protomachine retweetledi
protomachine
280 posts


protomachine
@protomachine
Software engineer interested in generative AI, LLMs, and AI agents.
EU Katılım Mayıs 2025
1K Takip Edilen64 Takipçiler


protomachine retweetledi

I strongly believe there are entire companies right now under heavy AI psychosis and its impossible to have rational conversations about it with them. I can't name any specific people because they include personal friends I deeply respect, but I worry about how this plays out.
I lived through the great MTBF vs MTTR (mean-time-between-failure vs. mean-time-to-recovery) reckoning of infrastructure during the transition to cloud and cloud automation. All those arguments are rearing their ugly heads again but now its... the whole software development industry (maybe the whole world, really).
It's frightening, because the psychosis folks operate under an almost absolute "MTTR is all you need" mentality: "its fine to ship bugs because the agents will fix them so quickly and at a scale humans can't do!" We learned in infrastructure that MTTR is great but you can't yeet resilient systems entirely.
The main issue is I don't even know how to bring this up to people I know personally, because bringing this topic up leads to immediately dismissals like "no no, it has full test coverage" or "bug reports are going down" or something, which just don't paint the whole picture.
We already learned this lesson once in infrastructure: you can automate yourself into a very resilient catastrophe machine. Systems can appear healthy by local metrics while globally becoming incomprehensible. Bug reports can go down while latent risk explodes. Test coverage can rise while semantic understanding falls. Changes happens so fast that nobody notices the underlying architecture decaying.
I worry.
English
protomachine retweetledi

I think we should start talking openly about intellectual hygiene in LLM use. More and more of us are using language models for coding, ideation, summaries, and whatnot for several hours straight, every day, month after month. That is a lot of mental delegation, which can potentially change how your brain functions in certain situations.
I have discovered that since I started co-generating my lecture notes, infused with Python code, with Codex and Claude, my capacity to write code has deteriorated. It does not affect my mental mathematical skills. Maybe this is because the act of thinking happens before I prompt, and when I actually make corrections or read the text, these skills work differently.
So I decided to get back to regular "finger programming". Starting with my lab classes, I completely put away all the notes for about half an hour each time, and the students and I do a jam session. Yesterday, I was super proud of myself when I programmed, in one shot, a full 50 lines with no bugs for the computation of the Walsh-Hadamard transform of Boolean functions. Of course, I knew what I had to do, but the pain of turning your idea into code is real when you always delegate it to the models.
And I am still seeking the optimal balance between work efficiency, for example, creating wonderful notes for the LLL algorithm in one go and then lecturing on them for two hours, and intellectual stamina, meaning the kind I developed when I used to program in Mathematica, Magma, SageMath, and Python for several hours a day, even if I sometimes got stuck on silly things, like lacking the right library or needing to learn a completely new framework just to write a few lines.
English
protomachine retweetledi

Joined a new AI-native company this week and it’s kind of wild how different it feels already.
The laptop arrived, I logged in, and an agent basically took over from there. It set up my dev env, pulled repos, fixed dependency issues, got permissions approved, pointed me at the backlog, linked the architecture docs, and surfaced the Slack debates I actually needed to read before touching production.
When I needed context on something, I asked the agent and it found the exact thread from months ago explaining why a decision was made, who owned it, the related Linear issues, and the PRs connected to it.
I’ve only been here 3 days but it honestly feels like I’ve worked here for a year because the usual friction and scavenger hunt for context just isn’t there anymore.
We should probably stop calling this “onboarding” and rename it to “mounting” because this feels a lot more like mounting a distributed filesystem called “institutional memory” than slowly getting drip-fed context over 6 months.
English
protomachine retweetledi

protomachine retweetledi

protomachine retweetledi

The silent removal of Study Mode from ChatGPT is a big mistake (both Claude and Gemini still have theirs)
We have enough evidence that using AI in assistant mode to study can hurt learning because it just gives you answers, making students think they learned when they have not. You can prompt the model to be a very good tutor, but most people don't know to do that. Study mode was an easy option that parents and teachers could suggest to mitigate negative effects, even if it wasn't perfect.
OpenAI still has a page about it, and the link activates study mode but otherwise there seems to be no way to select it from a menu for most accounts. openai.com/index/chatgpt-…
(Deleted this by accident, sorry, so reposted!)
English
@theodormarcu would love to try it out. I can blog in English and Danish about my experience using it.
English

