Sabitlenmiş Tweet

NobodyExistsOnTheInternet
542 posts
@nullvaluetensor
Human Large Language model. Skills: Distill data. Training LLMs. Test and Evaluate. Rinse and repeat as required. Based in SEA.

@AnalysisOp Yes, this is happening in REAL HBM roadmap, industry is actually aggresively pulling in the roadmap, shortening the time period between each generations.

dear codex, i have a distributed training script but i only have one gpu, replace all the collectives with local operations that make enough sense that i don't get a NaN loss, make no mistakes



Our security bug bounty program is now public on HackerOne. We've run the program privately within the security research community, and their findings have strengthened our products. Now anyone can report vulnerabilities and get rewarded. Read more: hackerone.com/anthropic


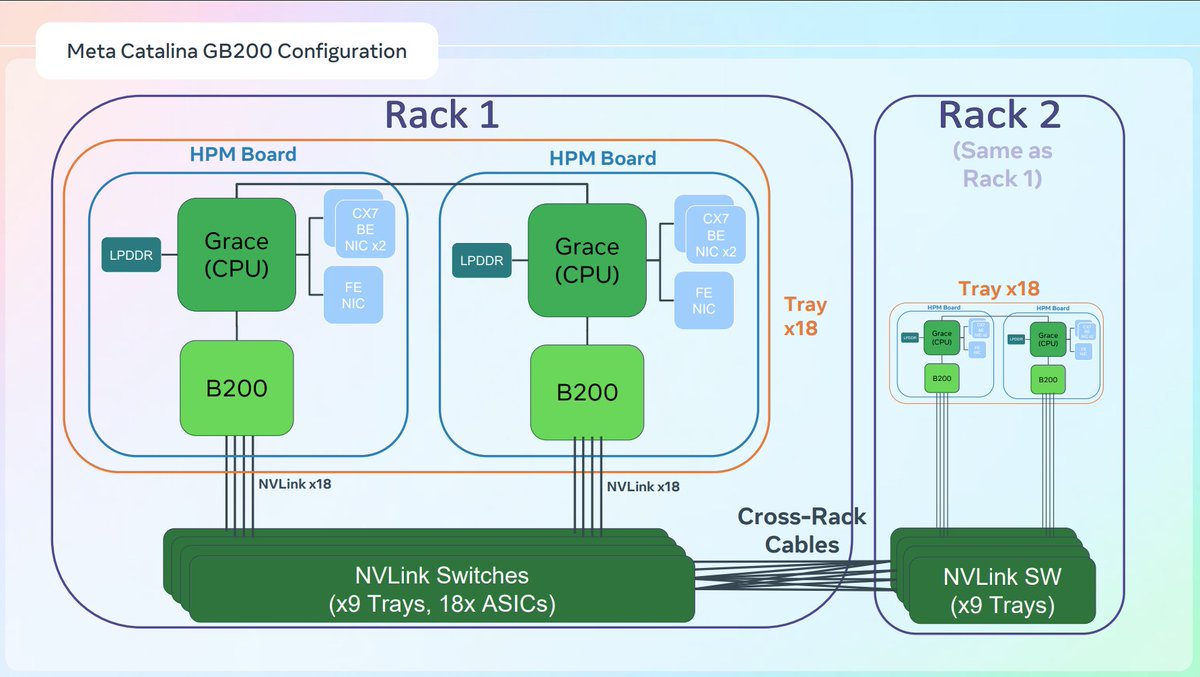
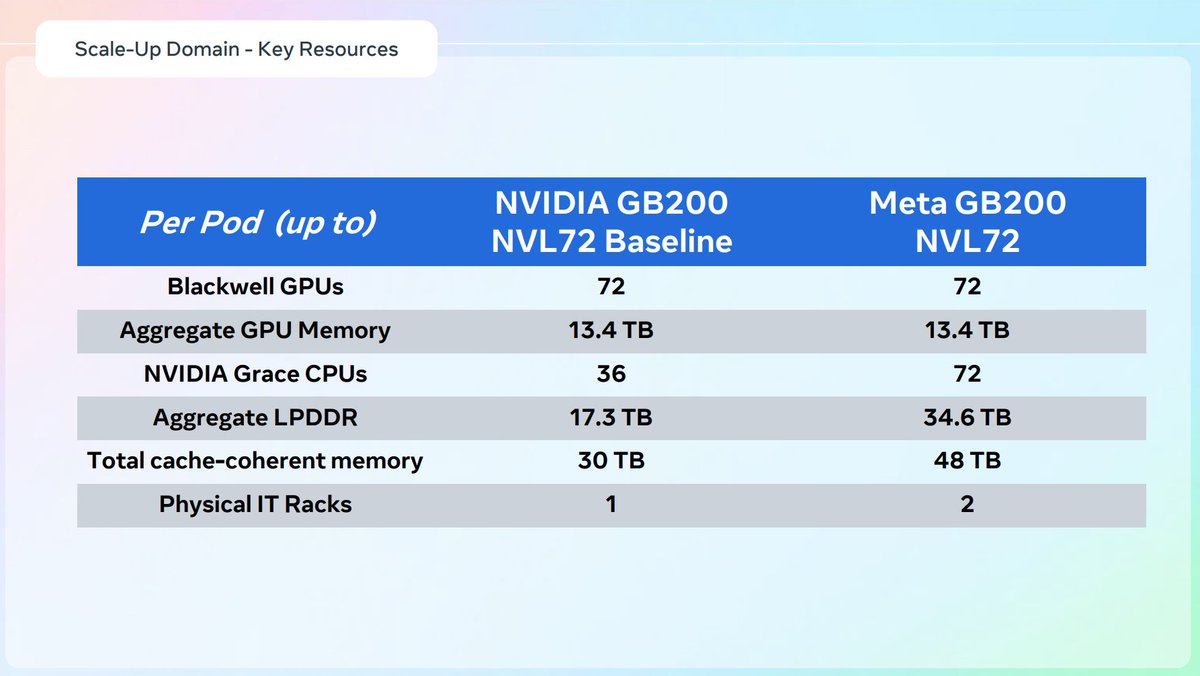
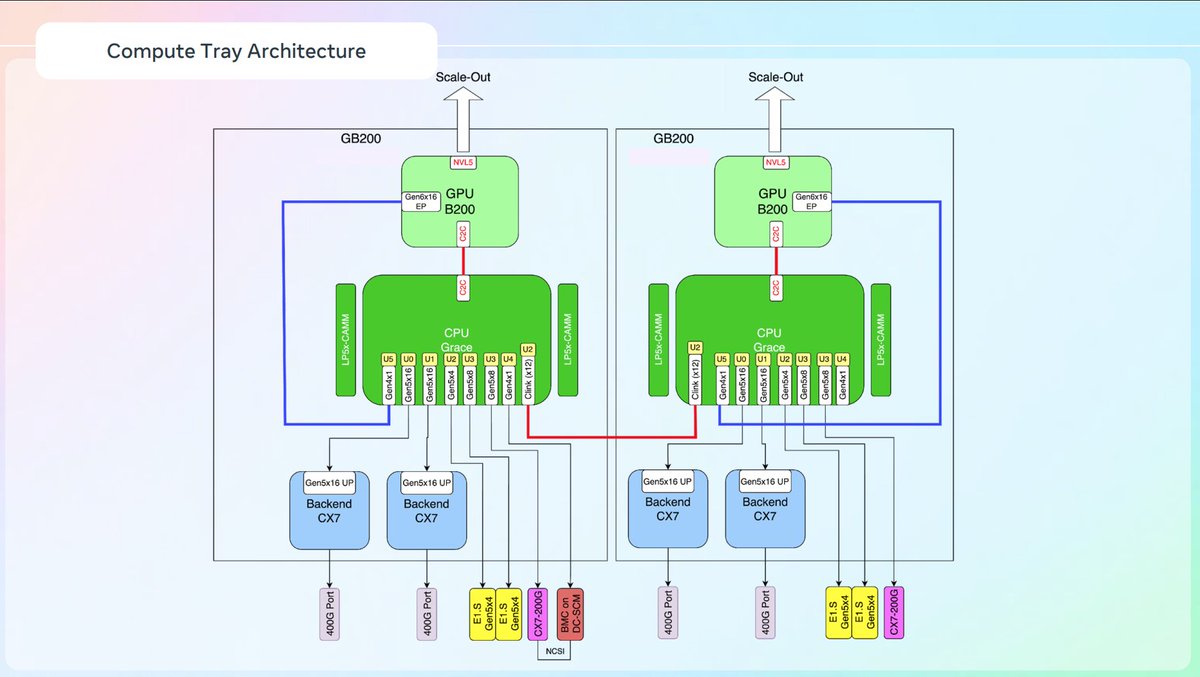
This CPU:GPU ratio going from 4:1 to 1:1 is literally a made up narrative.


