Up retweetledi

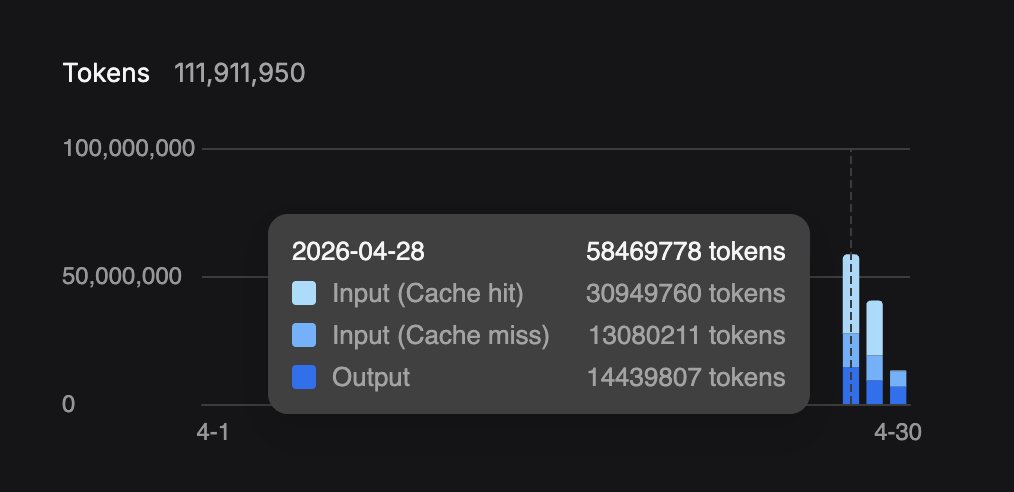
most of you don't know how big a deal it is that a single rtx 3090 from 2020 runs qwen 27b dense q4 with 256k context at 40 tok/s, full agentic loops on hermes agent, zero tool call failures.
the more i build on this card the more i think nobody really knows how untapped it actually is. the silicon was always capable, the models finally caught up.
English