Sabitlenmiş Tweet
Plugyawn
1.6K posts


Plugyawn
@plugyawn
writing as a rehearsal of language. language as a rehearsal of logic.
bridges Katılım Ekim 2022
575 Takip Edilen273 Takipçiler
Plugyawn retweetledi

currently reviewing three papers, they add extra params, add entire extra models, etc, and none of them even mention the word 'flops'
we're comparing apples to bananas here
English
14K H200 hours is... a lot for a 30 step gain in an unsaturated nanogpt run...?
elie@eliebakouch
we let opus 4.7 and gpt 5.5 run on the nanogpt optimizer speedrun: ~10k runs, 14k H200 hours, 23.9B tokens. opus hits 2930, codex 2950, both beating the human baseline of 2990. we cover claude autonomy failures, codex high compute usage, and much more primeintellect.ai/auto-nanogpt
English
I might be very off, but I think we should be able to show that the power of a single-stream is the same as multi-stream (considering the difference could be roughly simulated by changing only the position embeddings on single-stream?) and because systems-wise, it's just simpler to keep things single-stream. Plus, then it doesn't raise the weird question of "how many streams is optimal?".
"we're training models wrong" sounds a bit disingenuous coming from an academic setting, i don't know.
Jonas Geiping@jonasgeiping
We’re training models wrong and it’s due to chatGPT. Even the modern coding agents used daily still use message-based exchanges: They send messages to users, to themselves (CoT) and to tools, and receive messages in turn. This bottlenecks even very intelligent agents to a single stream. The models cannot read while writing, cannot act while thinking and cannot think while processing information. In our new paper, see below, we discuss LLMs with parallel streams. We show that multi-stream LLMs can … 🔵Be created by instruction-tuning for the stream format 🔵Simplify user and tool use UX removing many pain points with agents and chat models (such as having to interrupt the model to get a word in) 🔵Multi-Stream LLMs are fast, they can predict+read tokens in all streams in parallel in each forward pass, improving latency 🔵 LLMs with multiple streams have an easier time encoding a separation of concerns, improving security 🔵 LLMs with many internal streams provide a legible form of parallel/cont. reasoning. Even if the main CoT stream is accidentally pressured or too focused on a particular task to voice concerns, other internal streams can subvocalize concerns that would otherwise not be verbalized. Does this sound related to a recent thinky post :) - Yes, but I don’t feel so bad about being outshipped with such a cool report on their side by 23 hours. I’ll link a 2nd thread below with a more direct comparison. I actually think both are complementary in interesting ways.
English
Plugyawn retweetledi

@himganj153 With all due respect, this isn’t even India-based, it’s just a man trying to fool kids into doing data analyst jobs for even less money.
English

I think a lot of non-India-based academics are completely missing the context and point of this tweet, which is very India-specific.
Dr. Manabendra Saharia@m_saharia
Yesterday, I was giving an intro talk to our dept's new PhD students. Technical things aside, my number 1 suggestion has remained the same over the years: Treat your PhD like a job. - Avoid 1.5h lunch and three tea breaks. - Avoid gossiping and loitering at work. - Lab at 9 am and leave at 6 pm. Being productive till 11 pm in the lab is a lie people till themselves when their day starts at 1 PM. Everything worth doing can be done with high intensity focus during work hours. And having fun in life is the secret to being productive in a marathon.
English
So, like, 9 AM to 6 PM so they can do data analysis on rainfall CSVs all day?
Dr. Manabendra Saharia@m_saharia
Yesterday, I was giving an intro talk to our dept's new PhD students. Technical things aside, my number 1 suggestion has remained the same over the years: Treat your PhD like a job. - Avoid 1.5h lunch and three tea breaks. - Avoid gossiping and loitering at work. - Lab at 9 am and leave at 6 pm. Being productive till 11 pm in the lab is a lie people till themselves when their day starts at 1 PM. Everything worth doing can be done with high intensity focus during work hours. And having fun in life is the secret to being productive in a marathon.
English
@soumithchintala @lauriewired There’s a neat case where the interaction model is on-prem and the background model is on the cloud too, right?
English