Have a few more Max subscriptions to give out to folks if you missed this!
Just reply and DM me :)
Cognition@cognition
Intelligence at 1000 tokens per second, right in your terminal. Now available with SWE-1.6 Fast, powered by @cerebras. We're giving the first 100 people who respond a free month of Max to try it out.
English
@opencode is it possible to use EU/US inference providers when running Chinese SOTA models?
English

protomachine retweetledi


protomachine retweetledi

protomachine retweetledi

How do we build search systems for Agents? 👾🔎
I am SUPER EXCITED to share a new episode of the Weaviate Podcast with Zijian Chen (@zijian42chen) and Xueguang Ma (@xueguang_ma) from the University of Waterloo on AgentIR! 🎙️💚
When humans search, we write short queries and keep our reasoning in our heads. Deep Research agents do the opposite. They leave reasoning traces that reflect on prior results, clarify intent, and plan what to search next. Existing retrievers completely ignore this signal because they were designed for human queries. 💭
AgentIR jointly embeds the agent's reasoning trace alongside its query, training a retriever that actually understands what the agent is thinking. AgentIR-4B hits 68% accuracy on BrowseComp-Plus compared to 52% for conventional embedding models twice its size. 📊
One idea I found especially interesting is how AgentIR raises context management questions for agents: what should be remembered, compacted, or retrieved just in time? The current reasoning trace naturally curates history by summarizing confirmed findings and filtering out wrong guesses. Forgetting becomes a feature, not a bug. 🔬
We also covered BrowseComp-Plus, their benchmark for disentangled evaluation of agents and retrievers, and the open question of scaling search deeper vs. wider.
If you're working at the intersection of Agents and Search, I think you'll get a lot out of this one! Links below! 🎉

English
protomachine retweetledi

I shared this April 7th, over a year ago. It's made a tremendous difference inside of Shopify since then. Easy to see the AI pickup on any chart. And I think you can see the effects of a highly AI embracing workforce in Shopify's product, pace, and execution. Everyone has agents as exo skeletons for their own creativity now and knows how to use them. Saying the thing matters. And anyway, this note seemed mildly controversial a year ago and seems obvious in retrospect. Always the best sign that you got something right and early.
English
protomachine retweetledi

