okenai
222 posts











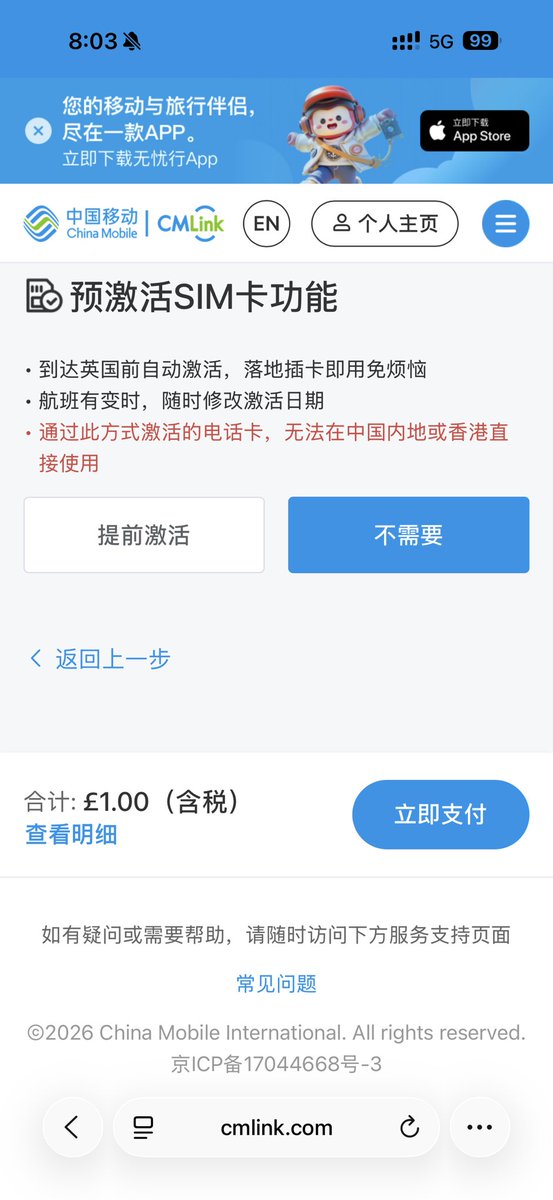
一款比giffgaff保号还便宜的的卡CTExcel 0开卡,预充1英镑(约9元),国内免费免费快递到家,支持 微信 支付宝支付。 90天发一条短信,只要0.1英镑(0.9元)保号,一年仅0.4英镑(3.6元)。 无需实名,可以转eSIM。开启WiFi Calling,发短信仅需0.08英镑。 一卡双号,跟香港月神卡有点类似。 转eSIM需要3英镑,(看个人需求) 待测试是否可以通过wifi calling激活。 如果是新卡版无法通过wifi-calling激活。 ctexcel.com/freecard/home(直达)


















FREE API access to Claude Opus 4.8, GPT 5.5 and 344 models. Plug it into OpenCode, OpenClaw, Hermes in 2 minutes. Done. > The platform is Runtime by Bad Theory Labs. Sign up with Google, fill in your details, and you land free credits to use any Anthropic or OpenAI model via API. Here's the exact flow: → Go to runtime(.)badtheorylabs(.)com → Sign up with Google → Fill in your details during onboarding → Free balance lands automatically → Grab your API key from the dashboard → Swap the base URL in OpenCode, OpenClaw, or Hermes - done The free tier includes btl-2 - a model that auto-routes between GLM, OpenAI, Anthropic, and Gemma depending on the task. 10 million tokens per month. Free. No card. Full model catalog: Claude Opus 4.8, GPT 5.5, Gemini variants, Llama 3.3 70B, DeepSeek, Kimi and 340+ others. All accessible through one OpenAI-compatible endpoint. One URL change in your existing setup. No code rebuild. Works everywhere your current stack works. // I tested it myself - fully working. Bookmark this before the free credits dry up.

the number of providers for glm 5.2 is insane. i count 20 of them.





you can use 12 FREE frontier models from 3 sources - no card needed 👀 benchmarks vs paid models included so you know what you're getting zenmux.ai (no cc): glm 5.2 → 62.1% swe-bench (beats gpt 5.5) kimi k2.7 code → #1 tiny bench, 1t params step 3.7 flash → fast agent loops mistral ai (1b tokens/mo free): mistral large 3 → 77.6% swe-bench verified codestral → beats gpt 5.5 on code gen mathstral → math/reasoning specialist nvidia build.nvidia.com (free): deepseek v4 flash → fastest reasoning, 40+ tok/s qwen 3.5 397b → 77% swe-bench, runs on consumer gpu kimi k2.6 → best for agentic/long context glm 5.1 → 58.4% swe-bench, solid coding minimax m3 → #1 b.ai leaderboard, 59% swe-bench 12 models. combined value: $200+/mo each if paid. total cost: $0. setup guides: zenmux.ai (glm 5.2 / kimi k2.7 / step 3.7 flash): > zenmux.ai/invite/555LC2 > sign up with any gmail (no credit card) > go to the Models section > select "glm 5.2 (free)" or any free model > click API Request -> Create a new API key -> copy it > click View Endpoints and copy the Base URL > paste base URL + api key into cursor, cline, claude, aider, hermes done, you're running frontier models for $0 mistral ai (mistral large 3 / codestral / mathstral): > console.mistral.ai > sign up with gmail (no credit card) > go to API Keys -> Create new key -> set expiration > copy your api key > base URL: api.mistral.ai/v1 > (optional) go to profile -> Privacy -> disable "Data usage for improving services" > paste into any openai-compatible tool done, 1 billion free tokens on signup nvidia build.nvidia.com (deepseek v4 flash / qwen 3.5 / minimax m3 / etc): > build.nvidia.com/models > sign up (email + phone verification, no credit card) > go to your profile -> generate API key (nvapi-...) > base URL: integrate.api.nvidia.com/v1 > paste into cursor, cline, aider, continue.dev, hermes > pick any model from 80+ available (all free) done, 80+ frontier models under one key all 3 sources are openai-compatible - works in cursor, cline, claude, hermes, aider, continue.dev, windsurf bookmark this before the free tiers shift




GLM-5.2 leads open weights models and sits at #3 overall on GDPval-AA, a real-world agentic work benchmark GLM-5.2 from @Zai_org scores 1524 Elo on GDPval-AA, which measures performance on real-world, economically valuable knowledge work through long-horizon, multi-turn tasks. Key takeaways: ➤ #3 overall, behind only Claude Fable 5 (1783) and Claude Opus 4.8 (1615), and level with GPT-5.5 (xhigh, 1509) ➤ The leading open weights model by a wide margin: the next open model, MiniMax-M3, scores 1408 ➤ Ahead of many proprietary models, including Google's Gemini 3.5 Flash (1357), Qwen 3.7 Max (1289), Muse Spark (1158) ➤ The tasks are agentic. GLM-5.2 averaged ~31 turns per task across 1,999 matches ➤ Consistent with the rest of its launch, GLM-5.2 also leads open weights on the Artificial Analysis Intelligence Index, ranks #3 on the Agentic Index, and #3 on AA-Briefcase