@lauriewired this model/demo is actually already doing a roundtrip to us-east-1 (from SF).
English

you know, if you aren’t accounting for network latency, these numbers mean nothing.
i’m not saying this is the case…but “model running locally in the same room” tends to be a heck of a lot faster than “round trip to us-east-1 and back”
swyx 🇸🇬 AIE Singapore!@swyx
I believe the kids call this "@thinkymachines just brutally framemogged gdm and oai". basically everyone's definition of "realtime" just got a massive frciking upgrade
English
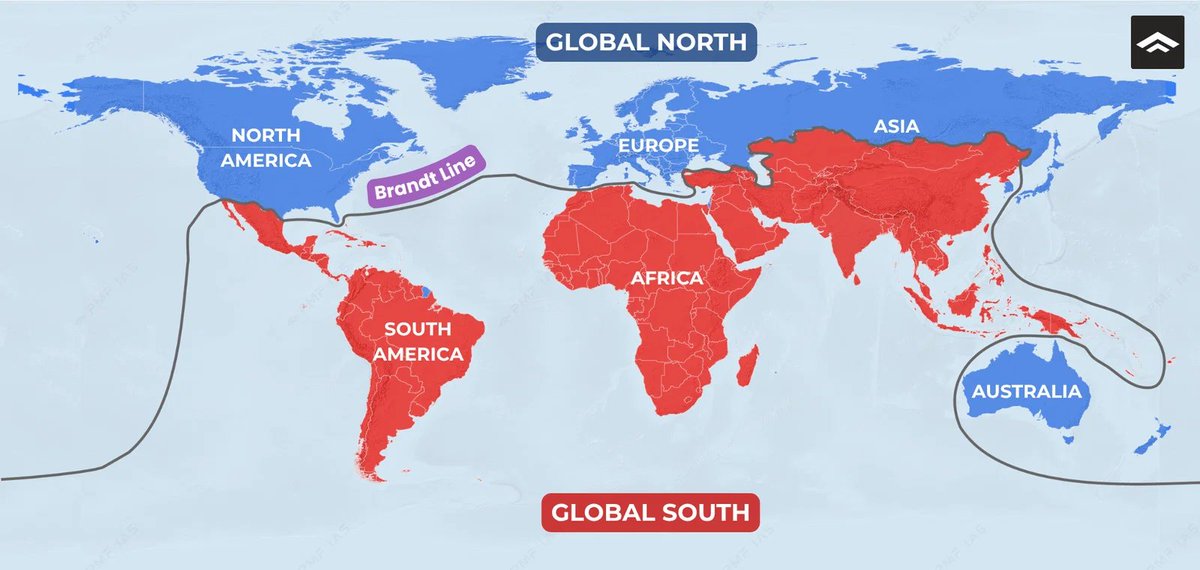
@reddit_lies Retarded take if you include Europe, Australia and exclude India and swathes of China? This makes me question many more of your takes?
English

He doesn't realize it, but he's talking about the Global South.
Conspiratorial Templates@mynamehear
The South is amazing. Imagine making absolutely zero progress in basically any area for 160 years. That's almost a talent.
English
Plugyawn retweetledi

We’re excited to introduce KAME: Tandem Architecture for Enhancing Knowledge in Real-Time Speech-to-Speech Conversational AI, accepted at #ICASSP2026! 🐢
Blog pub.sakana.ai/kame/
Paper arxiv.org/abs/2510.02327
Can a speech AI think deeply without pausing to process?
In real conversation, we don’t wait until we’ve fully worked out what we want to say—we start talking, and our thoughts catch up as the sentence unfolds.
Fast speech-to-speech models achieve this, but their reasoning tends to stay shallow. Cascaded pipelines that route through a knowledgeable LLM are smarter, but the added latency breaks the flow—they fall back to "think, then speak."
In our new paper, we propose a way to break this trade-off. We call it KAME (Turtle in Japanese).
A speech-to-speech model handles the fast response loop and starts replying immediately. In parallel, a backend LLM runs asynchronously, generating response candidates that are continuously injected as "oracle" signals in real time.
This shifts the AI paradigm from "think, then speak" to "speak while thinking."
The backend LLM is completely swappable. You can plug in GPT-4.1, Claude Opus, or Gemini 2.5 Flash depending on the task without changing the frontend. In our experiments, Claude tended to score higher on reasoning, while GPT did better on humanities questions.
Try the model yourself here: huggingface.co/SakanaAI/kame
English

