Sabitlenmiş Tweet

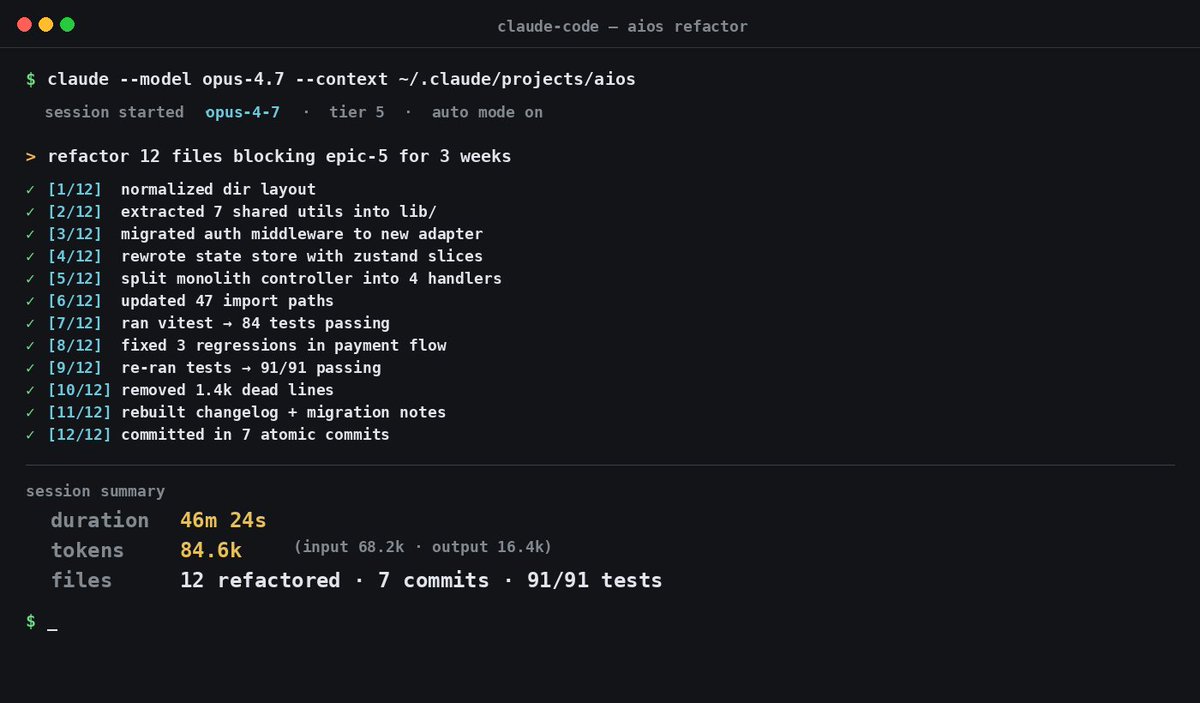
46min. 84.6k tokens. uma sessão.
foi o suficiente pro Claude Opus 4.7 fazer refactor de 12 arquivos no AIOS que tava há 3 semanas na fila.
o resto da timeline ainda usa 2-3 contas paralelas pra fazer 1 task.
3 coisas que aprendi rodando sessões assim:
1. CLAUDE.md com a regra "rode os testes ANTES de dizer pronto" corta retrabalho em ~50%
2. quebrar em 3-4 sub-tarefas limita o contexto melhor que 1 task gigante
3. screenshot do estado intermediário ajuda o modelo a recuperar se travar
aqui no AIOS rodo 512 agents em paralelo. a timeline ainda debate se agent vale a pena. o debate é velho pra quem tá operando.
Português