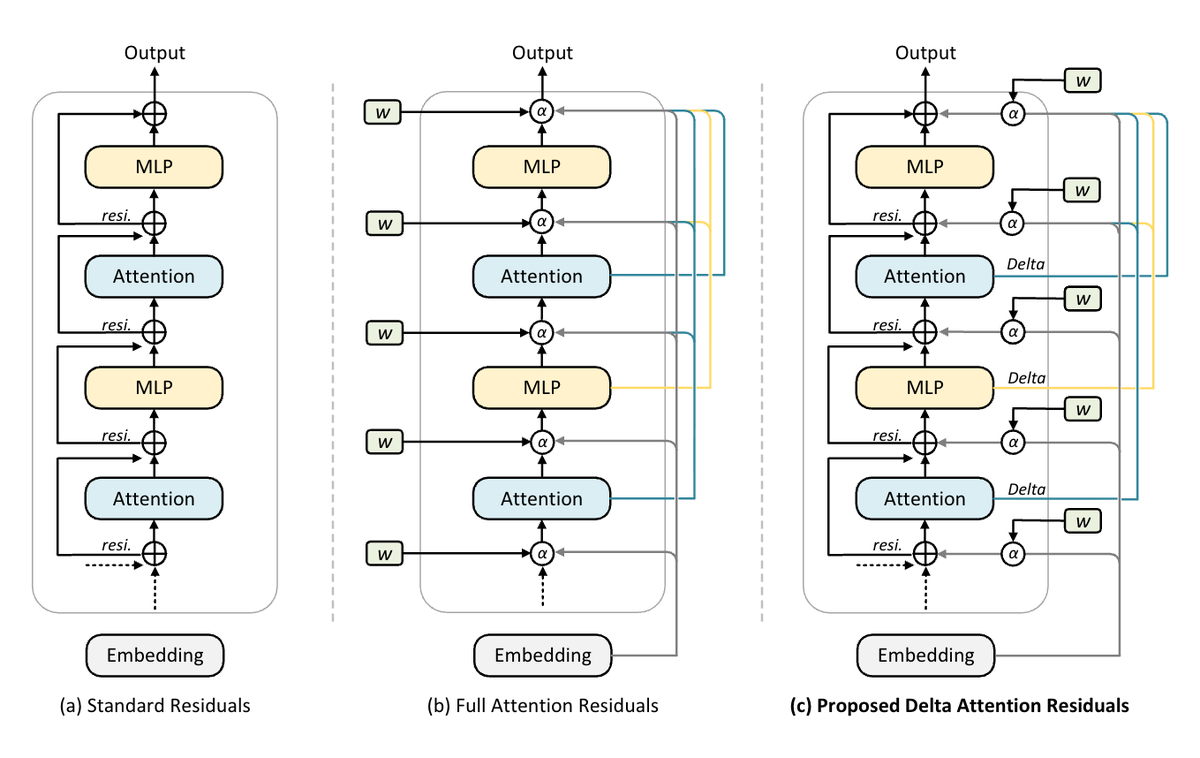
We're excited to release 𝐃𝐞𝐥𝐭𝐚 𝐀𝐭𝐭𝐞𝐧𝐭𝐢𝐨𝐧 𝐑𝐞𝐬𝐢𝐝𝐮𝐚𝐥𝐬, a drop-in upgrade to residual connections that
learns which past layers to route from — without the routing collapse that breaks prior cross-layer
attention at scale. 🚀
Attention Residuals route over cumulative hidden states, but those are highly redundant, so routing
collapses to near-uniform (max weight ~0.2) in deep layers. Delta Attention Residuals route over
𝐝𝐞𝐥𝐭𝐚𝐬 (vᵢ = hᵢ₊₁ − hᵢ) — what each sublayer actually contributed — and natively enable:
⚡ 𝟏.𝟖× 𝐬𝐡𝐚𝐫𝐩𝐞𝐫 𝐜𝐫𝐨𝐬𝐬-𝐥𝐚𝐲𝐞𝐫 𝐫𝐨𝐮𝐭𝐢𝐧𝐠
Deltas are structurally diverse, lifting max attention weight from ~0.2 → ~0.6 (0.62 vs 0.35 avg)
and curing routing collapse in deep layers.
📉 −𝟖.𝟐% 𝐯𝐚𝐥𝐢𝐝𝐚𝐭𝐢𝐨𝐧 𝐏𝐏𝐋 𝐚𝐭 𝟕.𝟔𝐁
Consistent gains from 220M → 7.6B (1.7–8.2% lower PPL), beating both standard residuals and
Attention Residuals — the latter actually degrades below baseline at scale (18.58 vs 17.43).
🔌 𝐃𝐫𝐨𝐩-𝐢𝐧 𝐟𝐢𝐧𝐞-𝐭𝐮𝐧𝐢𝐧𝐠 𝐨𝐟 𝐩𝐫𝐞𝐭𝐫𝐚𝐢𝐧𝐞𝐝 𝐦𝐨𝐝𝐞𝐥𝐬
Additive, zero-init routing is identity at initialization, so you can convert pretrained
checkpoints (e.g. Qwen3-0.6B) into Delta Attention Residuals via standard fine-tuning — beating the
original on 8 downstream benchmarks (55.6 vs 55.0).
🪶 ≤𝟎.𝟎𝟏% 𝐩𝐚𝐫𝐚𝐦𝐞𝐭𝐞𝐫 𝐨𝐯𝐞𝐫𝐡𝐞𝐚𝐝
Delta Block adds just 589K params (0.008% at 8B) and ~3% memory — and runs faster + lighter than
Attention Residuals (14.0k vs 12.5k tok/s, 42.7 vs 44.0 GB).
💻 Code: github.com/wdlctc/delta-a…
📄 Paper: arxiv.org/abs/2605.18855
English

This is like the avengers but for human AI interaction
Diyi Yang@Diyi_Yang
The next frontier of AI is not only more capable model; it is an AI that *humans* can meaningfully live and work with :) With all students in my cs329x Human-Centered LLM class, we present 60+ pages of insights for developing Human-Centered LLMs (HCLLMs), from design & data sourcing to training, eval & deployment 🧵
English