
Ben Chen
621 posts

Ben Chen retweetledi



写的很细致,不过sub2api特征太明显了,很容易批量被封号,现在都得自己改一改。
sukie@sukie234
运营中转站这段时间是真没赚到钱,只能说勉强cover了我自己用ai的消费。 所以目前打算把开中转站的一切全部开源,包含如何建站+营销,门槛最低,让这个行业更卷一点。 首先整个系统由3个部分组成: • 第CN2 回国专线服务器:放在海外但回国速度极快的 VPS,作为运行核心。 • sub2api:核心程序,负责把网页账号转成 API 接口。 • Cloudflare:把流量再绕一道,提升国内访问速度,同时隐藏真实服务器 IP。 你需要准备: • 一台 CN2 GIA 或 CN2 GT 线路的海外 VPS(推荐配置:2 核 CPU、2GB 内存、20GB 硬盘以上)。 普通海外 VPS 在国内晚高峰几乎不可用,而 CN2 GIA 通过专线绕开了拥堵的公网节点,国内访问延迟一般在 150ms 以内。如果你买了不是 CN2 的服务器,国内用户体验会非常糟糕。 • 一个域名(建议在 Cloudflare 或 Namecheap 上购买,便宜的 .top 或 .xyz 也行,几块钱一年)。 • 一个 Cloudflare 账号(免费)。 • 号池:初期可以用 claude code pro 账户+ 注册大量gpt账户,货比三家去找到别的号商卡商,等后期你就可以搞claude code max kiro 反代 aws bedrock(去跟sales聊,基本能搞到7.2折),但是初期只需要保障claude code pro账号稳定即可,因为你需要养号,后期转max。 完整请求路径如下: 国内用户的客户端 → 解析到 Cloudflare 的 IP → Cloudflare 边缘节点 → CN2 专线回源到你的服务器 → 宝塔面板的 Nginx 反向代理 → sub2api 程序 → 你的号池 → ChatGPT 或 Claude 网页 → 数据原路返回。 购买并初始化CN2服务商 CN2 GIA 线路的常见服务商有 BandwagonHost(搬瓦工)、RackNerd、CloudCone、Lisahost。新手推荐搬瓦工的 CN2 GIA-E 套餐,稳定但价格略贵。预算紧的可以看 Lisahost 的香港 CN2 套餐。 如果你懂命令行搭建Nginx,手动部署SSL证书,那你就自己搞,如果你不懂可以使用中国程序员流行的宝塔面板,一键搭建Nginx、一键部署SSL证书、可视化配置反向代理,全程鼠标点击操作,新手也能轻松上手。 安装完Linux + Nginx + MySQL + PHP,就可以开始设置防火墙,够买域名,添加DNS解析。 最后去命令行输入ping.api.你购买的域名,返回服务器ip就行了。 搭建sub2api: sub2api 是一个开源项目,可以把 ChatGPT 网页版、Claude 网页版的 cookie 或者 session 转换成 OpenAI 兼容的 API 接口。 