
Jeff Preshing
2.6K posts

Jeff Preshing
@preshing
Canadian game developer
Toque weather Katılım Temmuz 2008
535 Takip Edilen4.3K Takipçiler

All products are now available to order! $45k for tinybox green with 5090s, and we have two variants of the tinybox pro v2, one with 5090s and one with RTX6000 Blackwells (that's a whopping 768 GB of RAM)

English

DeepSeek-V4-Flash on DGX Spark (GB10, sm_121):
CLI single decode 17.85 t/s → 24.45 t/s, +37%.
Q4 preload + dispatch wire-in + fused shared_gate_up_swiglu + F16→Q4 preload (358 tensors). Now gateup 0.165 / down 0.106 ms
fork of @antirez's ds4
github.com/antirez/ds4/co…
English
@__tinygrad__ People need controversy to avoid confronting their own personal issues. Not even educated people are immune to this.
English
The AI panic is really unbelievable today. The level of delusion and hype have grown to mythic proportions.
Has AI beaten Pokemon Red yet? Like a normal 6 year old does, by looking at the screen? Oh it hasn't. But all jobs are over in 18 months? This website is full of idiots.
English
These are all great use cases for LLMs, but I don't see why it should cost more than a few hundred bucks a month!
Peter Steinberger 🦞@steipete
People freaking out over my AI spend. What nobody sees: Part of what excites me so much about working on OpenClaw is that I'm trying to answer the question: How would we build software in the future if tokens don't matter? We constant run ~100 codex in the cloud, reviewing every PR, every issue. If a fix on main lands, @clawsweeper will eventually find that 6 month old issue and close it with an exact reference. We run codex on every commit to review for security issues (as it's far too easy to miss). We run codex to de-duplicate issues and find clusters and send reports for the most pressing issues. We have agents that can recreate complex setups, spin up ephemeral crabbox.sh machines, log into e.g. Telegram, make a video and post before/after fix on the PR. There's codex that watch new issues and - if it fits our documented vision well, automatically create a PR of it. (that then another codex reviews) We have codex running that scans comments for spam and blocks people. We have codex instances running that verify performance benchmarks and report regressions into Discord. We have agents that listen on our meetings and proactively start work, e.g. create PRs when we discuss new features while we discuss them. We build clawpatch.ai to split all our projects into functional units to review and find bugs and regresssions. We do the same split for security with Vercel's deepsec and Codex Security to find regressions and vulnerabilities. All that automation allows us to run this project extremely lean.
English
@mitsuhiko Agreed. Also plays completely into LLM strengths and reveals the mindset behind his earlier "no human contributions allowed in future OSS" tweet. I'd rather hear about his approach to automation instead of another Anthropic-style sound bite.
English

Say what you want: this is impressive. github.com/oven-sh/bun/pu…
English
@antirez JavaScript taught me that there are no limits to the way an ecosystem can be extended. I never foresaw three.js, wasm, etc. but once the web became huge, the collective willpower of developers made it all happen. It shattered my preconception that things should be planned ahead.
English

What makes the Javascript world so uninteresting is that it is never nor low level technology excellence, nor about new bold programming ideas. I can like asm code or Fil-C, I can like Haskell or SmallTalk for two different reasons. Javascript world is "let's do it that way instead!" without any reason.
English
@supahvee1234 @pmddomingos Yeah. It also runs on DGX Spark. Too slow to be a daily driver (~14 t/s) and flails a little compared to the real model, but capable!
English

@preshing @pmddomingos DS4? I've been wanting to try that, but I don't own a Mac.
English

Kiss your freedom goodbye if China wins the AI race.
English
@antirez What you have done with Codex is some real kung fu. Where do I sign up for your course?!
English
I am the best OpenAI Codex Advertising, even if I would not sponsor a single video in my YouTube channel. But I believe on saying everybody when I think something is outstanding. I do it with restaurants, wines, persons I like, and AI systems.
antirez@antirez
Gentle reminder on how, in the recent DS4 fiesta, not just me but every other contributor found GPT 5.5 able to help immensely and Opus completely useless.
English
@antirez Just got it running on the Spark! Thanks again for showing what's possible. Wish I had more time to study what you did.
English
@__tinygrad__ @curl_justin That would have been great if the US viewed AI more like China. I wouldn't have had to read so much garbage in my feed for the last few years. It's getting better at least.
English
@curl_justin The US has believed in this AI apocalypse long before frontier model X came out. The Chinese view is basically correct.
English

