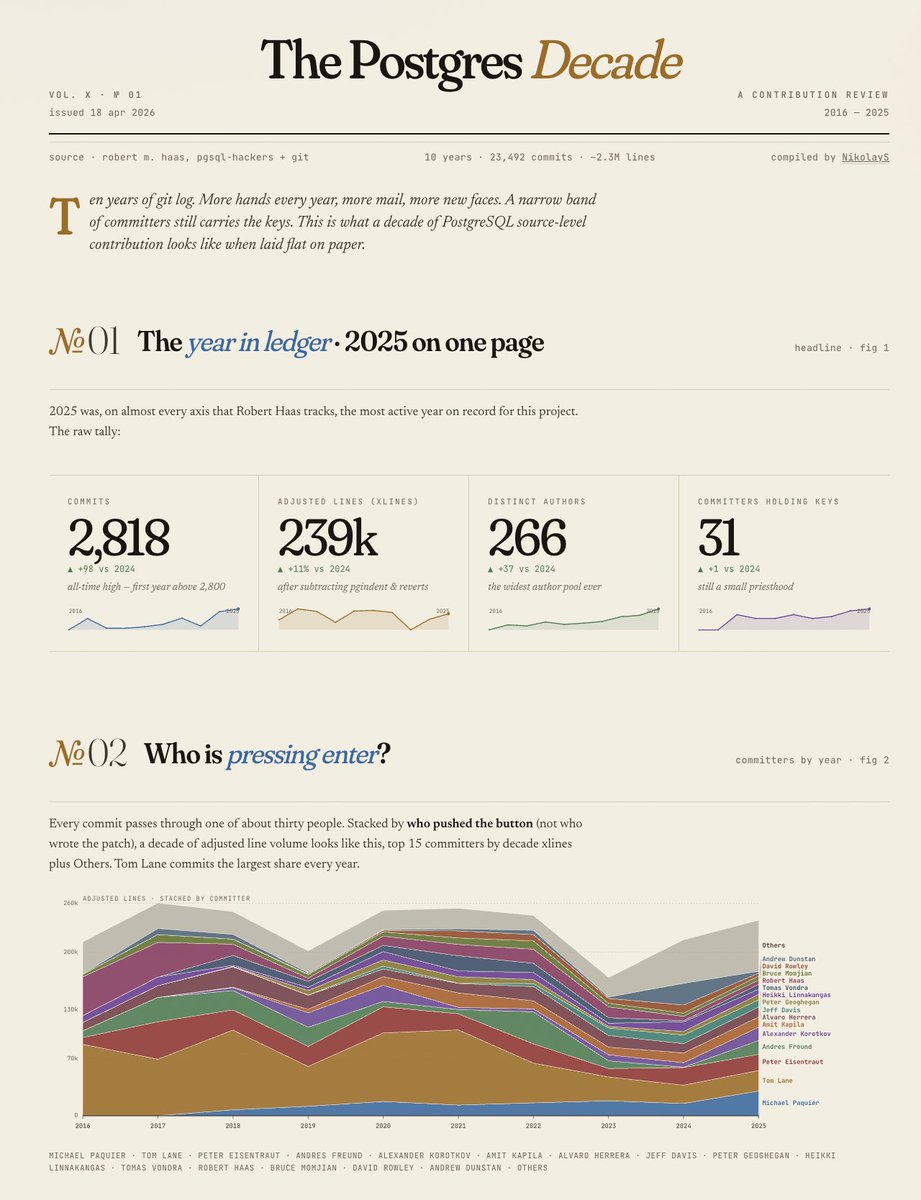
Postgres First retweetledi

FOSS like Postgres killed Oracle's grip on the enterprise.
AI is about to do the same to RDS in the cloud.
Spent an hour today with a customer moving ~100 Postgres clusters off RDS.
Backups and HA aren't the hard part anymore. What's needed is an AI observability + intelligent ops layer -- to keep the fleet healthy at scale, and dev velocity high and safe.
The data layer is repatriating.
English