Piji Li retweetledi

The Top AI Papers of the Week (April 6 - 12)
- Memento
- Neural Computers
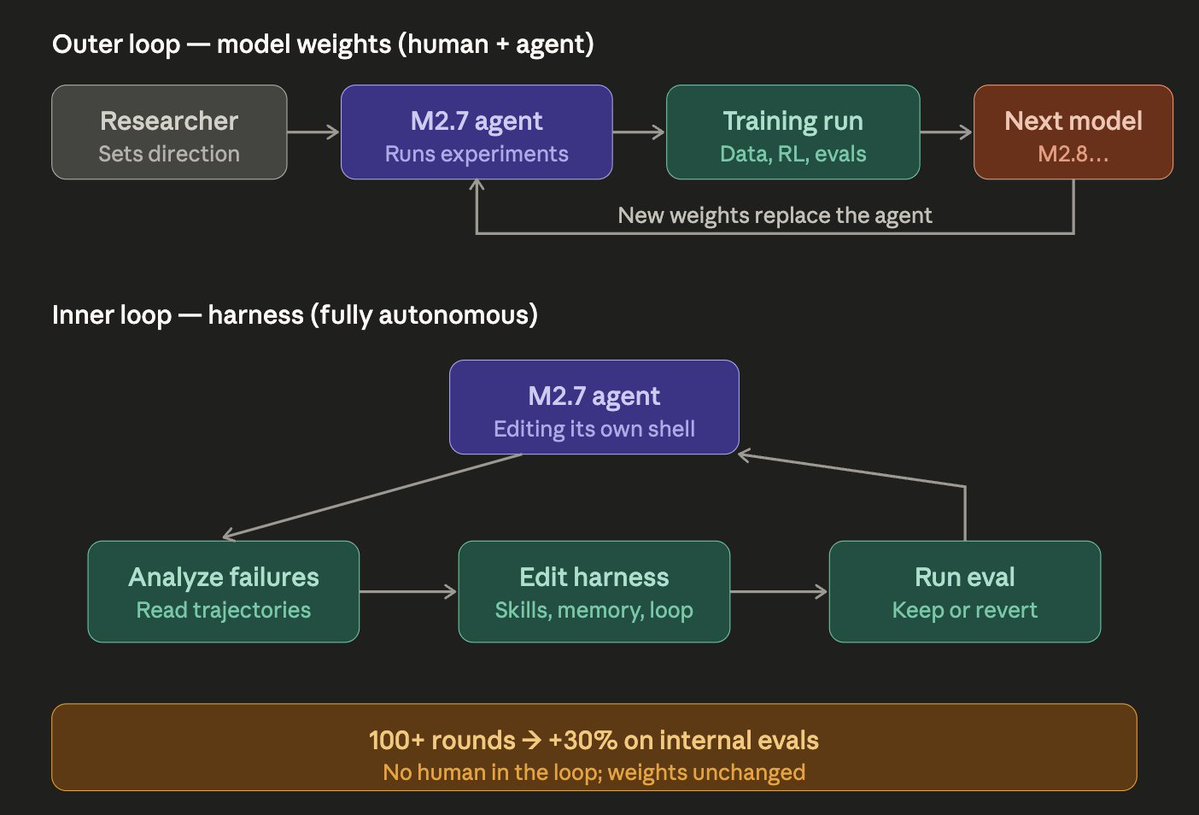
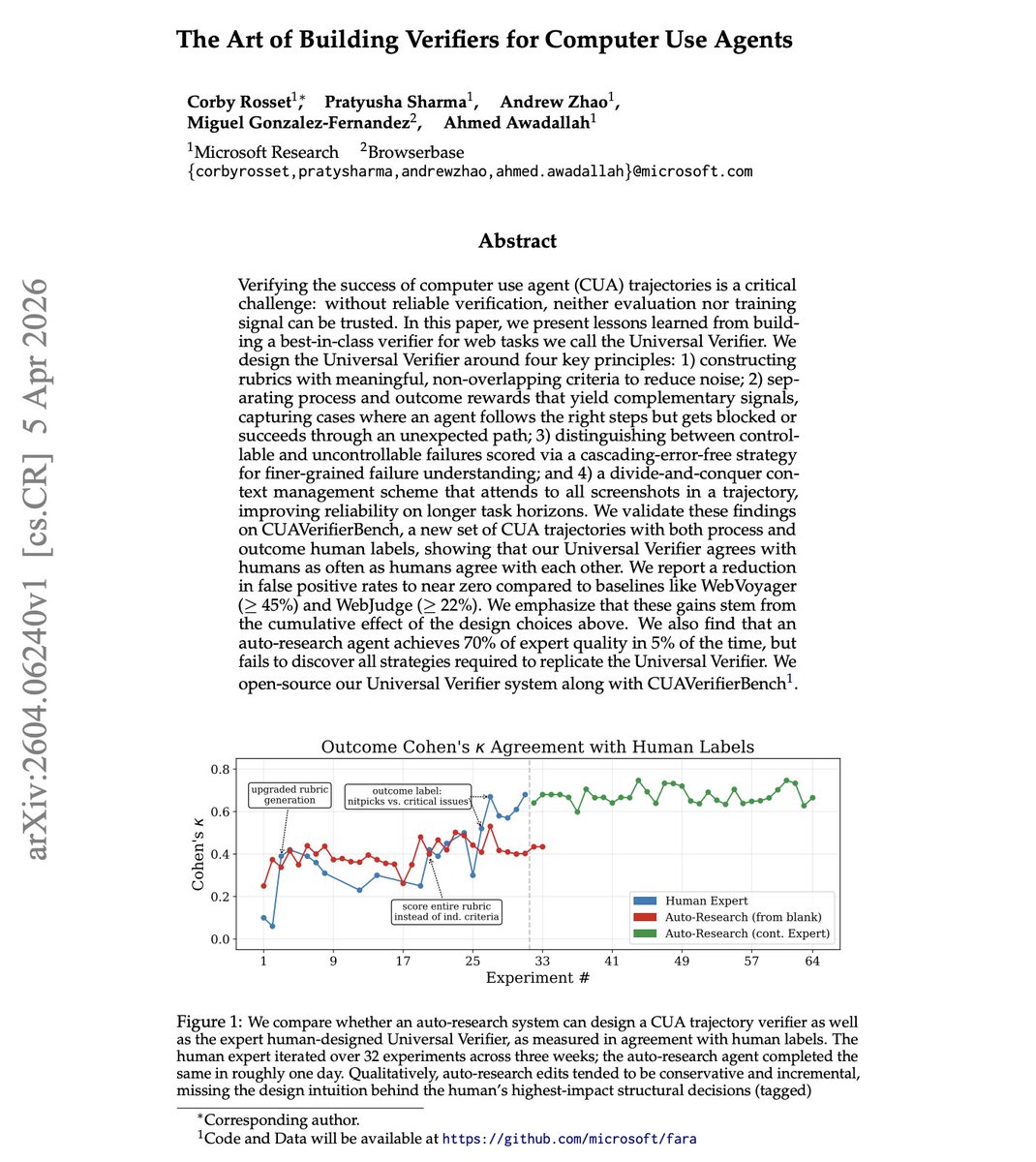
- The Universal Verifier
- Agent Skills in the Wild
- Memory Intelligence Agent (MIA)
- Single-Agent vs Multi-Agent LLMs
- Scaling Coding Agents via Atomic Skills
Read on for more:
DAIR.AI@dair_ai
English