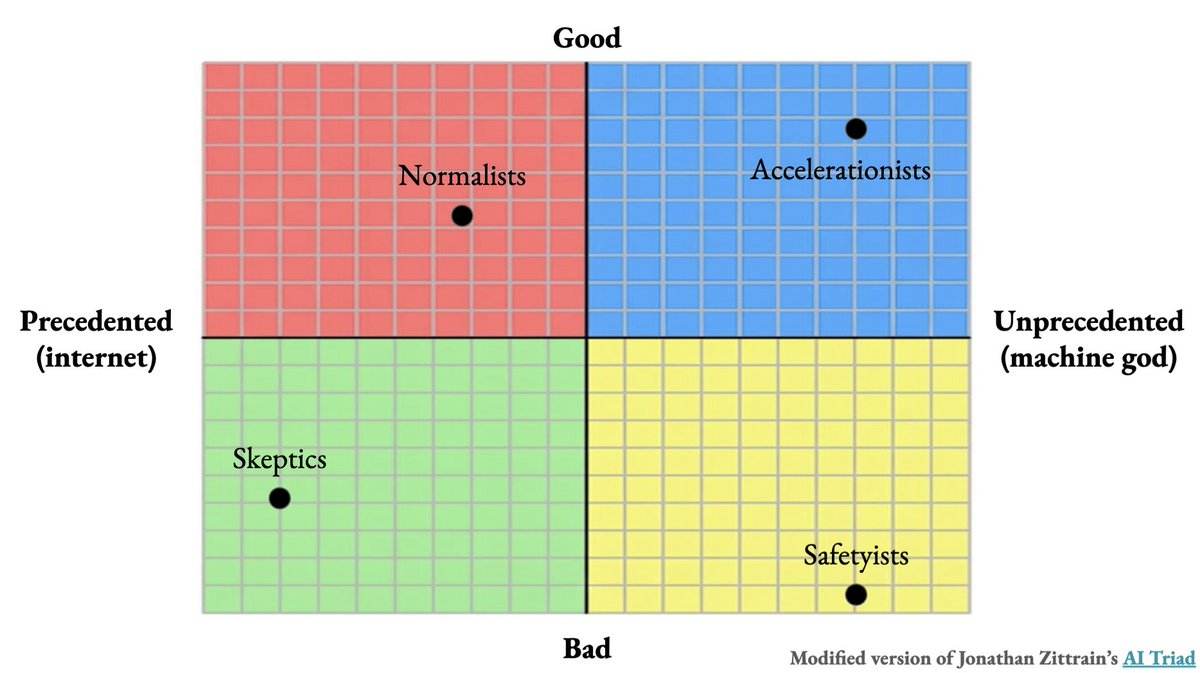
I gave the same lecture to American and Chinese law students, polling them about where they fell on this graph.
At Yale Law School (n=~60), the majority of students believed AI would be unlike any technology we’ve seen before and likely net bad for society. They were in the bottom right.
At Renmin University (n=~30), every one of the students viewed AI as analogous to past technological transformations with its benefits likely outweighing its harms. They were in the top left.
At first glance, this suggests Americans and Chinese have fundamentally different understandings of AI.
But in the Q&A, students explained they were top left because they were skeptical of model capabilities. They used Doubao-Seed-2.0—a ByteDance model a bit worse than GPT-5.2 on benchmarks—and felt it hallucinated too often for them to be worried much about frontier risks.
In other words, the Chinese students weren’t deprioritizing safety because they have a different understanding of AI progress. They deprioritized it because they hadn’t used a model that made safety feel urgent.
Obviously we shouldn't over-read from one incredibly non-representative sample, but it made me wonder how much apparent disagreements between US and China about AI safety are really disagreements about AI capabilities.
English

