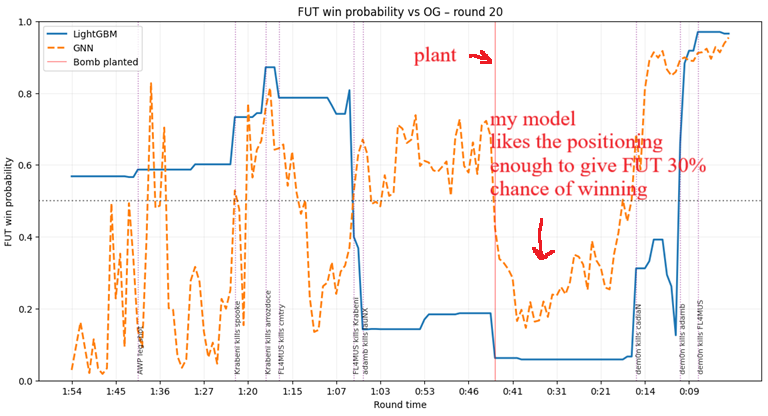
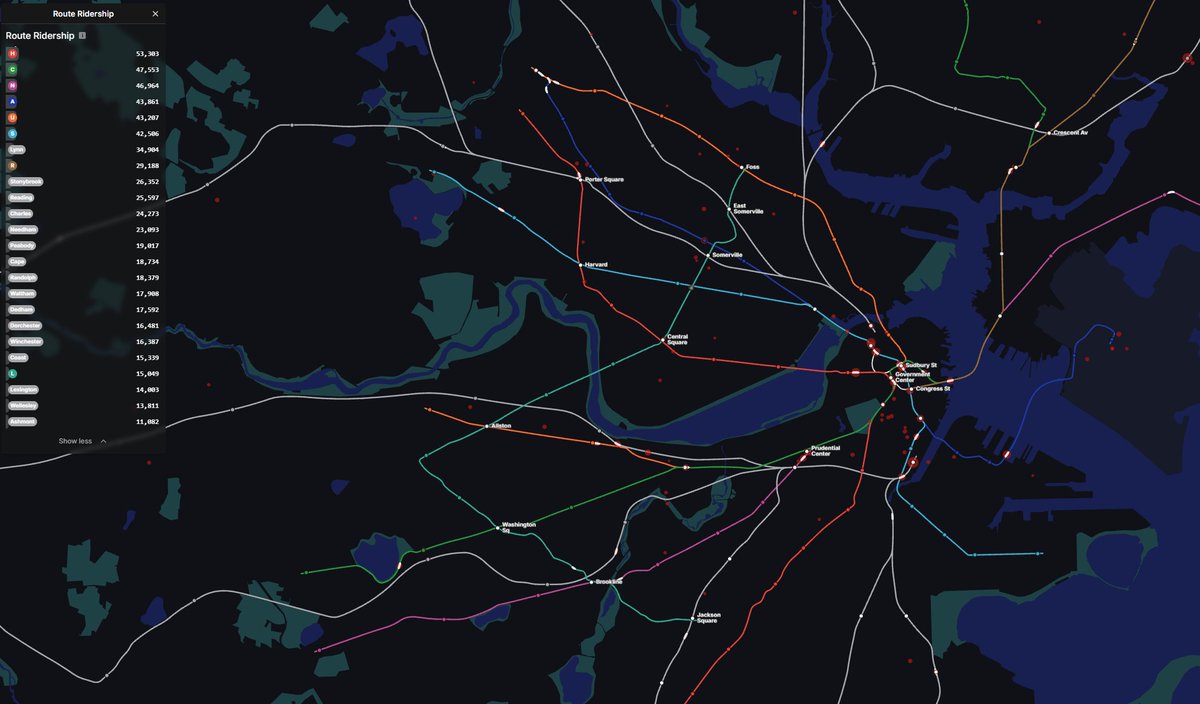
Sabitlenmiş Tweet

I love Deadlock.
So, I built an open-source Deadlock demo parser called Boon 🎯
It reads .dem replay files and gives you structured data — tick-level player/trooper/objective state, kills, damage, and more.
Rust core, Python bindings, CLI included.
github.com/pnxenopoulos/b…

English