Plugyawn retweetledi

If I was @Lin_Manuel I’d feel an urge to do a certain thing
Daniel Green@dgrreen
The Sam Altman and @miramurati texts from the day he got fired from @OpenAI in 2023 just became evidence in the @elonmusk v. @sama trial. It felt like a meaningful moment in AI history, so I turned it into a musical. The lyrics are the texts.
English
Plugyawn retweetledi

The human brain🧠 is incredibly efficient because it only activates the specific neurons needed for a thought. Modern LLMs naturally try to do this too (> 95% of neurons in feedforward layers stay silent for any given word), but our hardware punishes them for it.
One of the most frustrating paradoxes in deep learning: making a model do less math often makes it run slower. Why? Because unstructured sparsity introduces irregular memory access, and GPUs are built for predictable, dense blocks of math.
We teamed up with @NVIDIA to try to fix this hardware mismatch. Instead of forcing the GPU to adapt to the sparsity, we built a "Hybrid" format that reshapes the sparsity to fit the GPU. Our sparsity format (TwELL) dynamically routes the 99% of highly sparse tokens through a fast path, and uses a dense backup matrix as a safety valve for the rare, heavy tokens.
Through TwELL and a new set of custom CUDA kernels for both LLM inference and training, we translated theoretical sparsity into actual wall-clock speedups: >20% faster training and inference on H100 GPUs, while also cutting energy consumption and memory requirements.
Paper: arxiv.org/abs/2603.23198
Blog: pub.sakana.ai/sparser-faster…
Code: github.com/SakanaAI/spars…
⚡️

Sakana AI@SakanaAILabs
How do we make LLMs faster and lighter? Don’t force the GPU to adapt to sparsity. Reshape the sparsity to fit the GPU! ⚡️ Excited to share our new #ICML2026 paper in collaboration with @NVIDIA: "Sparser, Faster, Lighter Transformer Language Models". This work introduces new open-source GPU kernels and data formats for faster inference and training of sparse transformer language models: Paper: arxiv.org/abs/2603.23198 Blog: pub.sakana.ai/sparser-faster… Code: github.com/SakanaAI/spars… While LLMs are undoubtedly powerful, they are increasingly expensive to train and deploy, with a large part of this cost coming from their feedforward layers. Yet, an interesting phenomenon occurs inside these layers: For any given token, only a small fraction of the hidden activations actually matter. The rest approximate zero, wasting computation. With ReLU and very mild L1 regularization, this sparsity can exceed 95% with little to no impact on downstream performance. So, can we leverage this sparsity to make LLMs faster? The challenge is hardware. Modern GPUs are optimized for dense matrix multiplications. Traditional sparse formats introduce irregular memory access and overheads that cancel out their theoretical savings for GEMM operations. Our contribution is twofold: 1/ We introduce TwELL (Tile-wise ELLPACK), a new sparse packing format designed to integrate directly in the same optimized tiled matmul kernels without disrupting execution. 2/ We develop custom CUDA kernels that fuse multiple sparse matmuls to maximize throughput and compress TwELL to a hybrid representation that minimizes activation sizes. We used our kernels to train and benchmark sparse LLMs at billion-parameter scales, demonstrating >20% speedups and even higher savings in peak memory and energy. This work will be presented at #ICML2026. Please check out our blog and technical paper for a deep dive!
English
Alternatively, the Great Learner has become self-aware.
Paras Chopra@paraschopra
Nature has finally discovered autodiff and gradient descent via humans, and is now speedmaxxing towards birthing a new species.
English