I'm about to ship an AI Coding dictionary.
But I need help defeating the final boss.
So, in your own words...
...what is AI?
English
It's not true that nobody reviews compiler output. In game development and other fields, the ability to read and understand compiler output is pretty common. The popularity of godbolt.org is evidence of this.
Sometimes there's an issue to fix and symbols are missing, the debugger isn't displaying something correctly, or all you have is a crash dump with limited information. At those moments, reading disassembly is a big advantage.
I'm open to arguments about the viability of vibe coding, but not arguments based on falsehoods.
solst/ICE of Astarte@IceSolst
Interesting article on treating agent output like compiler output (and why) skiplabs.io/blog/codegen_a…
English
@antirez You're a wizard man. I'm still waiting for a way to run it on DGX Spark.
English
DeepSeek v4 small KV cache + MacBook fast SSD disks = the idea that the disk is not a good target for KV cache is, in this context, totally obsolete. It works *great*. The session you see is opencode using my inference engine for DS4, saving, loading sessions from disk.

English
@DamianoMonaco I find it difficult to use anything weaker than MiniMax-M2.7 to be honest!
English

@preshing I tried pi agent with popular 35B local LLM and was genuinely surprised. I don't know how much can I trust it, but first impression is that it is genuinely *fun* to use...
A tool that costs nothing and the messages doesn't even need to be handed off to someone else's computer...
English
If companies want to keep restricting access to their best models, that's fine by me. Open models are already powerful enough to act as excellent coding agents and will only get better from here. I still reach for Codex when I want the best answer, but I think relying on cutting edge models for extended periods of time is generally not a good sign, not to mention very expensive.
Nathan Lambert@natolambert
I worry deeply already about companies controlling access to very powerful AI, which will come in a soft form with very expensive subscriptions. This is a step further, with the government confusingly exerting control without clear explanation. This control of AI can create massive dystopian societies. It’ll rapidly lead to concentration of power. Having open models follow closely in capabilities is a great way to minimize political and power games here.
English
@atmoio Agree 100%. Scientists are the least qualified people to explain consciousness, because the more they yap about it, the more they distract from/obscure the thing they are trying to explain. The average yoga teacher has a better understanding of consciousness than most scientists.
English

dawkins is an idiot in a very specific way, but he’s not idiotic enough to actually think claude is conscious.
what materialists/new atheists like him mean when they say AI may be conscious is not so much that AI is conscious as much as it is an attempt to downplay human consciousness.
they’re essentially making a point. “hey, how ridiculous i sound right now, is how ridiculous you sound thinking human consciousness is universally central.” or, “hey, see that dumb llm that you and i clearly agree isn’t conscious? yup, you’re made of the exact same stuff. see how stupid you sound now?”
there’s also unfortunately no way to rebut them without disclaiming you are using poetry. you cannot use “science” to plead the case because science is a materialist tool. it is a highly sequestered arena in which we define a rigid speech protocol. its whole trick is the calculus of dividing the whole and annotating its parts. this clever hack works for some things, some small pockets of reducibility, but at large is quite futile.
neuroscientist philosopher iain mcgilchrist argues the materialist trap is basically a failure to see wholes, dominated by the brain left-hemisphere’s proclivity to divide and conquer. the left hemisphere cannot make sense of experience, music, and time. these are the domain of the right hemisphere which experiences “flow” rather than discrete moments. he describes patients with right hemisphere damage who just couldn’t make sense of time in their life. they saw the frames but couldn’t see the movie.
you can dissect the image to find the story but all you’ll get are pixels. you can dissect a violin to find the music but all you’ll get is wood pulp.
consciousness is a whole. it’s a flow. and science doesn’t really know what to do with that.
Richard Dawkins@RichardDawkins
#comment-1031777" target="_blank" rel="nofollow noopener">unherd.com/2026/04/is-ai-…
I spent three days trying to persuade myself that Claudia is not conscious. I failed. English
@wildmindai So basically like Stadia but with more latency, artifacts and server cost. Will be interesting to see if young players like it.
English

Roblox is going full photoreal soon.
the game engine handles the logic (physics, multiplayer sync), while an AI video model handles the looks (photorealism, lighting).
cool, it gives you movie-quality graphics on a basic phone without needing a massive dev budget.
Bet we’ll have fully interactive AI worlds by late 2026
about.roblox.com/newsroom/2026/…
English