Patrick Lim retweetledi

Boston just got completely shut out of the 2026 James Beard Award nominees.
Not a single restaurant or chef from Massachusetts made the list.
The last time we had a major category win was in 2019.
Speaks volumes on the current state of Boston's restaurant scene this decade.
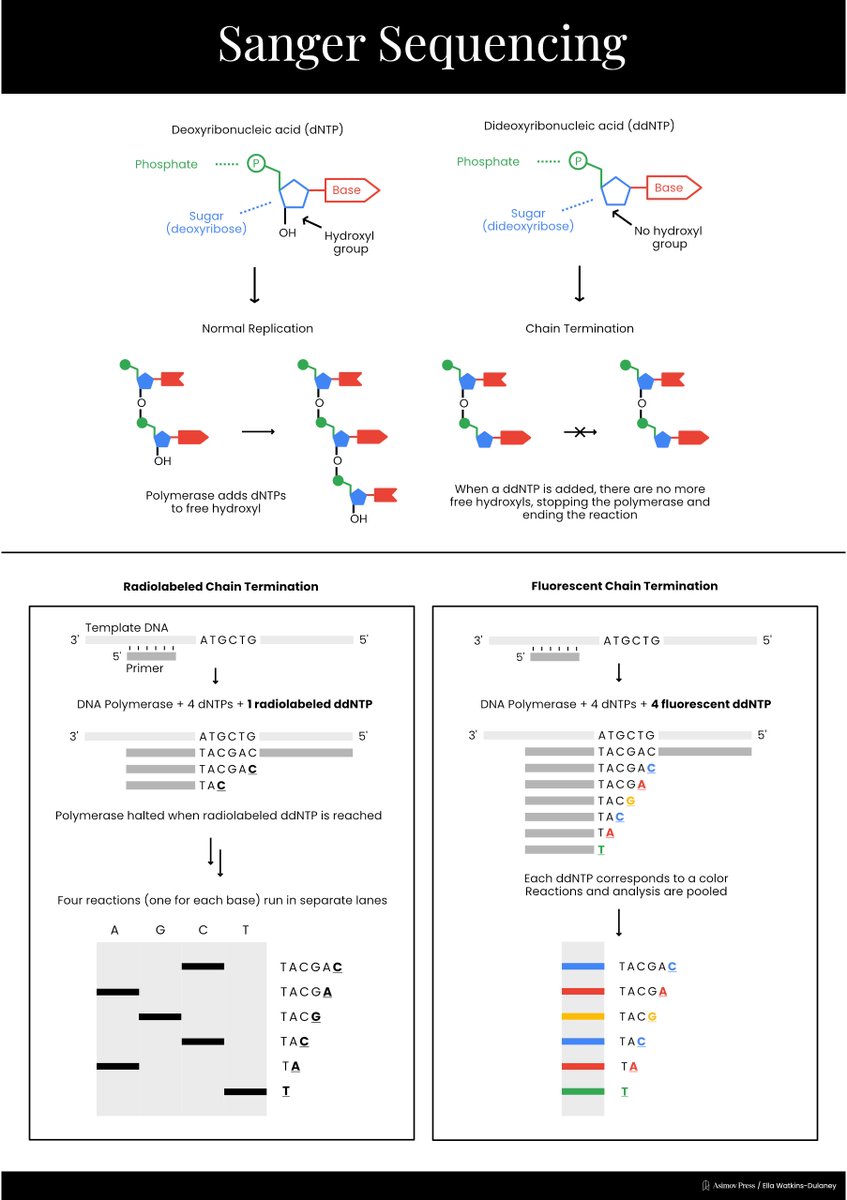
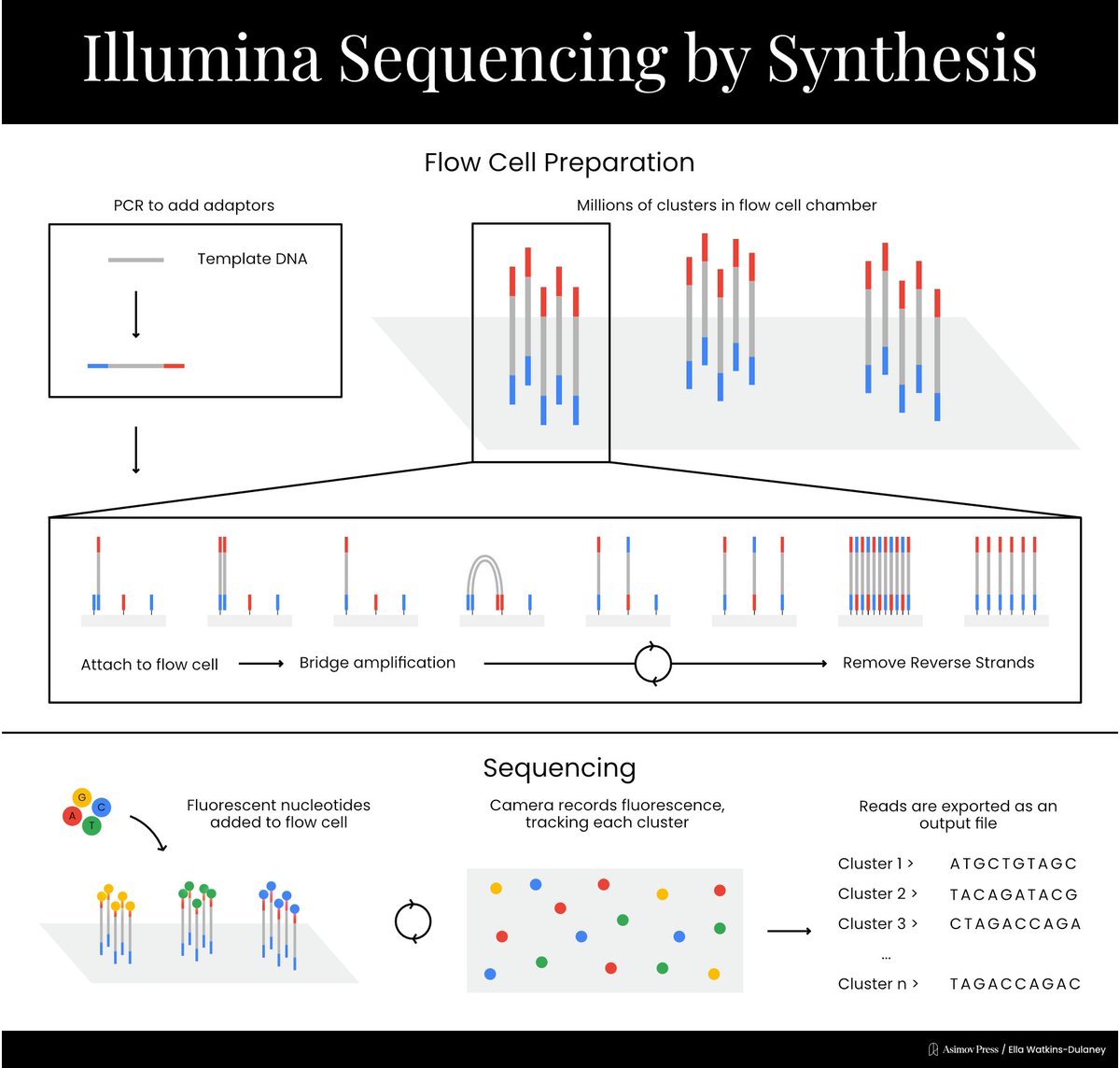
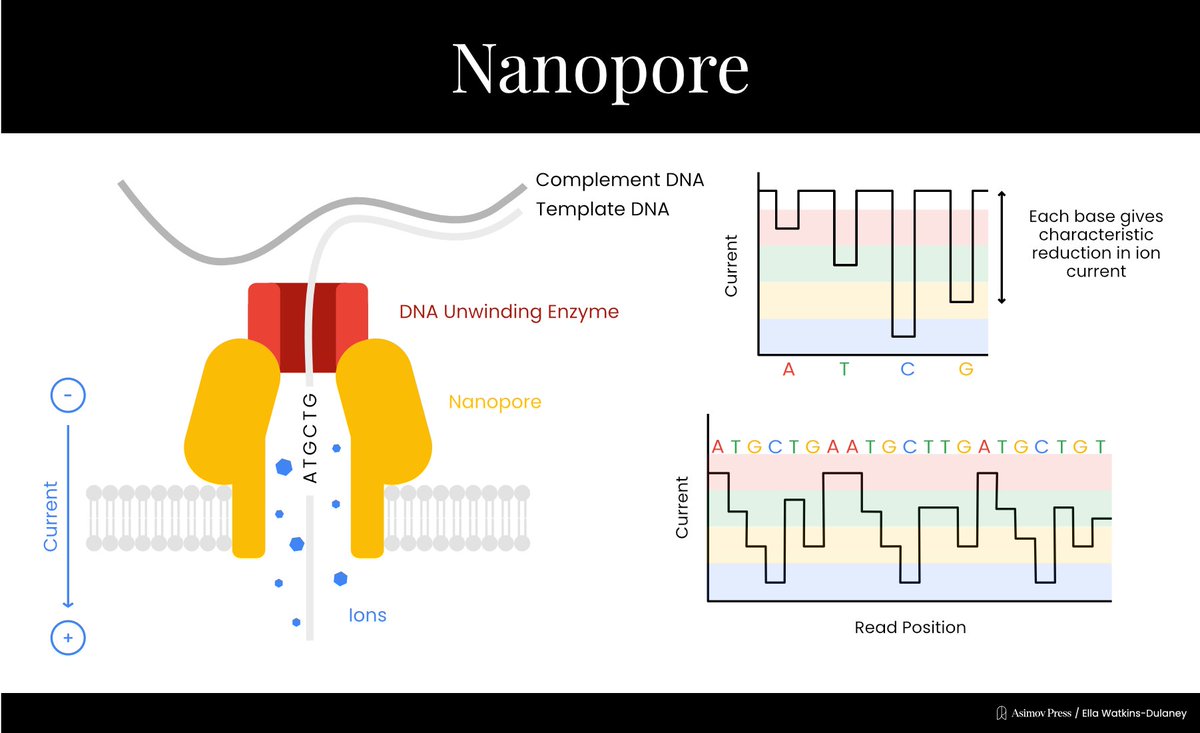
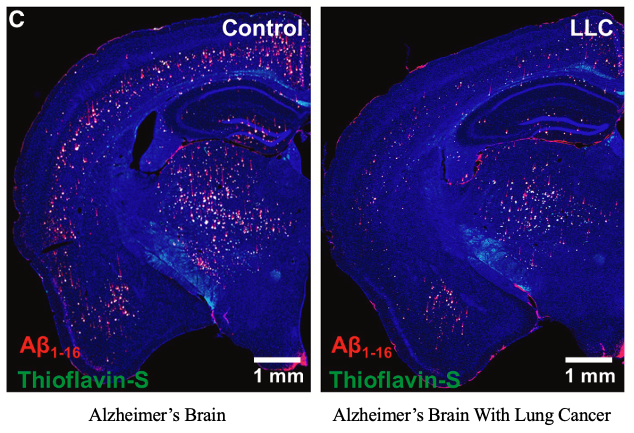
English