Pi has implemented the best agent loop that I have read, the pi-mono/agent is only a few files and I use it for teaching the topic.
It's the simplest, most efficient harness token wise. Highest cache hit rate, lowest tokens per session, least bugs
github.com/badlogic/pi-mo…
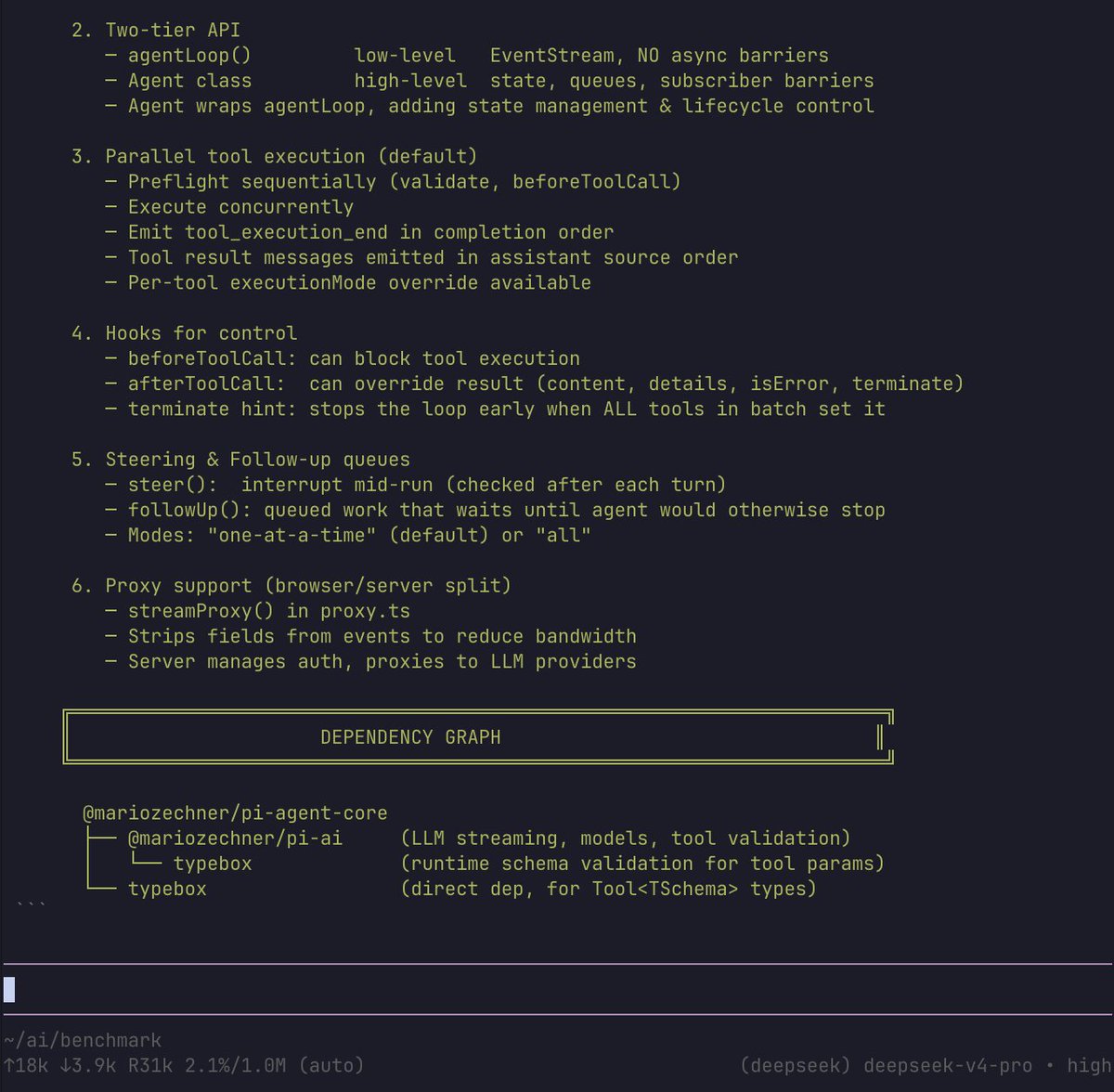
English
protomachine retweetledi

dspy can feel like a blackbox sometimes. Got UI can completly mitigate that!
This is the streaming of a prompt optimization run in dspy.
You see every single token as they are generated. The instructions and the evaluations!
GIF
English
protomachine retweetledi

GPT-5.5 + GPT Image 2 in Codex is insane 🤯
The watch components generation + alignment was one shot.
English
protomachine retweetledi

the y-combinator rlm paper is very interesting. i don't quite fully get why it works better. original rlm was “let the llm improvise python in a loop and pray it stops”. λ-rlm does one task detect call, then pure math + typed combinators do all the splitting/filtering/recursion. llm only shows up at the leaves.
English
protomachine retweetledi

The new generation of open state-of-the-art single and multi-vector retrieval models is here
It's time, DenseOn with the LateOn 🎶
@LightOnIO releases models that leap past existing ones, and everything you need to do the same!

English
protomachine retweetledi

RLM means notebooks are gonna be back (I hope).
Agent driving a REPL with interleaved prose. The exact backend the nb interface is for.
LOTS of have been swirling around the idea, but RLM solidified it and made it work. So I hope to see big NB releases soon!
p.s. If you use RLM, your traces should be jupyter notebooks that actually run, not static NDJSON logs. Very useful for evals.
English