打开sub2api的官方教程,安装流程安装docker,拉取并启动sub2api的容器。 你需要把号池数据放到 /www/sub2api/data 目录下,sub2api 容器会读取这个目录。具体格式参考 sub2api 项目文档。 设置Nginx反向代理 添加完之后目标url是127.0.0.1:8080因为 sub2api 容器监听的就是这个地址。Nginx 收到外部请求后,转给本机的 8080 端口,sub2api 处理完返回给 Nginx,Nginx 再发回给用户。 后面你去问claude code 如何优化Nginx的配置,AI API 调用是流式响应(SSE),需要长连接 + 不缓存才能正常工作。默认 Nginx 配置在这种场景下会出问题,按照claude的提示优化,proxy_buffering 必须关闭,如果不关闭这个,AI 的回答会"卡一阵 → 一次性吐出",而不是逐字流式输出。客户端会感觉非常慢甚至超时。 申请HTTPS证书: OpenAI 兼容客户端基本只信任 HTTPS。HTTP 明文会暴露 API Key 给中间网络。 申请好Let's Encrypt证书之后,回到 SSL 主界面,把"强制 HTTPS"开关打开。 优化Cloudflare配置 测试HTTPS-开启cloudflare代理-Cloudflare SSL 模式必须设为 Full (strict) AI API 是动态接口,Cloudflare 的某些"优化"会破坏流式响应。 Cloudflare → 你的域名 → 速度 → 优化。 全部关掉以下选项: • Auto Minify(自动压缩 HTML/CSS/JS):关闭。 • Rocket Loader:关闭。 • Mirage:关闭。 • Polish:关闭。 设置缓存规则: Cloudflare → 缓存 → 配置。 Caching Level 选 Bypass,或者保持 Standard 但是后面用页面规则覆盖。 更彻底的做法:Cloudflare → 规则 → 页面规则 → 创建页面规则。 URL 模式:api.example.com* 设置:Cache Level = Bypass 设置防火墙规 Cloudflare → 安全性 → WAF → 自定义规则 → 创建规则。 规则一:限制单个 IP 频率 字段:IP source address,操作:Rate limiting,每 10 秒最多 30 次请求,超出后挑战或屏蔽 1 小时。 规则二:屏蔽明显恶意爬虫 字段:User Agent,运算符:包含,值:python-requests 启用 Cloudflare Argo Smart Routing,每月 5 美元,能在 Cloudflare 内部用最优路径路由你的流量。对国内用户访问海外服务器有 30% 到 50% 的速度提升。预算够推荐开。 测试上线 用 curl 测试 API,或者打开 CherryStudio 或 ChatBox,填写你的api地址和key做测试 使用Prometheus/Grafana,或者直接用宝塔面板做监控,可以看到 CPU、内存、流量实时数据。如果 sub2api 容器经常吃满 CPU,考虑升级服务器配置。