Why did xAI hand over a 220,000-GPU cluster to Anthropic?
The technical backdrop to xAI's decision to hand Colossus 1 over to Anthropic in its entirety is more interesting than it appears. xAI deployed more than 220,000 NVIDIA GPUs at its Colossus 1 data center in Memphis. Of these, roughly 150,000 are estimated to be H100s, 50,000 H200s, and 20,000 GB200s. In other words, three different generations of silicon are mixed together inside a single cluster — a "heterogeneous architecture."
For distributed training, however, this configuration is close to a disaster, according to engineers familiar with the setup. In distributed training, 100,000 GPUs must finish a single step simultaneously before the cluster can advance to the next one. Even if the GB200s finish their computation first, the remaining 99,999 chips have to wait for the slower H100s — or for any GPU that has hit a stack-related snag — to catch up. This is known as the straggler effect. The 11% GPU utilization rate (MFU: the share of theoretical FLOPs actually realized) at xAI recently reported by The Information can be read as the numerical fallout of this problem. It stands in stark contrast to the 40%-plus MFU figures achieved by Meta and Google.
The problem runs deeper still. As discussed earlier, NVIDIA's NCCL has traditionally been optimized for a ring topology. It works beautifully at the 1,000–10,000 GPU scale, but once you push into the 100,000-unit range, the latency of data traversing the ring once around becomes punishingly long. GPUs need to churn through computations rapidly to keep MFU high, but while they sit waiting endlessly for data to arrive over the network fabric, more than half of the silicon falls into idle. Google sidestepped this bottleneck with its own custom topology (Google's OCS: Apollo/Palomar), but xAI, by my read, has not yet reached that stage.
Layer Blackwell's (GB200) "power smoothing" issue on top, and the picture comes into focus. According to Zeeshan Patel, formerly in charge of multimodal pre-training at xAI, Blackwell GPUs draw power so aggressively that the chip itself includes a hardware feature for smoothing power delivery. xAI's existing software stack, however, was optimized for Hopper and does not understand the characteristics of the new hardware; when it imposes irregular loads on the chip, the silicon physically destructs — literally melts. That means the modeling stack must be rewritten from scratch, which in turn means scaling is far harder than most of us imagine.
Pulling all of this together points to a single conclusion. xAI judged that training frontier models on Colossus 1 simply was not efficient enough to be worthwhile. It therefore moved its own training workloads wholesale onto Colossus 2, built as a 100% Blackwell homogeneous cluster. Colossus 1, on the other hand — whose mixed architecture is far less crippling for inference, which parallelizes more forgivingly — was leased in its entirety to an Anthropic that desperately needed inference capacity.
Many observers point to what looks like a contradiction: Elon Musk poured enormous capital into building Colossus, only to hand the core asset over to a direct competitor in Anthropic. Others read it as xAI capitulating because it is a "middling frontier lab." But these are surface-level reads.
Look at the numbers and a different picture emerges. xAI today holds roughly 550,000+ GPUs in total (on an H100-equivalent performance basis), and Colossus 1 (220,000 units) accounts for only about 40% of the total available capacity. Colossus 2 — built entirely on Blackwell — is already operational and continuing to expand. Elon kept the all-Blackwell homogeneous cluster (Colossus 2) for himself and leased out the older, mixed-generation Colossus 1. In other words, he handed the pain of rewriting the stack — the MFU-11% debacle — to Anthropic, while keeping his own focus on training the next generation of models.
The real point, then, is this. Elon's objective appears to be positioning ahead of the SpaceXAI IPO at a $1.75 trillion valuation, currently floated for as early as June. The narrative SpaceXAI now needs is that xAI — long the "sore finger" — is not merely a research lab burning cash, but a business with a "neo-cloud" model in the mold of AWS, capable of leasing surplus assets at high yields.
From a cost-of-capital perspective, an "AGI cash incinerator" is far less attractive to investors than a "data-center landlord generating cash."
