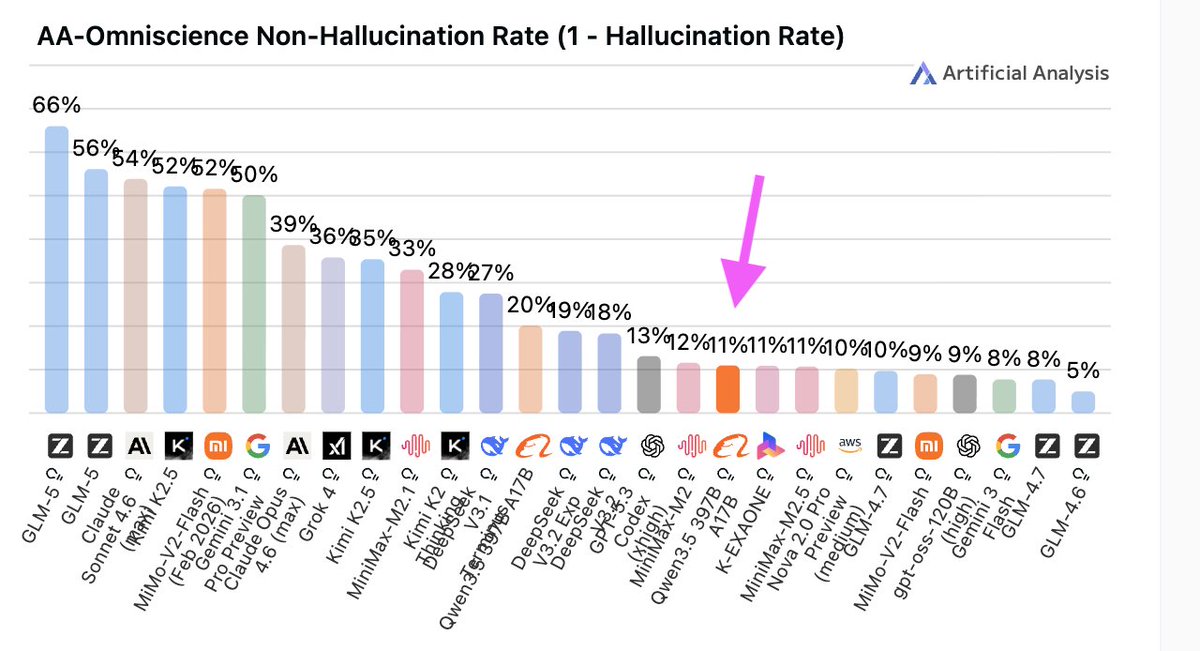
"Peaky" behaviour is exactly what the normies have a hard time grokking. They're used to intelligence correlating across domains.
Not being able to count "r"s in strawberry but being able to solve complex math problems doesn't make sense in a pre-AI world.
Working with idiot savants your whole career helps.
English