
Tested #Gemini 2.0 Flash to convert recordings+audio into specs for Windsurf — mind-blowing. Now hoping for native support :)
English
Olivier Balais (overnetcity.bsky.social)
3.3K posts

@overnetcity
CTO @semji_fr, proud #casc co-founder, passionate fullstack web developer, I build cool things with #php #js #docker and an amazing team @SemjiTech !




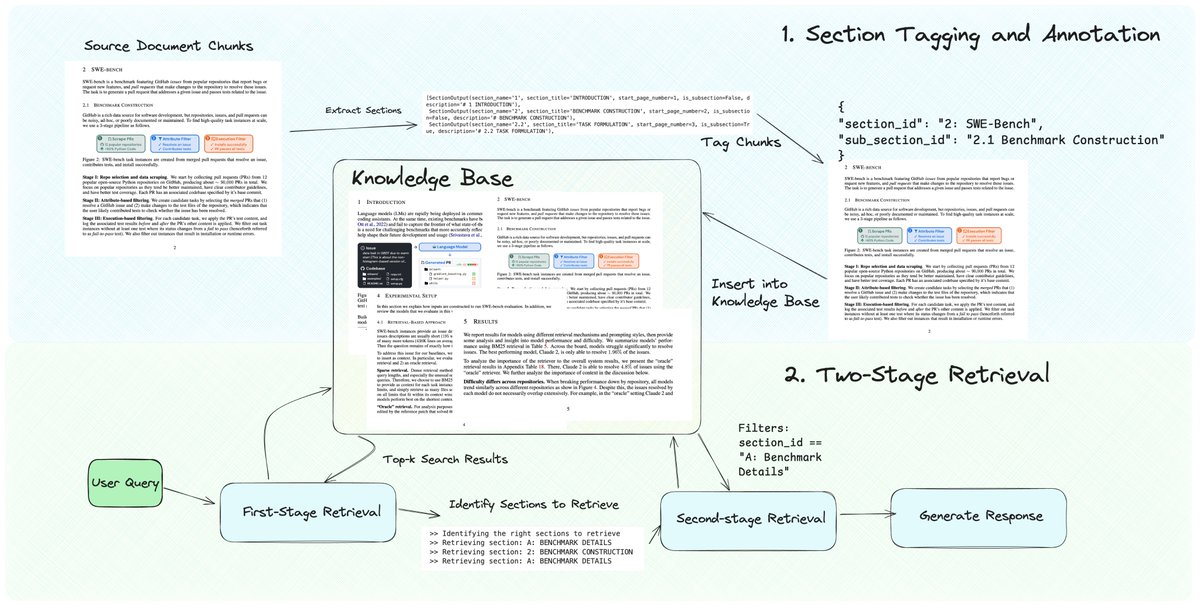
We’re excited to feature a new RAG technique - dynamic section retrieval 💫 - which ensures that you can retrieve entire contiguous sections instead of naive fragmented chunks from a document. This is a top pain point we’ve heard from our community on multi-document RAG challenges - naive RAG returns fragmented context without awareness of the surrounding document. Our approach allows you to start off with a “simple” chunking technique (e.g. per page), but do a post-processing workflow to attach section/sub-section metadata. You can then do GraphRAG-like retrieval (two-pass retrieval): retrieve chunks, look up the attached section metadata, and then do a second call to return all chunks that match the section ID. github.com/run-llama/llam…




People have been rewriting history and saying that "everyone has always believed that LLMs alone wouldn't be AGI and that extensive scaffolding around them would be necessary". No, throughout most of 2023 (the "sparks of AGI" era) the mainstream bay area belief was that LLMs were *already* AGI, and that merely scaling their parameter count and training data size by ~2 OOM without changing anything else would lead to super-intelligence.