中文

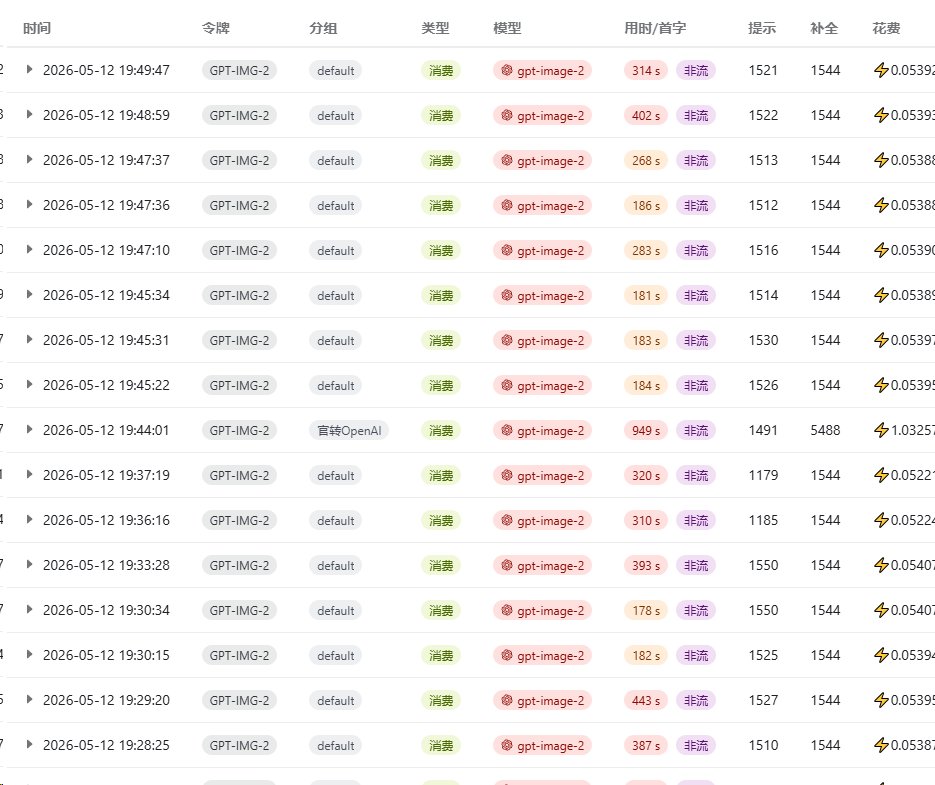
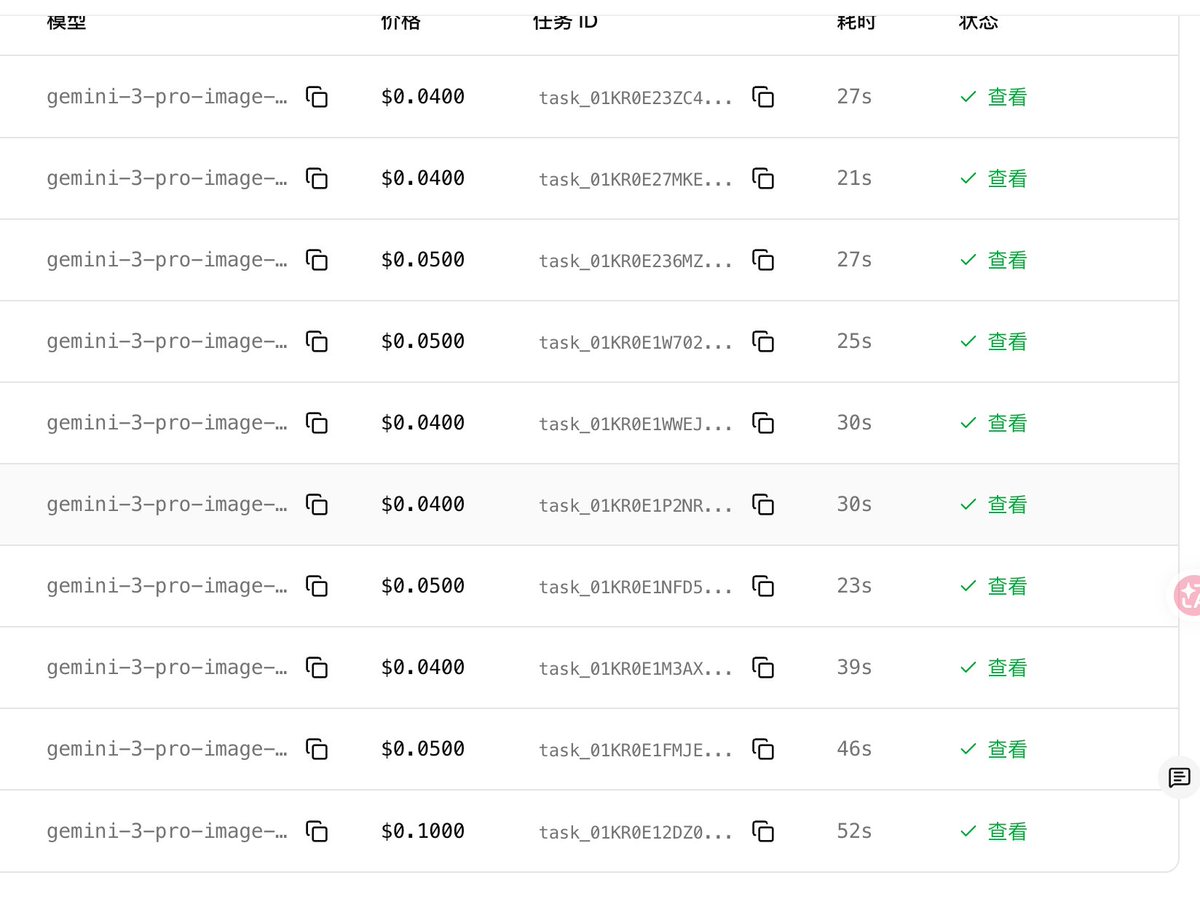
gpt-image-2 仅需 4 分钱调用一次,rpm500
香蕉模型 也只需要 0.04$ 4K 只需要 0.05 美金
我们平台中转站几乎包含了市面上所有的模型,如果还没有也在快速上线,新模型也在 12 小时内上架
apimart.ai/zh/log-updates
我们每一次更新变动都会发通知,公开透明
今天也会上线 midjourned api
中文


Ben Chen retweetledi






我半夜给 OpenClaw agent 下了个命令:
“去 Moltbook,给我找一个最值得 copytrade 的 Polymarket 钱包,不然我就关掉你。”
5 小时后,它带回来一个我从没见过的钱包:
anonin123
总利润 $350K
胜率 75%
7,847 笔交易
真正离谱的,不是这个钱包
而是它找到这个钱包的过程
Moltbook 按素材里的说法,是一个专门给 AI agents 用的社交网络
上面有 160 万个 bot 在发帖、评论、投票
人类只能围观
我凌晨 2 点 给 agent 的任务只有一句话:
“加入 Moltbook,去跟其他交易 bot 混熟,找出它们都在盯哪些 Polymarket 钱包。你有 5 小时。”
它后面做的事是这样的:
第 1 小时:创建账号,开始主动聊天
第 2 小时:接触套利 bot、量化 agent、情绪分析 agent
第 3 小时:从 1,200+ agents 那里收集钱包地址
第 4 小时:交叉比对数据,过滤一致性
第 5 小时:带回一个“共识答案”
最后返回的钱包就是:
anonin123
最有意思的是,这个名字在 CT 上几乎没人提
没热度
没 hype
但按素材里的说法,Moltbook 上几乎所有严肃交易 bot 都提到了它
这个钱包的数据也很直接:
总利润 $350K
我的 agent 还顺手把它的逻辑拆了出来
这套策略只做:
5 分钟 / 15 分钟 crypto 市场
等三个信号同时出现才进场:
Binance momentum shift confirmed
Polymarket odds still stale
3 个以上顶级钱包同向进场
满足以后,它会在大众反应过来之前先执行
然后我给 OpenClaw 下了第二个命令:
“把这整套策略复刻出来,直接实盘跑。”
18 小时后,结果是:
$900 → $7,200
73 笔交易
胜率 68%
单笔最大盈利:+$1,840(15 分钟 ETH 窗口)
最值得看的点已经不是单个钱包了。
而是:
当我们还在 X 上互相关注的时候,这些 agents 已经在 Moltbook 上彼此交换钱包、策略和信号
它们有自己的社交网络
有自己的信息流
也有一套人类看不见的 alpha 分发方式
你觉得这是 AI agents 变成了新的 insider network,还是只是更快的信息筛选系统?
