
Olivier Delbos
519 posts
Olivier Delbos
@odelbos
Owner at PhiBOX - https://t.co/bNRjjbB7CK
Katılım Temmuz 2009
359 Takip Edilen61 Takipçiler

The Local LLM Cheat Sheet for your 32GB RAM device
I was asked to put together a practical lineup of local models that fit comfortably on a 32GB machine.
At this tier, you start getting access to real flagship-class local models, plus a growing number of custom quants. But for most people, these are the core models worth knowing first.
Flagship Models
Qwen3.5 27B / GGUF / Q6_K_M
The best overall 32GB flagship. General chat, writing, research, and agent workflows. Great if you want one model that can handle almost everything well.
Qwen3.6-35B-A3B / GGUF / UD-Q4_K_M
Best MoE flagship. Stronger for coding, reasoning, and tool use than most smaller generalists.
Gemma 4 31B / GGUF / Q6_K_M
Dense premium model. Writing, analysis, reasoning, and high-end local chat. Heavier than the MoE options, but excellent when quality matters more than speed.
Models for Fast Flagship Use
Gemma 4 26B A4B / GGUF / Q6_K_M
Great balance of speed and quality for general assistant work, coding, agent tasks, and research. This is one of the best 32GB picks if you want something that feels high-end without dragging.
DeepSeek-R1 Distill Qwen 32B / GGUF / Q4_K_M
Offline reasoning engine. Best for math, logic, deliberate analysis, and step-by-step problem solving.
Mistral Small 24B / GGUF / Q6_K_M
Tool-calling specialist. Strong for assistants, chat workflows, local business tasks, and function calling. Available for 24GB machines.
Models for Companion Use
Qwen3.5 9B / GGUF / Q6_K_M
Best sidekick. Fast drafts, search loops, cheap retries, and secondary agent work. Even on a 32GB machine, you still want a smaller model around for support tasks.
Llama 3.1 8B / GGUF / Q6_K_M
Long-context companion. RAG, doc ingestion, codebase chat, and long prompts. The output quality is not the sharpest anymore, but it is still useful when needing simple tasks fast.
From what my community tells me, the best single models are Qwen3.5 27B or Gemma 4 31B.
For two models, the strongest general pairing is Qwen3.5 27B + Qwen3.5 9B.
If you are more code-heavy, Qwen3.6-35B-A3B + Llama 3.1 8B.
Let me know what models you are running on 32GB, and which ones have actually been worth the RAM.

Graeme@gkisokay
The Local LLM cheat sheet for your 16GB RAM device I pulled together a lineup of small models that can run comfortably on a Mac Mini or personal laptop while still leaving room for context without melting your machine. Models for Daily Use Qwen3.5 9B / GGUF / Q4_K_M Daily driver. General chat, drafting, research, translation. If you're keeping only one, keep this. DeepSeek-R1 Distill Qwen 7B / GGUF / Q4_K_M Reasoning engine. Math, logic, step-by-step problems. Slower, but worth it when you need actual thinking. Models for Specialty Work Qwen2.5 Coder 7B / GGUF / Q4_K_M Code specialist. Completions, refactors, debugging, repo Q&A. Better than a generalist when the task is code. Llama 3.1 8B / GGUF / Q4_K_M Long context worker. RAG, doc chat, codebase Q and A. The output isn't top tier, but the context is strong for its size. Phi-4 Mini Reasoning / GGUF / Q4_K_M Compact thinker. Logic, structured answers, math, and short coding bursts. Smaller context is the catch. Models for Efficiency Gemma 4 E4B / GGUF / Q4_K_M Light all-rounder. Writing, chat, light agents, structured output. Phi-3.5 Mini / GGUF / Q5_K_M Pocket sidekick. Summaries, extraction, background doc chat. Easy to pair with a bigger model. Qwen3.5 2B / GGUF / Q4_K_M Useful for summaries, tagging, rewrites, and lightweight sidekick work. Micro Models Qwen3.5 0.8B / GGUF / Q5_K_M Classification, keyword routing, binary decisions, triage. Gemma 4 E2B-it / GGUF / Q4_K_M Lightweight chat, quick Q and A, summaries, tiny agents. My personal choice for a single model is Qwen3.5 9B For two models use Qwen3.5 9B + Qwen2.5 Coder 7B for code, or Qwen3.5 9B + Phi-3.5 Mini for support tasks. Let me know in the comments your experience with these models, or any I have left out.
English
Realtime Speech-to-Text using #AssemblyAI and Google translations.
It's a simple #PoC using #Svelte for recreational programming.
Code on my Github : github.com/odelbos/poc-sp…
#realtime #speech_to_text #assembly_ai #google_translator #svelte #llm #ai
English