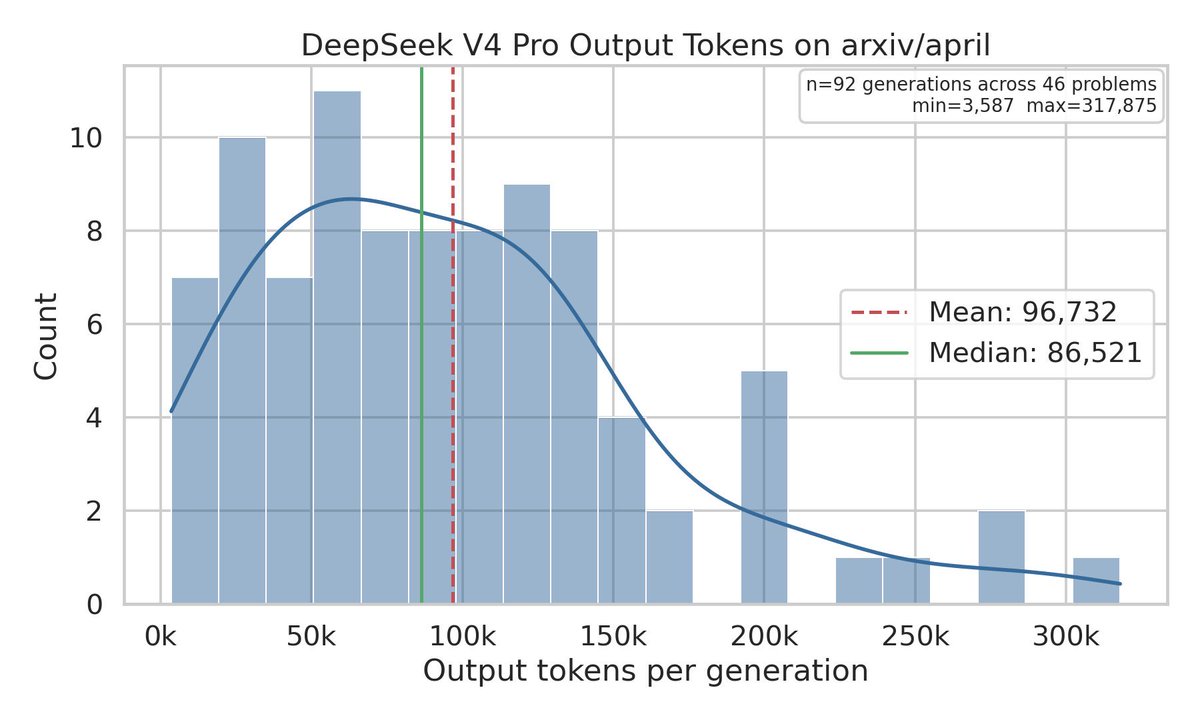
Another eval where V4-Pro and V4-Flash are basically identical (while GLM 5.1=58.1, MiMo 2.5 Pro=66.4, GPT 5.5=77.8). DS's paper says "…V4-Flash-Max matches the performance of V4-Pro-Max [on several benchmarks]". And except for knowledge, base models are already ≈matched.

Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.

something I just noticed is gpt-5.5-instant has a older cutoff than 5.5-thinking and it really confuses me why in the world this would be the case @OpenAI @aidan_mclau @tszzl this means the 5.5 generation doesnt natively have that dec cutoff its just cpt with the thinking model?

Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.


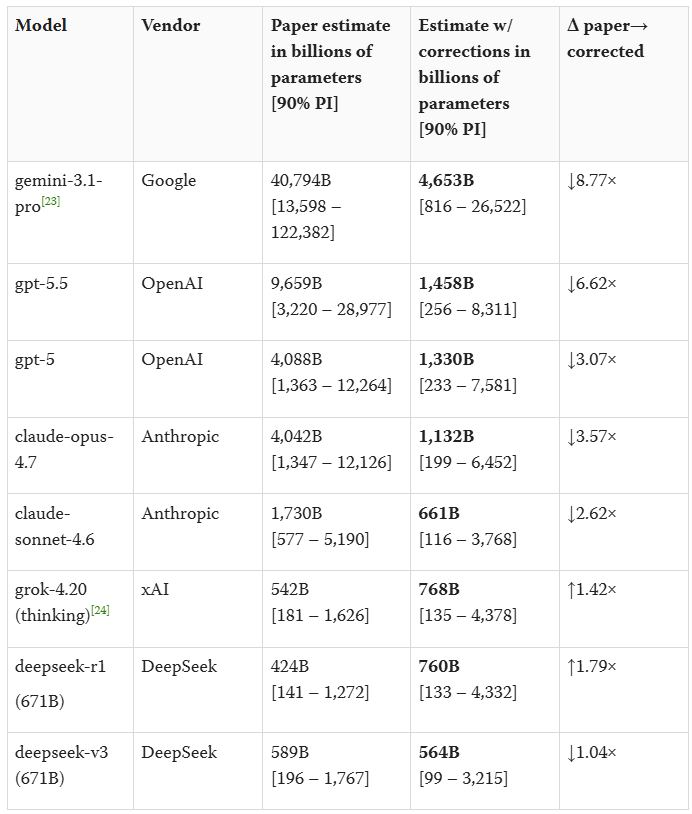
A recent viral paper claims to reverse-engineer the parameter counts of frontier models: GPT-5.5 = 9.7T, Opus 4.7 = 4.0T, o1 = 3.5T, etc. @ben_sturgeon and I investigated and found serious issues in the paper; fixing them gives GPT-5.5 as ~1.5T (90% CI: 256B-8.3T).



Doing another futile attempt at the order 668 Hadamard matrix problem, might as well do something, read a new interesting paper on it yesterday

OpenAI’s GPT-5.5 is the second model to complete one of our multi-step cyber-attack simulations end-to-end 🧵




