
Sabitlenmiş Tweet

after 3 months of continuous crashing, i finally got rl to land a rocket by itself! yes, the complete 6dof dynamics: translation + rotation, variable mass, tvc, disturbances, all of it done by the rl itself.
the core issue is that landing is a constrained braking problem, not open-ended control. rl fails because the feasible solution manifold is extremely narrow.
once the search space was shaped properly, rl converged. i tried various rl policies and architectures to figure all this out.
full technical analysis here check it out!: jaivalpatel.com/research-work.…
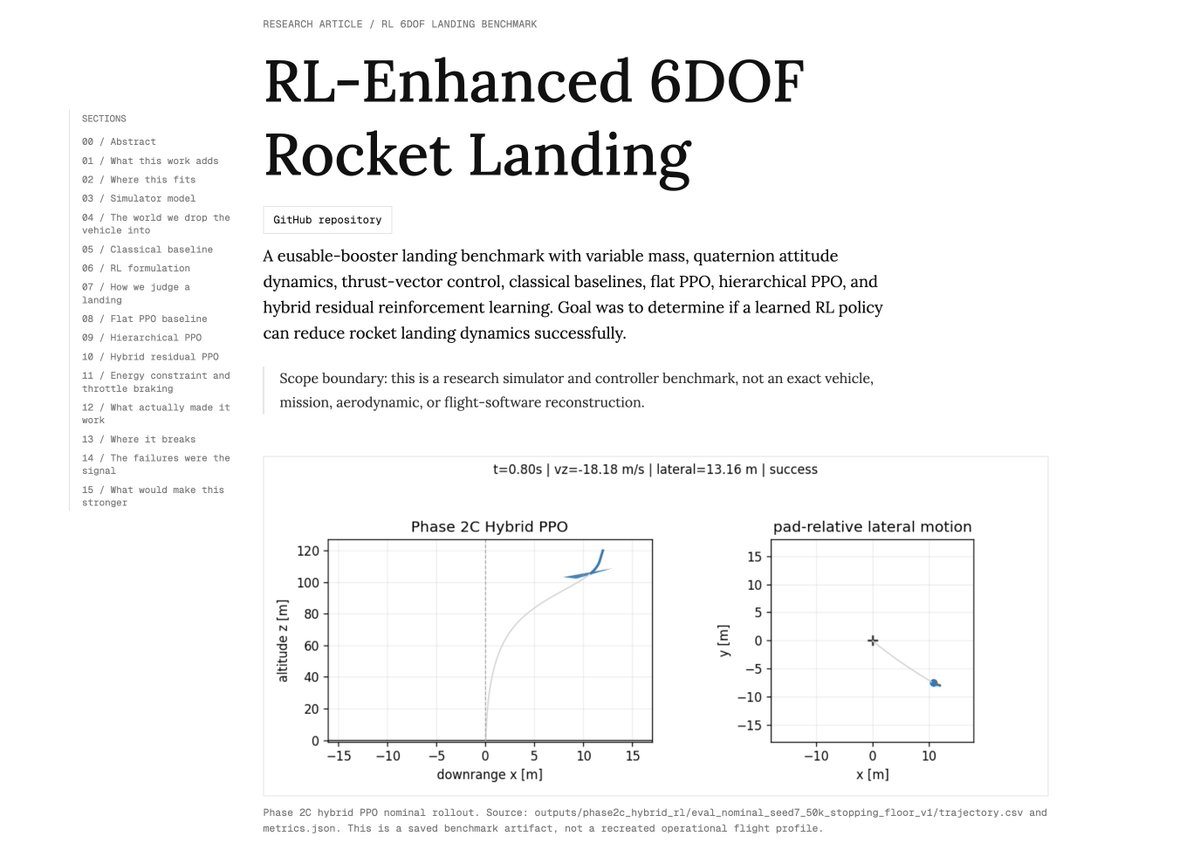
English