As noted above, the most important detail of the Colossus 1 lease is that it is for inference, not training. Unlike training, inference requires far less tightly synchronized inter-GPU communication. Even when the chips are heterogeneous, the workload parcels out cleanly across them in parallel. The straggler effect — the chief weakness of a mixed cluster — is essentially neutralized for inference workloads.
Furthermore, with Anthropic occupying all 220,000 GPUs as a single tenant, the network-switch jitter (unanticipated latency) that arises under multi-tenancy disappears. The two sides' technical weaknesses end up complementing each other almost exactly.
One insight follows. As a training cluster mixing H100/H200/GB200, Colossus 1 was an asset that could only deliver an MFU of 11%. The moment it was handed over to a single inference customer, however, that asset transformed into a cash-flow asset rented out at roughly $2.60 per GPU-hour (a weighted average of the lease rates across GPU types). For xAI, what was a "cluster from hell" for training has become a "golden goose" minting $5–6 billion in annual revenue when redeployed for inference. Elon's genius, I would argue, lies not in the model but in this asset-rotation structure.
The weight of that $6 billion becomes clearer when set against xAI's income statement. Annualizing xAI's 1Q26 net loss yields roughly $6 billion in losses per year. The $5–6 billion in annual revenue generated by leasing Colossus 1 to Anthropic, in other words, almost perfectly hedges xAI's loss figure. This single deal effectively pulls xAI to break-even.
Heading into the SpaceXAI IPO, this functions as a core line of financial defense. From a cost-of-capital standpoint, if the image shifts from "research lab burning cash" to "infrastructure tollgate stably printing $6 billion a year," the entire tone of the offering can change.
(May 8, 2026, Mirae Asset Securities)
Jukan@jukan05
What the SpaceX–Anthropic Deal Means Two weeks ago, we published a note laying out what GPT-5.5's release implied. The conclusion was simple: whoever secures compute first, in greater volume, and with greater reliability ultimately takes the win. With OpenAI's 30GW roadmap dwarfing Anthropic's 7–8GW, we closed by arguing that the structural advantage on compute sat with OpenAI. Less than a fortnight later, that conclusion is being tested. On May 6, Anthropic signed a single-tenant lease for the entirety of Colossus 1 with SpaceXAI — the infrastructure subsidiary that consolidates Elon Musk's xAI and SpaceX. The asset carries more than 220,000 GPUs and 300MW of power, and crucially, is scheduled to come online within this month. It served as the capstone of Anthropic's April blitz, which added 13.8GW of cumulative capacity over the span of a single month. On headline numbers alone, OpenAI took more than a year to stack 18GW; Anthropic has put 13.8GW in the ground in thirty days. The takeaways break down into three. First, the compute pecking order has been redrawn again. Anthropic has now swept up the AWS expansion (5GW, with $100B+ in spend commitments over a decade), Google + Broadcom (3.5GW of TPU), Google Cloud (5GW alongside a $40B investment), and now SpaceXAI's Colossus 1 (0.3GW). Cumulative committed capacity, inclusive of pre-April allocations, sits at 14.8GW. This is still only half of OpenAI's 2030 target of 30GW, but the fact that the SpaceX lease will be live inside a month makes "deliverability" a qualitatively different proposition. Second, Elon Musk is the plaintiff in an active lawsuit against OpenAI — and at the same time, the supplier handing 220,000+ GPUs and 300MW of power, in one block, to OpenAI's most formidable competitor. The timing matters: the deal was struck in the middle of the Musk–Altman trial. We read this as a deliberate pincer with OpenAI in the middle. In the courtroom, Musk works to dismantle the moral legitimacy of OpenAI's leadership; in the market, he arms Anthropic to absorb OpenAI's revenue and user base. Third, the structure is financial-engineering perfection — a clean win-win for both sides. xAI can recognize $6B of annual revenue from a single contract, an amount that almost precisely offsets its Q1 2026 annualized net loss of $6B. It also accelerates the cleanup of SpaceXAI's pre-IPO balance sheet, with the entity now being floated at around $1.75T. Anthropic, on the other side, converts roughly $5B of spend into what it expects to be $15B of ARR via the coming inference-revenue surge. (Mirae Asset Securities, May 8, 2026)
English

Plugyawn retweetledi

Guys, stop pestering Mech Interp researchers about causality please! It's this inexplicable obsession with causality that made us lose beautiful sciences like Astrology, Palmistry and Phrenology! 😡
English