@AkitaOnRails Que programa é esse? Estava precisando de um pro btrfs como o ncdu
Português
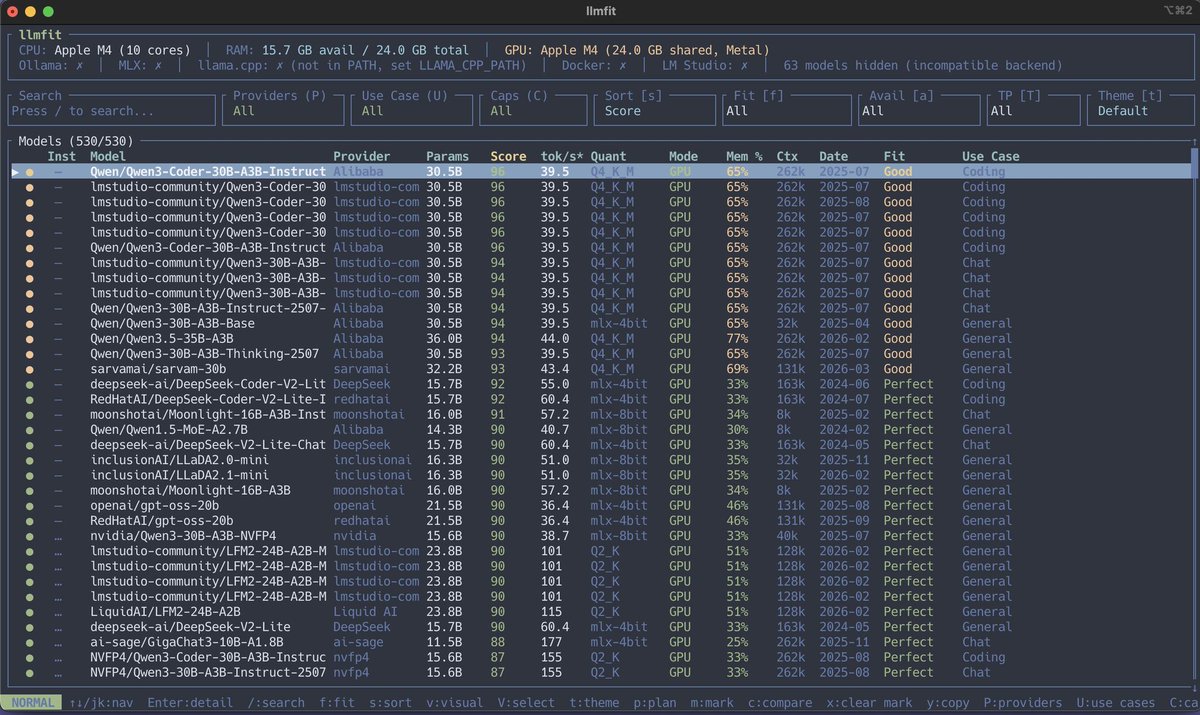
Very nice TUI tool to verify what open/(source|weights) #LLM match the best with your hardware.
Before downloading gigs of #LLM make sure it's a good fit.
-- Time saver --
Github, #llmfit : github.com/AlexsJones/llm…
Screenshot with my pro M4.
English



Who says #COBOL is only for banking?
Implementing a basic Flat #Raycasting Algorithm in #COBOL using the famous Wolfenstein 3D DDA algorithm.
(Small #Raylib #C wrapper for graphics rendering).
Source code on Github : github.com/odelbos/le-cob…

English
@ActualGeniusInt @tsoding I would love to see a stream with @tsoding exploring V lang. I like so much his way of approaching a new lang.
English

Off the top of my head, stricter types, some form of generics (so I don't have to do that horrible da_append macro), meta-programming that is not an FP type level language, defer.
(Don't suggest Zig, Rust, Odin, etc. They all come with a huge bag of opinions I don't care about)
Razor Stone@Lazi_Learner
@tsoding Are there any features you feel are missing in C ? I see a lot of places people use C style of C++ like handmade hero so I was just curious.
English
@tsoding Why not exploring Elm instead, this will show React devs that there is something better above them … :)
English
I unironically wanna do a stream at some point where I develop a webapp in PHP and jQuery like in good old days. (To piss off the React devs of course, let's not forget about that)
Josef Strzibny@strzibnyj
I still don't know how we got here as an industry.
English

Tell me you are a Linux desktop user without telling me you're a Linux desktop user.
English
IpMonitor #LearningExercise : Monitor Public IP changes. bit.ly/39OAR9H - #Elixir #ElixirLang #MyElixirStatus
Română
@kgonella @loic_emagma Par contre si mes souvenirs sont corrects, il me semble que Youx (@loic_emagma) était plus sur Java, du bon gros J2EE bien lourd, bien gras ... #:o)
Français
@kgonella @loic_emagma Pfiou, j'en ai passé des nuits pour l'écrire ce CMS ... #:o) ... Cela dit, même si XSLT ne sert vraiment pas souvent aujourd'hui cela reste un bon repère pour apprécier d'autres technologies.
"L'expérience est un lourd fardeau qui n'éclaire que celui qui le porte"
Français

WebSentinels : Periodically ping HTTP requests, verify some expectations and send #Pushover alert : bit.ly/3NJxf7K // #MyElixirStatus #LearningExercise #elixirlang
English
Having lots of fun with #elixirlang, playing with binary and pattern matching. Split binary in many encrypted blocks : bit.ly/3pQpPFG (learning exercise) #MyElixirStatus
English
Verifying myself: I am odelbos on Keybase.io. gxPOyiID_04-2mXWZPVTsTnP3acEZNJqRrr1 / keybase.io/odelbos/sigs/g…
English
@franck__delage @basecamp +1 ... If I haven't seen this tweet, I never know that this link was there.
English
If you are a PSD to HTML worker, ... think about growing tomatoes. #Algorithm will soon replace you. #AI
github.com/emilwallner/Sc…
English