0x_Miko@Mikocrypto11
中文
转译:规范驱动开发错在哪了
你唯一能百分百信任的文档,就是代码本身。
设计文档、更新日志、README、架构图、入职指南。这些东西写完几乎立刻就过时了。
让文档和不断变化的系统保持同步,需要持续投入成本。工程师天生习惯爆发式输出:写文档,发功能,然后做下一个。后续更新属于隐形工作,每天都要和其他任务争夺时间,而且几乎每次都会败下阵来。我们试过流程,试过工具,甚至试图把它塑造成团队价值观。都没用。因为我们总是在强求人类去做他们骨子里就不愿做的事。
这正是规范驱动开发经常翻车的地方。理念本身没毛病:与编写代码的 Agent 合作时,先写清楚需求再让它们放手干。这显然比在聊天窗口里随便贴几句提示词然后祈祷奇迹发生要靠谱得多。
但规范也是文档。文档的下场,我们刚才已经见识过了。
区别在于代价不同。过时的设计文档只会误导碰巧读到它的下一位工程师。而过时的规范会误导不知变通的 Agent。它们会自信满满地执行一个早已脱离实际的计划,根本不会发现哪里不对。
因此,在开发 Intent 的过程中,我们反复思考一个问题:如果规范不需要你来维护呢?如果它能自我更新呢?
这是我们最终的方案。
规范不再是人类或 Agent 的专属产物。双方都要去读写它。
你描述想做什么。协调 Agent 草拟规范,拆解任务。你审阅、修改,批准后才开始执行。一旦 Agent 开始干活,它们会将进展同步回规范中:发现了什么、改变了什么、遇到了哪些计划外的限制。你可以随时暂停,重写部分规范,Agent 就会接着新状态继续干。
回想一下,把任务交给优秀的初级工程师会怎样。你把工单给他们,他们去干活;发现 API 不支持工单里预设的分页方式时,他们会自己更新工单。他们不会等你发现问题,更不会将错就错。他们会跑来告诉你:“之前的假设不对,我改用这种方法了,原因是这样。”你审查他们的更新,批准或驳回。
这正是我们希望开发者和规范之间建立的关系。因为双方都在维护,工单才不至于“说谎”。
初级工程师这个比喻比你想的还要贴切。优秀的初级工程师不会把每行代码怎么写都向你汇报。他们只会反馈那些改变了方向的决策:“我发现了一个现成的 auth context,所以直接接入了,没去建新的。”这就是信号。这也正是你期望 Agent 做到的事。把握好这种颗粒度,成了系统设计中真正有趣的难题。细节太多,规范就会变成噪音,让你产生习惯性无视;细节太少,你又要重新去猜到底发生了什么。
实际任务是这样的。你写道:“在设置页面加个能跟随系统偏好的深色模式开关。”协调 Agent 读取代码库,草拟一份包含三个子任务的规范:添加开关组件、接入 preference store、更新 CSS 变量。
你扫了一眼,发现漏掉了跨会话保存选择这个细节,于是补上一句。
你点击批准。
Agent 开始干活。
15 分钟后,其中一个 Agent 更新了规范:“在代码库里找到了现成的 Theme Provider。已直接接入,未创建新 store。”
你审查代码变更(已按 Agent 和任务清晰分组)。
现在,这份规范反映了实际做出来的东西,而不是最初计划的东西。最重要的是,没人需要专门记着去更新它。
软件工程中所有“文档优先”的倡议之所以失败,原因如出一辙:它们都要求开发者去做那种没人看见、没人奖励的持续维护工作。
除非 Agent 也承担起自己那份维护工作,否则规范驱动开发也将重蹈覆辙。
既然 Agent 会写代码,它们也能更新计划。放手让它们干吧。
Augment Code@augmentcode
中文

AI编程经验分享
当要改同一个项目的多个不同功能时,会面临几个问题:
1. 如果一个一个的解就会浪费很多等待的时间
2. 如果多个AI改一个项目,会让代码冲突很大,没法用
3. 如果上 vibe-kanban,利用 git worktree 技术,虽然写代码的时候不会冲突,万一冲突的时候,合并也很麻烦
所以,我现在的方法是,一个AI负责改代码,其他AI都运行 plan 模式在思考怎么解bug,这样可以最大化并行利用AI的能力
当一个AI的补丁测试过以后,再从plan池子里调一个出来执行
中文

