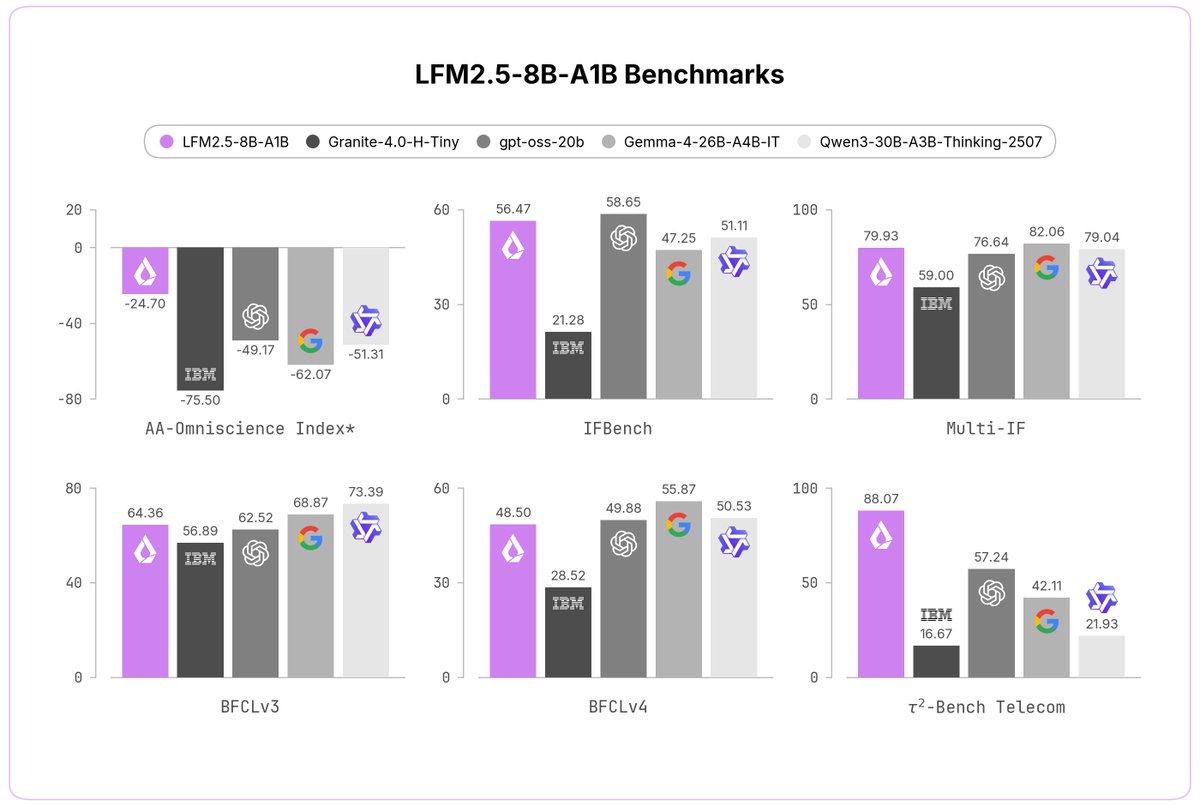
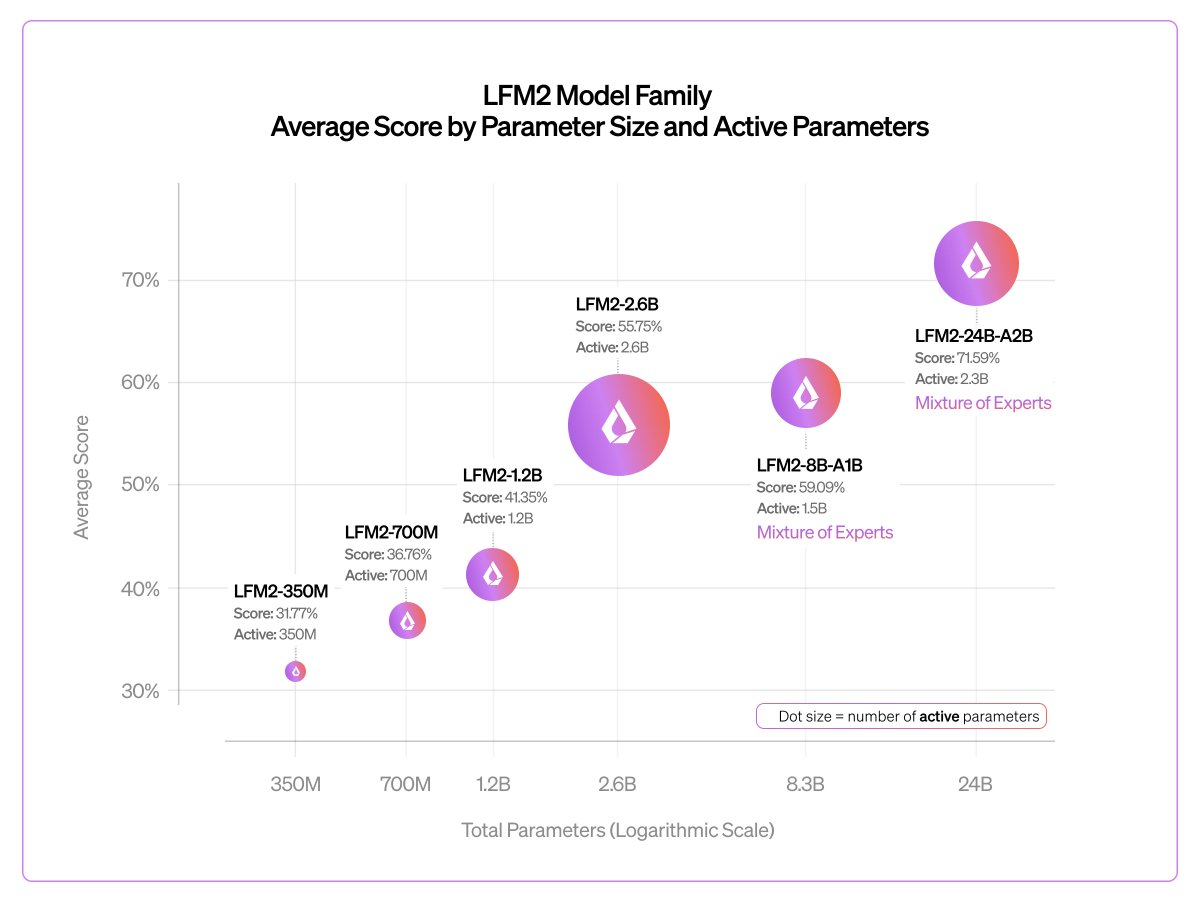
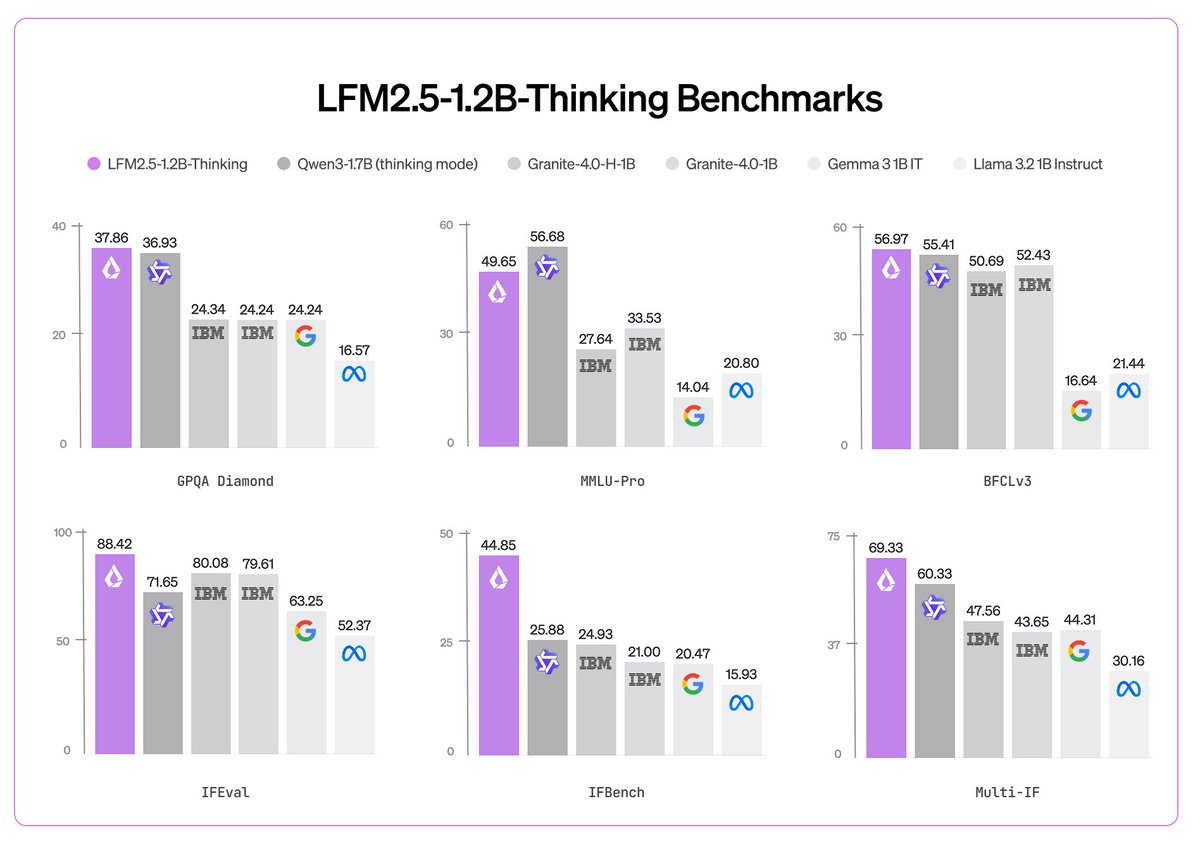
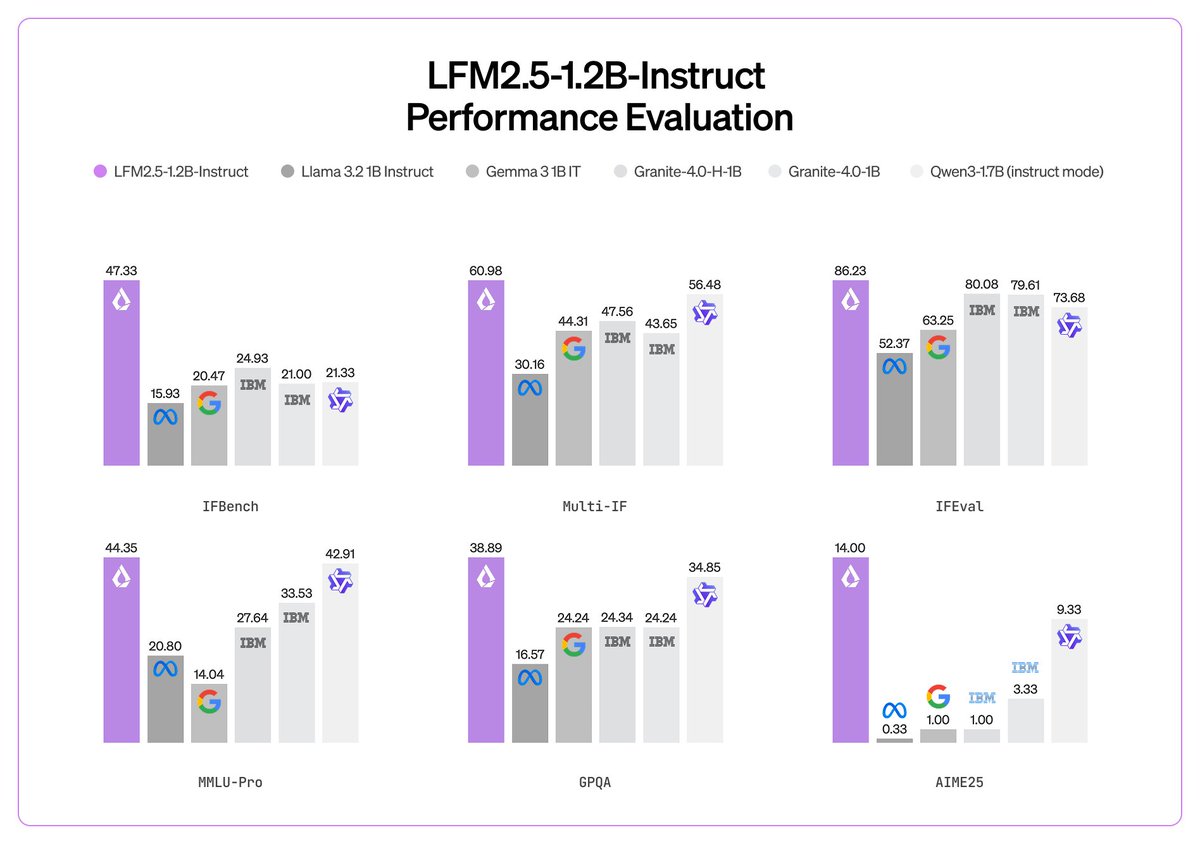
@mlech26l and I review some of the basics of ML training infra here.
These days we’ve been spending a lot of time deeper in the stack, iterating on some exciting bets in compilers, quantization, long-context optimization, communication-compute overlap, etc.
Even though @liquidai models are optimized for deployment on edge, pushing the frontier of large-scale training on GPUs is just as relevant today.
Liquid AI@liquidai
Training LFMs at scale means solving parallelism across every layer of the architecture. And not all layers are the same. Our CTO Mathias Lechner (@mlech26l) sits down with Liquid's founding engineer Paul Pak (@paulpak__) to talk training infrastructure: Data, tensor, pipeline, expert, and context parallelism, and how they make context parallelism work across hybrid architectures with both attention and convolution operators.
English